 entrada
entradaEl aspecto predeterminado de los archivos de WordPress. Aparición de archivos de WordPress por defecto en script PHP para archivar archivos
Cuando necesita descargar rápidamente la fuente de un sitio desde el servidor, incluso un túnel SSH relativamente rápido no proporciona la velocidad deseada. Y tienen que esperar mucho, mucho tiempo. Y muchos proveedores de alojamiento no proporcionan este acceso, sino que crean contenido FTP, que es varias veces más lento.
Por mí mismo, determiné la salida. Se carga un pequeño script en el servidor y se inicia. Después de un tiempo, obtenemos el archivo con todas las fuentes. Y un archivo, incluso según el antiguo FTP, se descarga mucho más rápido que cien pequeños.
Anteriormente en las páginas de este blog está la biblioteca zipArchive. Sin embargo, se trataba de desempacar el archivo.
Primero, necesitamos averiguar si el servidor admite zipArchive. Esta es una biblioteca popular instalada en la gran mayoría de hosting.
La biblioteca está estrictamente limitada por php y parámetros del servidor. Enormes bases de datos y bancos de fotos no se pueden archivar. Incluso la base del viejo y buen programa 1C para contabilidad. Parece que deberían contener solo datos textuales. Pero no.
Te aconsejo que uses la biblioteca solo cuando archives sitios relativamente pequeños, con una gran cantidad de archivos pequeños.
Comprueba si la biblioteca está disponible
If (! Extension_loaded ("zip")) (return false;)
Si todo está bien, el script continuará ejecutándose más.
Un pequeño tema para tales controles. Las verificaciones deben hacerse de esa manera, evitando grandes construcciones con corchetes anidados. Por lo tanto, el código será más atómico y será fácil de depurar. Comparar
If (a \u003d\u003d b) (if (c \u003d\u003d d) (if (e \u003d\u003d f) (echo "Todas las condiciones trabajadas";) else echo "e<>f ";) más echo" c<>d ";) sino echo" a<>si;
y tal código
Si (a! \u003d B) sale ("a<>si); si (c! \u003d d) sale ("c<>re) si (e! \u003d f) sale ("e<>f) echo "Todas las condiciones trabajadas";
El código es más agradable y no se convierte en grandes construcciones anidadas.
Perdón por el tema, pero quería compartir este hallazgo.
Ahora crea un objeto y un archivo.
$ zip \u003d nuevo ZipArchive (); if (! $ zip-\u003e open ($ destination, ZIPARCHIVE :: CREATE)) (return false;)
donde $ destination es la ruta completa al archivo. Si el archivo ya se ha creado, los archivos se agregarán a él.
$ zip-\u003e addEmptyDir (str_replace ($ source. "/", "", $ file. "/"));
donde $ source es la ruta completa a nuestra categoría (que archivamos originalmente), $ file es la ruta completa a la carpeta actual. Esto se hace para que el archivo no tenga rutas completas, sino solo las relativas.
Agregar un archivo funciona de manera similar, pero primero debe leerlo en una línea.
$ zip-\u003e addFromString (str_replace ($ source. "/", "", $ file), file_get_contents ($ file));
Al final, debe cerrar el archivo.
Regresar $ zip-\u003e close ();
Cómo ejecutar a través de todos los archivos y subdirectorios en la carpeta, creo que no es necesario explicarlo. Google algo así como Recorrido de carpeta recursiva en php
Se me ocurrió esta opción
Función Zip ($ source, $ destination) (if (! Extension_loaded ("zip") ||! File_exists ($ source)) (return false;) $ zip \u003d new ZipArchive (); if (! $ Zip-\u003e open ( $ destination, ZIPARCHIVE :: CREATE)) (return false;) $ source \u003d str_replace ("\\\\", "/", realpath ($ source)); if (is_dir ($ source) \u003d\u003d\u003d true) ($ archivos \u003d new RecursiveIteratorIterator (new RecursiveDirectoryIterator ($ source), RecursiveIteratorIterator :: SELF_FIRST); foreach ($ files as $ file) ($ file \u003d str_replace ("\\\\", "/", $ file); // Ignore "." y ".." carpetas if (in_array (substr ($ file, strrpos ($ file, "/") + 1), array (".", ".."))) continuar; $ file \u003d realpath ($ file ); $ file \u003d str_replace ("\\\\", "/", $ file); if (is_dir ($ file) \u003d\u003d\u003d true) ($ zip-\u003e addEmptyDir (str_replace ($ source. "/", "" , $ file. "/"));) else if (is_file ($ file) \u003d\u003d\u003d true) ($ zip-\u003e addFromString (str_replace ($ source. "/", "", $ file), file_get_contents ($ file));))) else if (is_file ($ source) \u003d\u003d\u003d true) ($ zip-\u003e addFromString (basename ($ source), file_get_contents ($ source));) return $ zip-\u003e close (); )
Está claro que es más fácil para los creadores de las plantillas mostrar los tipos estándar de todas las páginas del sitio utilizando las funciones y etiquetas estándar de las plantillas de WordPress, pero esto crea una apariencia uniforme y una sensación de transición a las mismas páginas del sitio..
Inmediatamente muestra lo que obtenemos como resultado.
Tipo de archivos de WordPress: archivo de categorías antes del cambio  Archivo de rúbricas con miniaturas eliminadas y un enlace con más detalle.
Archivo de rúbricas con miniaturas eliminadas y un enlace con más detalle.
¡Importante! Dado que este problema se resuelve cambiando el código de la plantilla, lo hacemos antes del trabajo (base de datos + archivos del sitio). Además, hacemos dos copias de la plantilla de trabajo, una para editar, la segunda para restaurar una edición incorrecta.
Cambiar el aspecto de los archivos de WordPress
para cambiar apariencia Archivos de WordPress, necesita encontrar, o más bien, determinar qué archivo en su plantilla de trabajo muestra archivos. En la mayoría de las plantillas, todos los archivos se muestran en un solo archivo, se llama (archive.php).
Repito, por seguridad, pierdo el sitio, no usamos el editor en el panel administrativo del sitio, pero corregimos el pre-hecho copias de seguridad archivos de plantilla
A editor de texto (como Notepad ++), abra el archivo archive.php y comience a editar. En el archivo archive.php (al final del archivo) buscamos una función que muestre el blog de archivo:
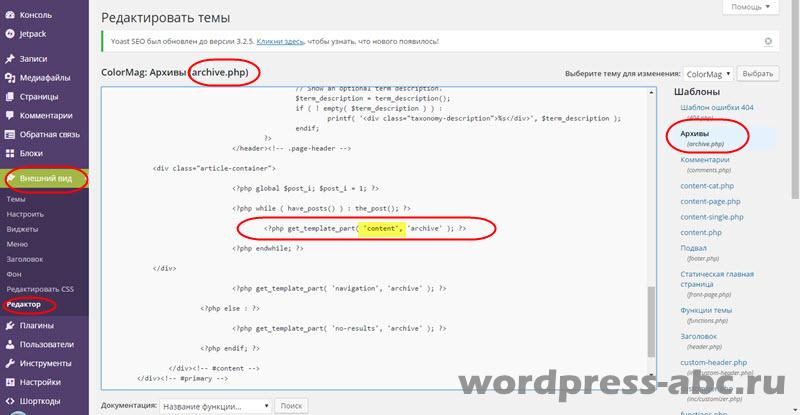
Nombre es el nombre del archivo que se utiliza para mostrar el blog de archivos.
La primera idea para completar la tarea es simple.: necesitamos cambiar el código del archivo que muestra los archivos (content.php), es decir, eliminar varias funciones y, por lo tanto, cambiar la apariencia de todos los archivos del sitio (encabezados, autores, fechas, etc.).
Pero surge la pregunta, si cambiamos el código del archivo de plantilla, volverá a su estado anterior después de la primera actualización de la plantilla, no lo necesitamos. Por lo tanto, no editaremos el archivo content.php, sino que lo copiaremos y crearemos nuestro propio archivo, con un nombre diferente, por ejemplo content-cat.php y lo editaremos.
Estamos buscando una función en el archivo que muestre miniaturas. La función de salida en miniatura estará en la parte superior. Eliminamos la salida de la miniatura.

o y elimine la línea con "Leer más", "nombre de la plantilla".

El archivo content-cat.php creado y editado se guarda y se vierte en el directorio del sitio en la carpeta de la plantilla de trabajo. Este archivo aparecerá en el panel de administración del sitio en la pestaña Apariencia → Editor.
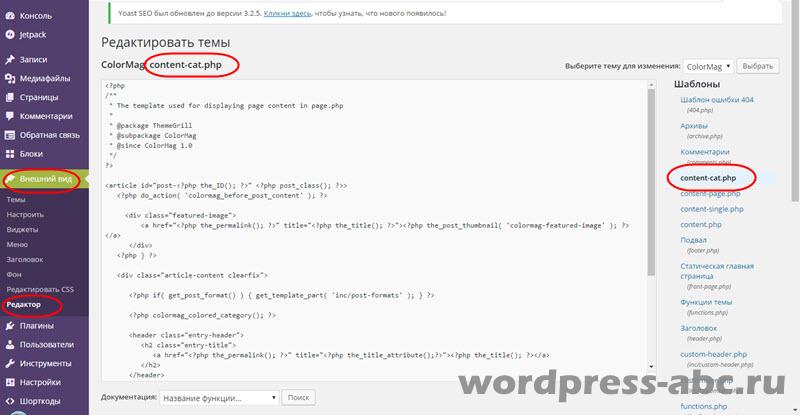
Pasamos al segundo paso. En el archivo que muestra los archivos (archive.php), cambie el nombre del archivo de contenido a content-cat.
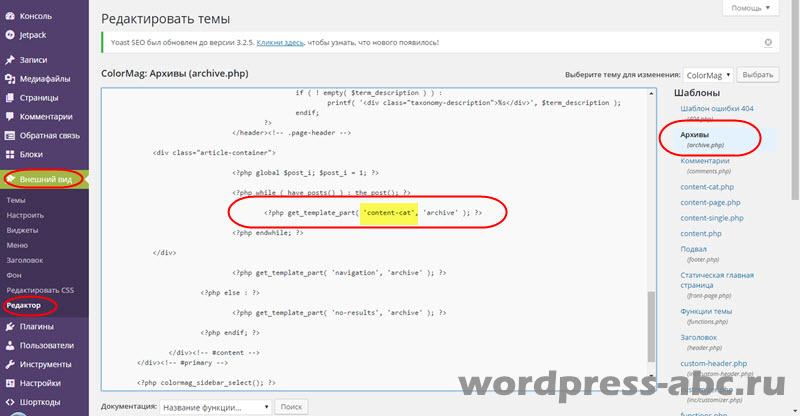
Guarda y mira el resultado. Si algo está mal, el sistema mostrará un error, un archivo de error y una línea de error. Para corregir errores guardados archivos de respaldo Devolvemos la plantilla al lugar y repetimos todo nuevamente.
Propina. Si desea leer más sobre las etiquetas de plantilla y las características estándar de WordPress, consulte este sitio: https://wp-kama.ru. Esto no es un anuncio o incluso un enlace, este sitio es más comprensible que el sitio oficial de WordPress en la sección de etiquetas y funciones de plantilla.
En desarrollo del tema
En mi opinión, el tema de los anuncios en los sitios de WordPress debe continuar. En las próximas publicaciones, hablaré sobre temas: y.
WordPress Codex
Texto oculto
Función the_post_thumbnail
Función
the_post_thumbnail
Cita
La función the_post_thumbnail genera código HTML las imágenes en miniatura de la publicación están vacías si no hay imagen.
Solicitud
Esta etiqueta de plantilla, la función_post_thumbnail, debe usarse internamente.
Utilizando
the_post_thumbnail (string | array $ size \u003d "post-thumbnail", string | array $ attr \u003d "")Fuente
Expediente: wp-includes / post-thumbnail-template.php
Función the_post_thumbnail ($ size \u003d "post-thumbnail", $ attr \u003d "") (echo get_the_post_thumbnail (nulo, $ size, $ attr);)
Parámetros
$ tamaño (cadena / matriz)
El tamaño de la miniatura para obtener. Puede ser una cadena con tamaños condicionales: miniatura, mediana, grande, completa o una matriz de dos elementos (ancho y alto de la imagen): matriz (60, 60).
Defecto: "Post-thumbnail", es decir, el tamaño establecido para el tema actual por la función set_post_thumbnail_size ()
$ attr (cadena / matriz)
Una matriz de atributos para agregar a la etiqueta html img resultante (alt es un nombre alternativo).
Defecto:
Ejemplo
_("permalink"), the_title_attribute("echo=0")); ?>"> !}get ("layout", "imgwidth"), $ SMTheme-\u003e get ("layout", "imgheight")), array ("class" \u003d\u003e $ SMTheme-\u003e get ("layout", "imgpos"). Foto principal ")); if (! is_single ()) (?\u003eCada sitio es una historia que tiene un principio y un final. Pero, ¿cómo rastrear las etapas de la formación del proyecto, su ciclo de vida? Para estos fines, existe un servicio especial llamado archivo web. En este artículo hablaremos sobre la presentación de dichos recursos, su uso y capacidades.
¿Qué es un archivo web y por qué es necesario?
Un archivo web es un sitio especializado que está diseñado para recopilar información sobre diversos recursos de Internet. El robot guarda copias de proyectos en modo automático y manual, todo depende del sitio y del sistema de recopilación de datos.
Actualmente, hay varias docenas de sitios con mecánicas y tareas similares. Algunos de ellos se consideran privados, otros están abiertos a proyectos públicos sin fines de lucro. Además, los recursos difieren entre sí por la frecuencia de las visitas, la integridad de la información almacenada y las posibilidades de utilizar el historial recibido.
Como señalan algunos expertos, las páginas de almacenamiento de información se consideran un componente importante de la Web 2.0. Es decir, parte de la ideología del desarrollo de Internet, que está en constante evolución. La mecánica de recolección es muy mediocre, pero no hay métodos más avanzados o análogos. Usando un archivo web, puede resolver varios problemas: rastrear información a lo largo del tiempo, recuperar un sitio perdido y buscar información.
¿Cómo usar el archivo web?

Como se señaló anteriormente, un archivo web es un sitio que proporciona un cierto tipo de servicio de búsqueda en la historia. Para usar el proyecto, debes:
- Vaya a un recurso especializado (por ejemplo, web.archive.org).
- Ingrese información para la búsqueda en el campo especial. Puede ser un nombre de dominio o una palabra clave.
- Obtén resultados relevantes. Este será uno o más sitios, cada uno de los cuales tiene una fecha de rastreo fija.
- Al hacer clic en la fecha, vaya al recurso correspondiente y use la información para fines personales.
Hablaremos de sitios especializados para la búsqueda de la fijación histórica de proyectos más tarde, así que quédese con nosotros.
Proyectos que proporcionan historia del sitio

Hoy en día, hay varios proyectos que brindan servicios para encontrar copias almacenadas. Éstos son algunos de ellos:
- El más popular y buscado por los usuarios es web.archive.org. El sitio presentado se considera el más antiguo de Internet, la creación se remonta a 1996. El servicio lleva a cabo la recopilación de datos automática y manual, y toda la información se coloca en grandes servidores extranjeros.
- El segundo sitio más popular es peeep.us. El recurso es muy interesante porque puede usarse para guardar una copia del flujo de información, que está disponible solo para usted. Tenga en cuenta que el proyecto funciona con todos los nombres de dominio y extiende el uso de archivos web. En cuanto a la integridad de la información, el sitio presentado no guarda imágenes y marcos. Desde 2015, también se ha incluido en la lista de áreas prohibidas en Rusia.
- Un proyecto similar descrito anteriormente es archive.is. Las diferencias incluyen la integridad de la recopilación de información, así como la capacidad de guardar páginas de las redes sociales. Por lo tanto, si ha perdido una publicación o información interesante, puede buscar en el archivo web.
Opciones de archivo web

Ahora todos saben qué es un archivo web, qué sitios proporcionan servicios para guardar copias de proyectos. Pero muchos todavía no entienden cómo usar la información provista. Las capacidades de los datos archivados se expresan de la siguiente manera:
- Elegir un nombre de dominio. No es ningún secreto que muchos webmasters usan dominios ya cargados. Debe entenderse que los usuarios experimentados rastrean no solo los parámetros objetivo, sino también el historial de uso previo. Cada usuario de la red quiere saber lo que está ganando: si hubo prohibiciones o sanciones previas, si el proyecto cayó bajo los filtros.
- Restaurar un sitio desde archivos. A veces ocurre un desastre que pone en peligro la existencia de su propio proyecto. La falta de copias de seguridad oportunas en el perfil de alojamiento y un error accidental pueden llevar a una tragedia. Si esto sucede, no se moleste, porque puede usar el archivo web. Hablaremos sobre el proceso de recuperación a continuación.
- Busca contenido único. Todos los días en Internet, los sitios que están llenos de contenido mueren. Esto sucede con una constancia particular, por lo que se pierde un gran flujo de información. Con el tiempo, dichas páginas quedan fuera del índice, y el ingenioso webmaster puede pedir prestada información sobre un proyecto personal. Por supuesto, hay un problema con la búsqueda, pero esta es una preocupación secundaria.
Examinamos las características principales que proporcionan archivos web, es hora de pasar a un estudio más detallado de elementos individuales.
Restaurar un sitio desde un archivo web

Nadie es inmune a los problemas con los sitios. La mayoría de ellos se resuelven mediante copias de seguridad. Pero, ¿qué pasa si no hay una copia guardada en el servidor de alojamiento? Utiliza el archivo web. Para hacer esto:
- Vaya al recurso especializado del que hablamos anteriormente.
- Ingrese su propio nombre de dominio en la barra de búsqueda y abra el proyecto en una nueva ventana.
- Elija la toma más exitosa, que esté más cerca de la fecha del problema y tenga una vista completa.
- Corregir enlaces directos internos. Para hacer esto, use el enlace "http://web.archive.org/web/any_order_id_number_id_/ Site Name".
- Copie la información perdida o los datos de diseño que se aplicarán para la recuperación.
Tenga en cuenta que el proceso es algo tedioso, dada la velocidad del archivo. Por lo tanto, recomendamos que los propietarios de grandes recursos web realicen copias de seguridad con mayor frecuencia, lo que ahorra tiempo y nervios.
Estamos buscando contenido único para nuestro propio sitio.

Algunos webmasters utilizan una forma interesante de obtener contenido nuevo e inútil. Todos los días, cientos de sitios quedan en el olvido, y con ellos se pierde información. Para convertirse en el propietario del contenido, debe hacer lo siguiente:
- Introducir URL
https://www.nic.ru/auction/forbuyer/download_list.shtml#buying en la barra de búsqueda. - En el sitio de subastas de nombres de dominio, descargue archivos con el nombre ru.
- Abra los archivos recibidos utilizando Excel e inicie la selección de acuerdo con el parámetro de disponibilidad de información del proyecto.
- Ingrese los proyectos encontrados en la lista en la página de búsqueda de archivos web.
- Abra una instantánea y acceda al flujo de información.
Le recomendamos que rastree el contenido por plagio, esto le permitirá encontrar textos realmente dignos. ¡Y eso es todo! Ahora todos conocen las posibilidades y los métodos para usar el archivo web. Use el conocimiento sabia y provechosamente.