 Вхід
ВхідЗовнішній вигляд архівів WordPress за замовчуванням. Зовнішній вигляд архівів WordPress за замовчуванням Php скрипт для архівації файлів
Коли потрібно швидко викачати вихідні коди сайту з сервера, навіть відносно швидкий SSH тунель не дає потрібної швидкості. І чекати доводиться дуже і дуже довго. А ще багато хостинг провайдери не надають цього доступу, а змушують задовольнятися FTP, який в рази повільніше.
Особисто для себе я визначив вихід. На сервер закачується невеликий скрипт і запускається. Через деякий час отримуємо архів з усіма кодами. А один файл, навіть по древньому FTP гойдається набагато швидше ніж сотня маленьких.
Раніше на сторінках цього блогу бібліотека zipArchive. Однак, тоді мова йшла про розпакуванні архіву.
Для початку, нам буде потрібно дізнатися, чи є на сервері підтримка zipArchive. Це популярна бібліотека встановлена \u200b\u200bна переважній кількості хостингів.
Бібліотека жорстко обмежена параметрами php і сервера. Величезні бази і банки фотографій заархівувати не вийде. Навіть бази старої доброї програми 1С для бухгалтерії. Здавалося б в них повинні бути лише текстові дані. Але немає.
Раджу використовувати бібліотеку, лише при архівації відносно невеликих сайтів, з величезним числом дрібних файлів.
Перевіримо чи доступна робота з бібліотекою
If (! Extension_loaded ( "zip")) (return false;)
Якщо все добре, скрипт продовжить своє виконання далі.
Невеликий оффтоп, для таких перевірок. Перевірки варто робити саме так, уникаючи великих конструкцій з вкладеними дужками. Так код буде більш атомарним, і легко піддаватиметься налагодженні. Порівняйте
If (a \u003d\u003d b) (if (c \u003d\u003d d) (if (e \u003d\u003d f) (echo "Всі умови спрацювали";) else echo "e<>f ";) else echo" c<>d ";) else echo" a<>b;
і такий код
If (a! \u003d B) exit ( "a<>b); if (c! \u003d d) exit ( "c<>d); if (e! \u003d f) exit ( "e<>f); echo "Всі умови спрацювали";
Код приємніше і не розростається на величезні вкладені конструкції.
Вибачте за оффтоп, але хотілося поділиться цією знахідкою.
Тепер створимо об'єкт і архів.
$ Zip \u003d new ZipArchive (); if (! $ zip-\u003e open ($ destination, ZIPARCHIVE :: CREATE)) (return false;)
де $ destination - це повний шлях до архіву. Якщо архів уже створений, то файли будуть в нього дозапісиваться.
$ Zip-\u003e addEmptyDir (str_replace ($ source. "/", "", $ File. "/"));
де $ source це повний шлях до нашої категорії (яку ми спочатку архівували), $ file - це повний шлях до поточної папки. Це зроблено для того, щоб в архіві не було повних шляхів, а лише відносні.
Додавання файлу працює схожим чином, але потрібно спершу прочитати його в рядок.
$ Zip-\u003e addFromString (str_replace ($ source. "/", "", $ File), file_get_contents ($ file));
В кінці треба закрити архів.
Return $ zip-\u003e close ();
Як пробігти всі файли і піддиректорії в папці, думаю пояснювати не треба. Погуглити, щось на зразок Рекурсивний обхід папок на php
Мені підійшов такий варіант
Function Zip ($ source, $ destination) (if (! Extension_loaded ( "zip") ||! File_exists ($ source)) (return false;) $ zip \u003d new ZipArchive (); if (! $ Zip-\u003e open ( $ destination, ZIPARCHIVE :: CREATE)) (return false;) $ source \u003d str_replace ( "\\\\", "/", realpath ($ source)); if (is_dir ($ source) \u003d\u003d\u003d true) ($ files \u003d new RecursiveIteratorIterator (new RecursiveDirectoryIterator ($ source), RecursiveIteratorIterator :: SELF_FIRST); foreach ($ files as $ file) ($ file \u003d str_replace ( "\\\\", "/", $ file); // Ignore "." and ".." folders if (in_array (substr ($ file, strrpos ($ file, "/") + 1), array ( ".", ".."))) continue; $ file \u003d realpath ($ file ); $ file \u003d str_replace ( "\\\\", "/", $ file); if (is_dir ($ file) \u003d\u003d\u003d true) ($ zip-\u003e addEmptyDir (str_replace ($ source. "/", "" , $ file. "/"));) else if (is_file ($ file) \u003d\u003d\u003d true) ($ zip-\u003e addFromString (str_replace ($ source. "/", "", $ file), file_get_contents ($ file));))) else if (is_file ($ source) \u003d\u003d\u003d true) ($ zip-\u003e addFromString (basename ($ source), file_get_contents ($ source));) return $ zip-\u003e close (); )
Зрозуміло, що творцям шаблонів простіше стандартними функціями і тегами шаблонів WordPress вивести стандартні види всіх сторінок сайту, але це створює одноманітність зовнішнього вигляду і відчуття переходу на одні й ті ж сторінки сайту.
Відразу покажу, що отримаємо в результаті.
Вид архівів wordpress: архів рубрик до измения  Архів рубрик з прибраними слайдами і посиланням докладніше.
Архів рубрик з прибраними слайдами і посиланням докладніше.
Важливо! Так як дана задача вирішується зміною коду шаблону, то перед роботами робимо (базу даних + файли сайту). У доповненні, робимо дві копії робочого шаблону, одну для редагування, другу для відновлення неправильної правки.
Міняємо зовнішній вигляд архівів WordPress
щоб змінити зовнішній вигляд архівів WordPress, потрібно знайти, вірніше, визначити, який файл у вашому робочому шаблоні виводить архіви. У більшості шаблонів все архіви виводяться єдиним файлом, називається він (archive.php).
Повторююсь, для безпеки втратити сайт, не використовуємо редактор в адміністративної панелі сайту, а правим заздалегідь зроблені резервні копії файлів шаблону.
В текстовому редакторі (Типу Notepad ++), відкриваємо файл archive.php і починаємо правку. У файлі archive.php (в кінці файлу) шукаємо функцію, що виводить блог архіву:
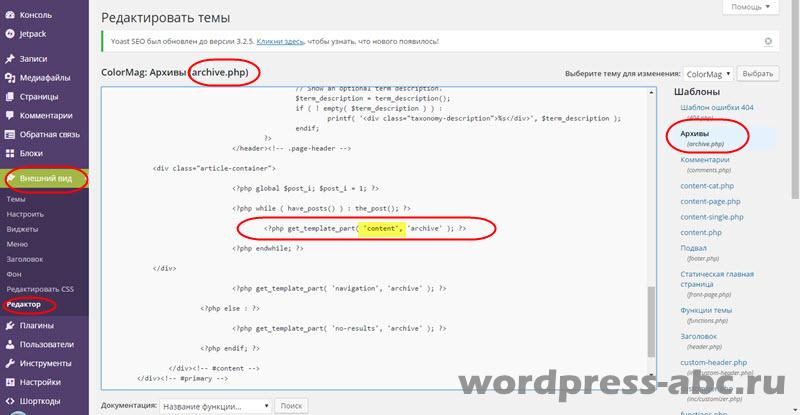
Ім'я це ім'я файлу, який використовується для виведення блогу архівів.
Перша ідея виконання завдання проста: Нам потрібно поміняти код файлу виводить архіви (content.php), а саме, прибрати в ньому кілька функцій, і тим самим змінити зовнішній вигляд всіх архівів сайту (рубрик, авторів, дат і т.д.).
Але виникає питання, якщо ми поміняємо код файлу шаблону, він повернеться до свого попереднього стану після першого поновлення шаблону, нам це не потрібно. Тому, ми не будемо редагувати файл content.php, а копіюємо його і створюємо свій файл, під іншою назвою, наприклад content-cat.php і редагуємо його.
Шукаємо в файлі функцію, що виводить мініатюри. Функція виведення мініатюр буде вгорі. Прибираємо висновок мініатюри.

або і прибираємо рядок з 'Read More', 'назва шаблону'.

Створений і відредагований файл content-cat.php зберігаємо і заливаємо в каталог сайта в папку робочого шаблону. Цей файл з'явиться в адміністративній панелі сайту на вкладці Зовнішній вигляд → Редактор.
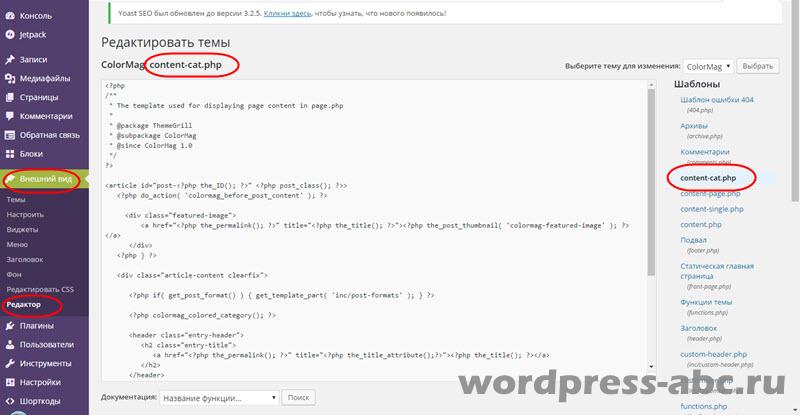
Переходимо до другого кроку. У файлі, який виводить архіви (archive.php), міняємо назву файлу content на content-cat.
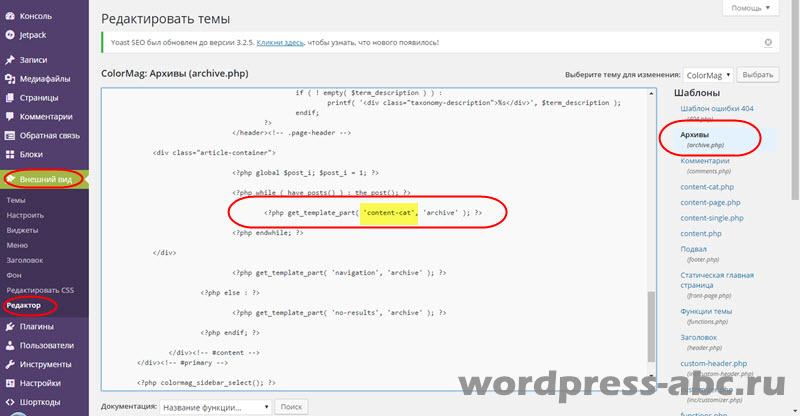
Зберігаємося і дивимося результат. Якщо, що ті не так, система покаже помилку, файл помилки і рядок помилки. Для виправлення помилки, збережені резервні файли шаблону повертаємо на місце і повторюємо все заново.
Порада. Якщо хочете почитати більше, про тегах шаблонів і стандартних функціях WordPress, Зверніть увагу на цей сайт: https://wp-kama.ru. Це не реклама і навіть не посилання, цей сайт зрозуміліше, ніж офіційний сайт WordPress, в розділі тегів шаблонів і функцій.
У розвиток теми
По-моєму, тема анонсів на сайтах WordPress вимагає продовження. У найближчих постах, промовлю теми: і.
WordPress Codex
Прихований текст
функція the_post_thumbnail
функція
the_post_thumbnail
призначення
Функція the_post_thumbnail виводить html код картинки-мініатюри поста порожнє значення, якщо картинка відсутня.
застосування
Цей тег шаблону, функція the_post_thumbnail, повинен використовуватися всередині
Використання
the_post_thumbnail (string | array $ size \u003d "post-thumbnail", string | array $ attr \u003d "")джерело
файл: wp-includes / post-thumbnail-template.php
Function the_post_thumbnail ($ size \u003d "post-thumbnail", $ attr \u003d "") (echo get_the_post_thumbnail (, $ size, $ attr);)
параметри
$ Size (рядок / масив)
Розмір мініатюри, яку потрібно отримати. Може бути рядком з умовними розмірами: thumbnail, medium, large, full або масив з двох елементів (ширина і висота картинки): array (60, 60).
За замовчуванням: 'Post-thumbnail', тобто розмір який встановлюється для поточної теми функцією set_post_thumbnail_size ()
$ Attr (рядок / масив)
Масив атрибутів, які потрібно додати получаемому html тегу img (alt - альтернативна назва).
За замовчуванням:
приклад
_("permalink"), the_title_attribute("echo=0")); ?>"> !}get ( "layout", "imgwidth"), $ SMTheme-\u003e get ( "layout", "imgheight")), array ( "class" \u003d\u003e $ SMTheme-\u003e get ( "layout", "imgpos"). " featured_image ")); if (! is_single ()) (?\u003eКожен сайт - це історія, яка має початок і кінець. Але як простежити етапи становлення проекту, його життєвий цикл? Для цих цілей існує спеціальний сервіс, який іменується веб-архівом. У цій статті ми поговоримо про подання подібних ресурсів, їх використання та можливості.
Що таке веб-архів і навіщо він потрібен?
Веб-архів - це спеціалізований сайт, який призначений для збору інформації про різних інтернет-ресурсах. Робот здійснює збереження копії проектів в автоматичному і ручному режимі, все залежить лише від майданчика і системи збору даних.
На поточний момент є кілька десятків сайтів зі схожою механікою і завданнями. Деякі з них вважаються приватними, інші - відкритими для громадськості некомерційними проектами. Також ресурси відрізняються один від одного частотою відвідин, повнотою інформації, що зберігається і можливостями використання отриманої історії.
Як відзначають деякі експерти, сторінки зберігання інформаційних потоків вважаються важливою складовою Web 2.0. Тобто, частиною ідеології розвитку мережі інтернет, яка знаходиться в постійній еволюції. Механіка збору досить посередня, але більш просунутих способів або аналогів немає. З використанням веб-архіву можна вирішити кілька проблем: відстеження інформації в часі, відновлення втраченого сайту, пошук інформації.
Як використовувати веб-архів?

Як вже зазначалося вище, веб-архів - це сайт, який надає певного роду послуги з пошуку в історії. Щоб використовувати проект, необхідно:
- Зайти на спеціалізований ресурс (наприклад, web.archive.org).
- У спеціальне поле внести інформацію до пошуку. Це може бути доменне ім'я або ключове слово.
- Отримати відповідні результати. Це буде один або кілька сайтів, до кожного з яких є фіксована дата обходу.
- Натисканням за датою перейти на відповідний ресурс і використовувати інформацію в особистих цілях.
Про спеціалізованих сайтах для пошуку історичного фіксування проектів поговоримо далі, тому залишайтеся з нами.
Проекти, що надають історію сайту

Сьогодні існує кілька проектів, які надають сервісні послуги з відшукання збережених копій. Ось деякі з них:
- Самим популярним і затребуваним у користувачів є web.archive.org. Представлений сайт вважається найбільш старим на просторах інтернету, створення датується 1996 роком. Сервіс проводить автоматичний і ручний збір даних, а вся інформація розміщується на величезних закордонних серверах.
- Другим за популярністю сайтом вважається peeep.us. Ресурс вельми цікавий, адже його можна використовувати для збереження копії інформаційного потоку, який доступний тільки вам. Зауважимо, що проект працює з усіма доменними іменами і розширює межі використання веб-архівів. Що стосується повноти інформації, то представлений веб-сайт не зберігає картинки і фрейми. З 2015 року також внесений до списку заборонених на території Росії.
- Аналогічним проектом, який описували вище, є archive.is. До відмінностей можна віднести повноту збору інформації, а також можливості збереження сторінок з соціальних мереж. Тому якщо ви загубили пост або цікаву інформацію, можна виконати пошук через веб-архів.
Можливості використання веб-архівів

Тепер кожен знає, що таке веб-архів, які сайти надають послуги збереження копій проектів. Але багато хто до цих пір не розуміють, як використовувати представлену інформацію. Можливості архівних даних виражаються в наступному:
- Вибір доменного імені. Не секрет, що багато веб-майстри використовують вже прокачані домени. Варто розуміти, що досвідчені користувачі відстежують не тільки цільові параметри, але і історію попереднього використання. Кожен користувач мережі бажає знати, що набуває: чи були раніше заборони або санкції, не попадав чи проект під фільтри.
- Відновлення сайту з архівів. Іноді трапляється біда, яка ставить під загрозу існування власного проекту. Відсутність своєчасних бекапов в профілі хостингу і випадкова помилка може призвести до трагедії. Якщо подібне сталося, не варто засмучуватися, адже можна скористатися веб-архівом. Про процес відновлення поговоримо нижче.
- Пошук унікального контенту. Щодня на просторах інтернету вмирають сайти, які наповнені контентом. Це трапляється з особливим постійністю, через що втрачається величезний потік інформації. Згодом такі сторінки випадають з індексу, і спритний веб-майстер може запозичити інформацію на особистий проект. Звичайно, існує проблема з пошуком, але це вторинна турбота.
Ми розглянули основні можливості, які надають веб-архіви, саме час перейти до більш докладного вивчення окремих елементів.
Відновлюємо сайт з веб-архіву

Ніхто не застрахований від проблем з сайтами. Більшість з них вирішується з використанням резервних копій. Але що робити, якщо збереженої копії на сервері хостингу немає? Скористатися веб-архівом. Для цього слід:
- Зайти на спеціалізований ресурс, про які ми говорили раніше.
- Внести власне доменне ім'я в рядок пошуку і відкрити проект в новому вікні.
- Вибрати найбільш вдалий знімок, який розташовується ближче до проблемної датою і має повноцінний вид.
- Виправити внутрішні посилання на прямі. Для цього використовуємо посилання «http://web.archive.org/web/любой_порядковый_номер_id_/Название сайту».
- Скопіювати втрачену інформацію або дані дизайну, які будуть застосовані для відновлення.
Зауважимо, що процес кілька виснажливий, з урахуванням швидкості роботи архіву. Тому рекомендуємо власникам великих веб-ресурсів частіше виконувати бекапи, що збереже час і нерви.
Шукаємо унікальний контент для власного сайту

Деякі веб-майстри використовують цікавий спосіб отримання нового, нікому не потрібного контенту. Щодня сотні сайтів йдуть у небуття, а разом з ними втрачається інформація. Щоб стати власником контенту, потрібно виконати наступне:
- внести URL
https://www.nic.ru/auction/forbuyer/download_list.shtml#buying в рядок пошуку. - На сайті аукціону доменних імен завантажити файли з ім'ям ru.
- Відкрити отримані файли з використанням excel і почати відбір по параметру наявності проектної інформації.
- Знайдені в списку проекти ввести на сторінці пошуку веб-архіву.
- Відкрити знімок і отримати доступ до інформаційного потоку.
Рекомендуємо відстежувати контент на наявність плагіату, це дозволить знайти дійсно гідні тексти. А на цьому все! Тепер кожен знає про можливості та методи використання веб-архіву. Використовуйте знання з розумом і вигодою.