 input
inputThe default look of WordPress archives. Appearance of WordPress archives by default Php script for archiving files
When you need to quickly download the source of a site from the server, even a relatively fast SSH tunnel does not give the desired speed. And they have to wait a very, very long time. And many hosting providers do not provide this access, but make FTP content, which is several times slower.
For myself, I determined the way out. A small script is uploaded to the server and launched. After a while, we get the archive with all the sources. And one file, even according to ancient FTP, downloads much faster than a hundred small ones.
Previously on the pages of this blog is the zipArchive library. However, then it was about unpacking the archive.
First, we need to find out if the server supports zipArchive. This is a popular library installed on the vast majority of hosting.
The library is strictly limited by php and server parameters. Huge databases and photo banks cannot be archived. Even the base of the good old 1C program for accounting. It would seem that they should contain only textual data. But no.
I advise you to use the library only when archiving relatively small sites, with a huge number of small files.
Check if the library is available
If (! Extension_loaded ("zip")) (return false;)
If all is well, the script will continue to execute further.
A small offtopic for such checks. Checks should be done that way, avoiding large constructions with nested brackets. So the code will be more atomic, and it will be easy to debug. Compare
If (a \u003d\u003d b) (if (c \u003d\u003d d) (if (e \u003d\u003d f) (echo "All conditions worked";) else echo "e<>f ";) else echo" c<>d ";) else echo" a<>b;
and such a code
If (a! \u003d B) exit ("a<>b); if (c! \u003d d) exit ("c<>d) if (e! \u003d f) exit ("e<>f) echo "All conditions worked";
The code is nicer and does not grow into huge nested constructions.
Sorry for the offtopic, but I wanted to share this find.
Now create an object and an archive.
$ zip \u003d new ZipArchive (); if (! $ zip-\u003e open ($ destination, ZIPARCHIVE :: CREATE)) (return false;)
where $ destination is the full path to the archive. If the archive has already been created, the files will be added to it.
$ zip-\u003e addEmptyDir (str_replace ($ source. "/", "", $ file. "/"));
where $ source is the full path to our category (which we originally archived), $ file is the full path to the current folder. This is done so that the archive does not have full paths, but only relative ones.
Adding a file works in a similar way, but you must first read it into a line.
$ zip-\u003e addFromString (str_replace ($ source. "/", "", $ file), file_get_contents ($ file));
At the end, you need to close the archive.
Return $ zip-\u003e close ();
How to run through all the files and subdirectories in the folder, I think no need to explain. Google something like Recursive folder traversal in php
I came up with this option
Function Zip ($ source, $ destination) (if (! Extension_loaded ("zip") ||! File_exists ($ source)) (return false;) $ zip \u003d new ZipArchive (); if (! $ Zip-\u003e open ( $ destination, ZIPARCHIVE :: CREATE)) (return false;) $ source \u003d str_replace ("\\\\", "/", realpath ($ source)); if (is_dir ($ source) \u003d\u003d\u003d true) ($ files \u003d new RecursiveIteratorIterator (new RecursiveDirectoryIterator ($ source), RecursiveIteratorIterator :: SELF_FIRST); foreach ($ files as $ file) ($ file \u003d str_replace ("\\\\", "/", $ file); // Ignore "." and ".." folders if (in_array (substr ($ file, strrpos ($ file, "/") + 1), array (".", ".."))) continue; $ file \u003d realpath ($ file ); $ file \u003d str_replace ("\\\\", "/", $ file); if (is_dir ($ file) \u003d\u003d\u003d true) ($ zip-\u003e addEmptyDir (str_replace ($ source. "/", "" , $ file. "/"));) else if (is_file ($ file) \u003d\u003d\u003d true) ($ zip-\u003e addFromString (str_replace ($ source. "/", "", $ file), file_get_contents ($ file));))) else if (is_file ($ source) \u003d\u003d\u003d true) ($ zip-\u003e addFromString (basename ($ source), file_get_contents ($ source));) return $ zip-\u003e close (); )
It’s clear that it’s easier for the creators of the templates to display the standard views of all pages of the site using the standard functions and tags of the WordPress templates, but this creates a uniform appearance and a feeling of transition to the same pages of the site.
Immediately show what we get as a result.
Type of wordpress archives: archive of categories before change  Archive of rubrics with removed thumbnails and a link in more detail.
Archive of rubrics with removed thumbnails and a link in more detail.
Important! Since this problem is solved by changing the template code, we do it before work (database + site files). In addition, we make two copies of the working template, one for editing, the second for restoring incorrect editing.
Change the look of WordPress archives
in order to change appearance WordPress archives, you need to find, or rather, determine which file in your working template displays archives. In most templates, all archives are displayed in a single file, it is called (archive.php).
I repeat, for security, lose the site, we do not use the editor in the administrative panel of the site, but we correct the pre-made backups template files.
AT text editor (like Notepad ++), open the archive.php file and start editing. In the archive.php file (at the end of the file) we look for a function that displays the archive blog:
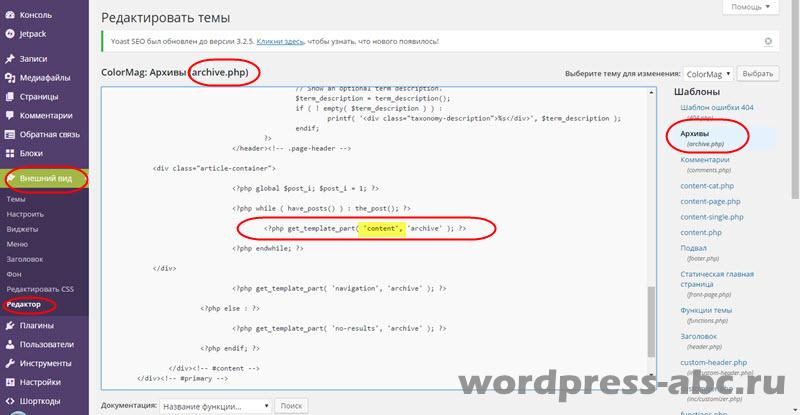
Name is the name of the file that is used to display the archives blog.
The first idea of \u200b\u200bcompleting a task is simple.: we need to change the code of the file that displays the archives (content.php), namely, remove several functions in it, and thereby change the appearance of all site archives (headings, authors, dates, etc.).
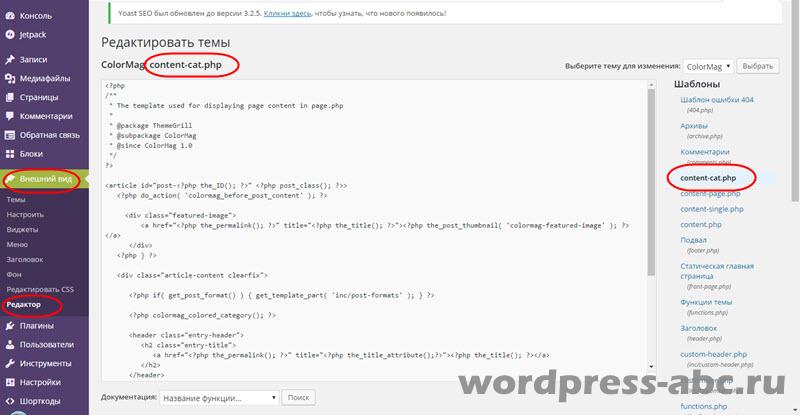
But the question arises, if we change the code of the template file, it will return to its previous state after the first update of the template, we do not need it. Therefore, we will not edit the content.php file, but copy it and create our own file, under a different name, for example content-cat.php and edit it.
We are looking for a function in the file that displays thumbnails. The thumbnail output function will be at the top. We remove the output of the thumbnail.

or and remove the line with ‘Read More’, ‘template name’.

The created and edited content-cat.php file is saved and poured into the site directory in the working template folder. This file will appear in the admin panel of the site on the Appearance → Editor tab.
We pass to the second step. In the file that displays the archives (archive.php), change the name of the content file to content-cat.
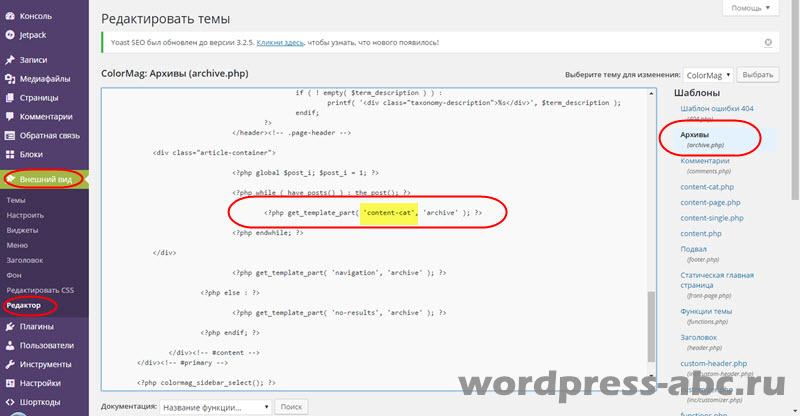
Save and watch the result. If something is wrong, the system will display an error, an error file, and an error line. To fix errors saved backup files We return the template to the place and repeat everything again.
Tip. If you want to read more about template tags and standard WordPress features, check out this site: https://wp-kama.ru. This is not an advertisement or even a link, this site is more understandable than the official WordPress site in the template tags and functions section.
In development of the topic
In my opinion, the theme of announcements on WordPress sites needs to be continued. In the next posts, I will talk about topics: and.
WordPress Codex
Hidden text
Function the_post_thumbnail
Function
the_post_thumbnail
Appointment
The the_post_thumbnail function outputs html code thumbnail pictures of the post are empty if there is no picture.
Application
This template tag, the_post_thumbnail function, must be used internally.
Using
the_post_thumbnail (string | array $ size \u003d "post-thumbnail", string | array $ attr \u003d "")Source
File: wp-includes / post-thumbnail-template.php
Function the_post_thumbnail ($ size \u003d "post-thumbnail", $ attr \u003d "") (echo get_the_post_thumbnail (, $ size, $ attr);)
Parameters
$ size (string / array)
The size of the thumbnail to get. It can be a string with conditional sizes: thumbnail, medium, large, full or an array of two elements (width and height of the picture): array (60, 60).
Default: ‘Post-thumbnail’, that is, the size that is set for the current topic by the set_post_thumbnail_size () function
$ attr (string / array)
An array of attributes to add to the resulting html img tag (alt is an alternative name).
Default:
Example
_("permalink"), the_title_attribute("echo=0")); ?>"> !}get ("layout", "imgwidth"), $ SMTheme-\u003e get ("layout", "imgheight")), array ("class" \u003d\u003e $ SMTheme-\u003e get ("layout", "imgpos"). " featured_image ")); if (! is_single ()) (?\u003eEach site is a story that has a beginning and an end. But how to trace the stages of the formation of the project, its life cycle? For these purposes, there is a special service called the web archive. In this article we will talk about the presentation of such resources, their use and capabilities.
What is a web archive and why is it needed?
A web archive is a specialized site that is designed to collect information about various Internet resources. The robot saves copies of projects in automatic and manual mode, it all depends on the site and the data collection system.
Currently, there are several dozens of sites with similar mechanics and tasks. Some of them are considered private, others are open to the public non-profit projects. Also, the resources differ from each other by the frequency of visits, the completeness of the information stored and the possibilities of using the received history.
As some experts note, information storage pages are considered an important component of Web 2.0. That is, part of the ideology of the development of the Internet, which is in constant evolution. The collection mechanics are very mediocre, but there are no more advanced methods or analogues. Using a web archive, you can solve several problems: tracking information over time, recovering a lost site, and searching for information.
How to use web archive?

As noted above, a web archive is a site that provides a certain kind of search service in history. To use the project, you must:
- Go to a specialized resource (for example, web.archive.org).
- Enter information for the search in the special field. It can be a domain name or a keyword.
- Get relevant results. This will be one or more sites, each of which has a fixed crawl date.
- By clicking on the date, go to the corresponding resource and use the information for personal purposes.
We will talk about specialized sites for the search for historical fixation of projects later, so stay with us.
Projects providing site history

Today, there are several projects that provide services for finding stored copies. Here are some of them:
- The most popular and sought after by users is web.archive.org. The presented site is considered the oldest on the Internet, the creation dates back to 1996. The service carries out automatic and manual data collection, and all information is placed on huge foreign servers.
- The second most popular site is peeep.us. The resource is very interesting, because it can be used to save a copy of the information stream, which is available only to you. Note that the project works with all domain names and extends the use of web archives. As for the completeness of the information, the presented site does not save pictures and frames. Since 2015, it has also been included in the list of prohibited areas in Russia.
- A similar project described above is archive.is. The differences include the completeness of the collection of information, as well as the ability to save pages from social networks. Therefore, if you have lost a post or interesting information, you can search through the web archive.
Web Archive Options

Now everyone knows what a web archive is, what sites provide services for saving copies of projects. But many still do not understand how to use the information provided. The capabilities of archived data are expressed in the following:
- Choosing a domain name. It's no secret that many webmasters use already uploaded domains. It should be understood that experienced users track not only the target parameters, but also the history of previous use. Each user of the network wants to know what they are gaining: whether there were previous bans or sanctions, whether the project fell under the filters.
- Restoring a site from archives. Sometimes a disaster happens that jeopardizes the existence of your own project. The lack of timely backups in the hosting profile and an accidental error can lead to tragedy. If this happens, do not be upset, because you can use the web archive. We will talk about the recovery process below.
- Search for unique content. Every day on the Internet, sites that are filled with content die. This happens with particular constancy, because of which a huge flow of information is lost. Over time, such pages fall out of the index, and the resourceful webmaster can borrow information on a personal project. Of course, there is a problem with the search, but this is a secondary concern.
We examined the main features that provide web archives, it's time to move on to a more detailed study of individual elements.
Restoring a site from a web archive

No one is immune from problems with sites. Most of them are solved using backups. But what if there is no saved copy on the hosting server? Use the web archive. To do this:
- Go to the specialized resource that we talked about earlier.
- Enter your own domain name in the search bar and open the project in a new window.
- Choose the most successful shot, which is closer to the problem date and has a full view.
- Correct internal direct links. To do this, use the link "http://web.archive.org/web/any_order_id_number_id_/ Site Name".
- Copy lost information or design data that will be applied for recovery.
Note that the process is somewhat tedious, given the speed of the archive. Therefore, we recommend that owners of large web resources perform backups more often, which saves time and nerves.
We are looking for unique content for our own site

Some webmasters use an interesting way to get new, useless content. Every day, hundreds of sites go into oblivion, and with them information is lost. To become the owner of the content, you must do the following:
- Enter URL
https://www.nic.ru/auction/forbuyer/download_list.shtml#buying in the search bar. - At the domain name auction site, download files with the name ru.
- Open the received files using excel and start the selection according to the project information availability parameter.
- Enter the projects found in the list on the web archive search page.
- Open a snapshot and access the information flow.
We recommend that you track content for plagiarism, this will allow you to find really worthy texts. And that’s all! Now everyone knows about the possibilities and methods of using the web archive. Use knowledge wisely and profitably.