 ingång
ingångNeurala nätverk och exempel på deras användning inom ekonomi. "neurala nätverk
God eftermiddag, jag heter Natalia Efremova och jag är forskare vid NtechLab. Idag ska jag prata om synpunkterna neurala nätverk och deras tillämpning.
Först ska jag säga några ord om vårt företag. Företaget är nytt, många av er kanske inte vet vad vi gör ännu. Vi vann MegaFace-tävlingen förra året. Detta är en internationell ansiktsigenkänningstävling. Samma år öppnades vårt företag, det vill säga vi har funnits på marknaden i ungefär ett år, till och med lite mer. Därför är vi ett av de ledande företagen inom ansiktsigenkänning och biometrisk avbildning.
Den första delen av mitt föredrag kommer att riktas till dem som inte är bekanta med neurala nätverk. Jag är direkt involverad i djupinlärning. Jag har arbetat inom detta område i över 10 år. Även om det dök upp för lite mindre än ett decennium sedan, brukade det finnas några rudiment av neurala nätverk som såg ut som ett system för djupinlärning.
Under de senaste 10 åren har djupinlärning och datorseende utvecklats i en otrolig takt. Allt som har gjorts meningsfullt på detta område har hänt under de senaste 6 åren.
Jag kommer att prata om de praktiska aspekterna: var, när, vad ska man tillämpa när det gäller djupinlärning för bild- och videobehandling, för bild- och ansiktsigenkänning, eftersom jag jobbar på ett företag som gör detta. Jag ska berätta lite om emotionsigenkänning, vilka tillvägagångssätt som används i spel och robotteknik. Jag kommer också att prata om den icke-standardiserade tillämpningen av djupinlärning, något som just har kommit från vetenskapliga institutioner och fortfarande används lite i praktiken, hur det kan tillämpas och varför det är svårt att tillämpa.
Rapporten kommer att vara i två delar. Eftersom de flesta är bekanta med neurala nätverk kommer jag först snabbt att berätta hur neurala nätverk fungerar, vad biologiska neurala nätverk är, varför det är viktigt för oss att veta hur det fungerar, vad artificiella neurala nätverk är och vilka arkitekturer som används i vilka områden.
Jag ber genast om ursäkt, jag ska hoppa lite till engelsk terminologi, för det mesta av vad det heter på ryska vet jag inte ens. Kanske du också.
Så den första delen av föredraget kommer att ägnas åt konvolutionella neurala nätverk. Jag kommer att förklara hur convolutional neural network (CNN), bildigenkänning, fungerar med ett exempel från ansiktsigenkänning. Jag ska berätta lite om recurrent neural network (RNN) och förstärkningsinlärning med djupinlärningssystem som exempel.
Som en icke-standard tillämpning av neurala nätverk kommer jag att prata om hur CNN arbetar inom medicin för att känna igen voxelbilder, hur neurala nätverk används för att känna igen fattigdom i Afrika.
Vad är neurala nätverk
Prototypen för skapandet av neurala nätverk var konstigt nog biologiska neurala nätverk. Kanske många av er vet hur man programmerar ett neuralt nätverk, men var det kom ifrån tror jag att vissa inte vet. Två tredjedelar av all sensorisk information som kommer till oss kommer från perceptionens visuella organ. Mer än en tredjedel av vår hjärnas yta upptas av två av de viktigaste visuella zonerna - den dorsala synvägen och den ventrala synvägen.Den dorsala synvägen börjar i den primära synzonen, vid vår krona, och fortsätter uppåt, medan den ventrala vägen börjar på baksidan av vårt huvud och slutar ungefär bakom öronen. All viktig mönsterigenkänning som vi har, alla meningsfulla saker som vi är medvetna om, sker precis där, bakom öronen.
Varför är det viktigt? Eftersom det ofta behövs för att förstå neurala nätverk. För det första pratar alla om det, och jag är redan van vid att detta händer, och för det andra är faktum att alla områden som används i neurala nätverk för mönsterigenkänning kom till oss just från den ventrala synvägen, där varje ett litet område är ansvarigt för dess strikt definierade funktion.
Bilden kommer till oss från näthinnan, passerar genom en serie visuella zoner och slutar i tidszonen.
Under det avlägsna 60-talet av förra seklet, när studiet av hjärnans visuella zoner bara började, utfördes de första experimenten på djur, eftersom det inte fanns någon fMRI. Hjärnan undersöktes med hjälp av elektroder implanterade i olika visuella zoner.
Den första visuella zonen utforskades av David Huebel och Thorsten Wiesel 1962. De experimenterade på katter. Olika rörliga föremål visades för katterna. Det som hjärncellerna reagerade på var stimulansen som djuret kände igen. Redan nu utförs många experiment på dessa drakoniska sätt. Men ändå är detta det mest effektiva sättet att ta reda på vad varje liten cell i vår hjärna gör.
På samma sätt upptäcktes många fler viktiga egenskaper hos visuella zoner, som vi använder i djupinlärning nu. En av de viktigaste egenskaperna är en ökning av våra cellers mottagliga fält när vi rör oss från de primära visuella zonerna till tinningloberna, det vill säga till de senare visuella zonerna. Det receptiva fältet är den del av bilden som varje cell i vår hjärna bearbetar. Varje cell har sitt eget receptiva fält. Samma egenskap finns bevarad i neurala nätverk också, som ni säkert alla vet.
När de receptiva fälten ökar ökar också de komplexa stimuli som neurala nätverk normalt känner igen.

Här ser du exempel på komplexiteten hos stimuli, de olika tvådimensionella former som känns igen i zonerna V2, V4 och olika delar av de temporala fälten hos makaker. Ett antal MRT-experiment genomförs också.

Här kan du se hur sådana experiment går till. Detta är 1 nanometer del av IT-barken "en apas zoner när den känner igen olika föremål. Där den känns igen är markerad.
Låt oss sammanfatta. En viktig egenskap som vi vill ta till oss från de visuella zonerna är att storleken på de receptiva fälten ökar, och komplexiteten hos de objekt som vi känner igen ökar.
Datorsyn
Innan vi lärde oss hur man tillämpar detta på datorseende - i allmänhet, som sådant, fanns det inte. Om något så fungerade det inte så bra som det gör nu.Vi överför alla dessa egenskaper till det neurala nätverket, och nu fungerar det, om du inte tar med en liten utvikning till dataset, som jag kommer att prata om senare.
Men först lite om den enklaste perceptronen. Det bildas också i bilden och bilden av vår hjärna. Det enklaste elementet som liknar en hjärncell är en neuron. Har inmatningselement som körs från vänster till höger som standard, ibland från botten till toppen. Till vänster finns ingångsdelarna av neuronen, till höger är neurons utgångsdelar.
Den enklaste perceptronen kan endast utföra de enklaste operationerna. För att göra mer komplexa beräkningar behöver vi en struktur med många dolda lager.

När det gäller datorseende behöver vi ännu fler dolda lager. Och först då kommer systemet intelligent att känna igen vad det ser.
Så vad som händer under bildigenkänning, jag kommer att berätta för dig med exemplet med ansikten.
För oss att titta på den här bilden och säga att den föreställer statyns ansikte är ganska enkelt. Men fram till 2010 var detta en otroligt svår uppgift för datorseende. De som har sysslat med denna fråga innan den här tiden vet säkert hur svårt det var att beskriva föremålet som vi vill hitta på bilden utan ord.
Vi behövde göra detta på något geometriskt sätt, beskriva objektet, beskriva förhållandet mellan objektet, hur dessa delar kan relatera till varandra, sedan hitta den här bilden på objektet, jämföra dem och få det vi kände igen dåligt. Det här var oftast lite bättre än att kasta ett mynt. Något bättre än chansnivån.
Så är inte fallet nu. Vi delar upp vår bild antingen i pixlar eller i några lappar: 2x2, 3x3, 5x5, 11x11 pixlar - lika praktiskt för skaparna av systemet där de fungerar som ett ingångsskikt till det neurala nätverket.
Signaler från dessa ingående lager överförs från lager till lager med hjälp av synapser, vart och ett av lagren har sina egna specifika koefficienter. Så vi går från lager till lager, från lager till lager, tills vi får att vi har känt igen ansiktet.
Konventionellt kan alla dessa delar delas in i tre klasser, vi kommer att beteckna dem X, W och Y, där X är vår ingångsbild, Y är en uppsättning etiketter och vi måste få våra vikter. Hur räknar vi ut W?
Med våra X och Y verkar det enkelt. Men det som indikeras med en asterisk är en mycket komplex icke-linjär operation som tyvärr inte har någon baksida. Även med 2 givna komponenter i ekvationen är det mycket svårt att beräkna det. Därför måste vi gradvis, med försök och misstag, genom att välja vikten W, så att felet minskar så mycket som möjligt, helst för att bli lika med noll.

Denna process sker iterativt, vi minskar hela tiden tills vi hittar värdet på vikten W som passar oss tillräckligt.
Förresten, inte ett enda neuralt nätverk som jag har arbetat med nådde ett fel lika med noll, men det fungerade ganska bra.

Här är det första nätverket som vann den internationella ImageNet-tävlingen 2012. Detta är det så kallade AlexNet. Detta är ett nätverk som först deklarerade sig självt, att det finns konvolutionella neurala nätverk, och sedan dess har konvolutionella neurala nät aldrig överlämnat sina positioner vid alla internationella tävlingar.
Trots att detta nätverk är ganska litet (det finns bara 7 dolda lager) innehåller det 650 tusen neuroner med 60 miljoner parametrar. För att iterativt lära sig att hitta rätt vikter, vi behöver många exempel.
Det neurala nätverket lär sig av exemplet med en bild och en etikett. Eftersom vi i barndomen får lära oss "det här är en katt och det här är en hund", tränas också neurala nätverk på ett stort antal bilder. Men faktum är att det fram till 2010 inte fanns någon tillräckligt stor datamängd som kunde lära ett sådant antal parametrar att känna igen bilder.
De största databaserna som fanns före den här tiden: PASCAL VOC, som bara hade 20 kategorier av objekt, och Caltech 101, som utvecklades vid California Institute of Technology. Den senare hade 101 kategorier, och det var mycket. De som inte kunde hitta sina föremål i någon av dessa databaser fick kosta sina databaser, vilket, jag kommer att säga, är fruktansvärt smärtsamt.
Men 2010 dök ImageNet-databasen upp, där det fanns 15 miljoner bilder, uppdelade i 22 tusen kategorier. Detta löste vårt problem med att träna neurala nätverk. Nu kan alla som har en akademisk adress enkelt gå till basens plats, begära åtkomst och få denna bas för att träna sina neurala nätverk. De svarar tillräckligt snabbt, enligt mig, dagen efter.
Jämfört med de tidigare datamängderna är detta en mycket stor databas.

Exemplet visar hur obetydligt allt som kom före henne var. Samtidigt med ImageNet-basen dök ImageNet-tävlingen upp, en internationell utmaning där alla lag som vill tävla kan delta.
I år vann nätverket som skapades i Kina, det hade 269 lager. Jag vet inte hur många parametrar, jag misstänker att det också finns många.
Djup neural nätverksarkitektur
Det kan villkorligt delas upp i 2 delar: de som studerar och de som inte studerar.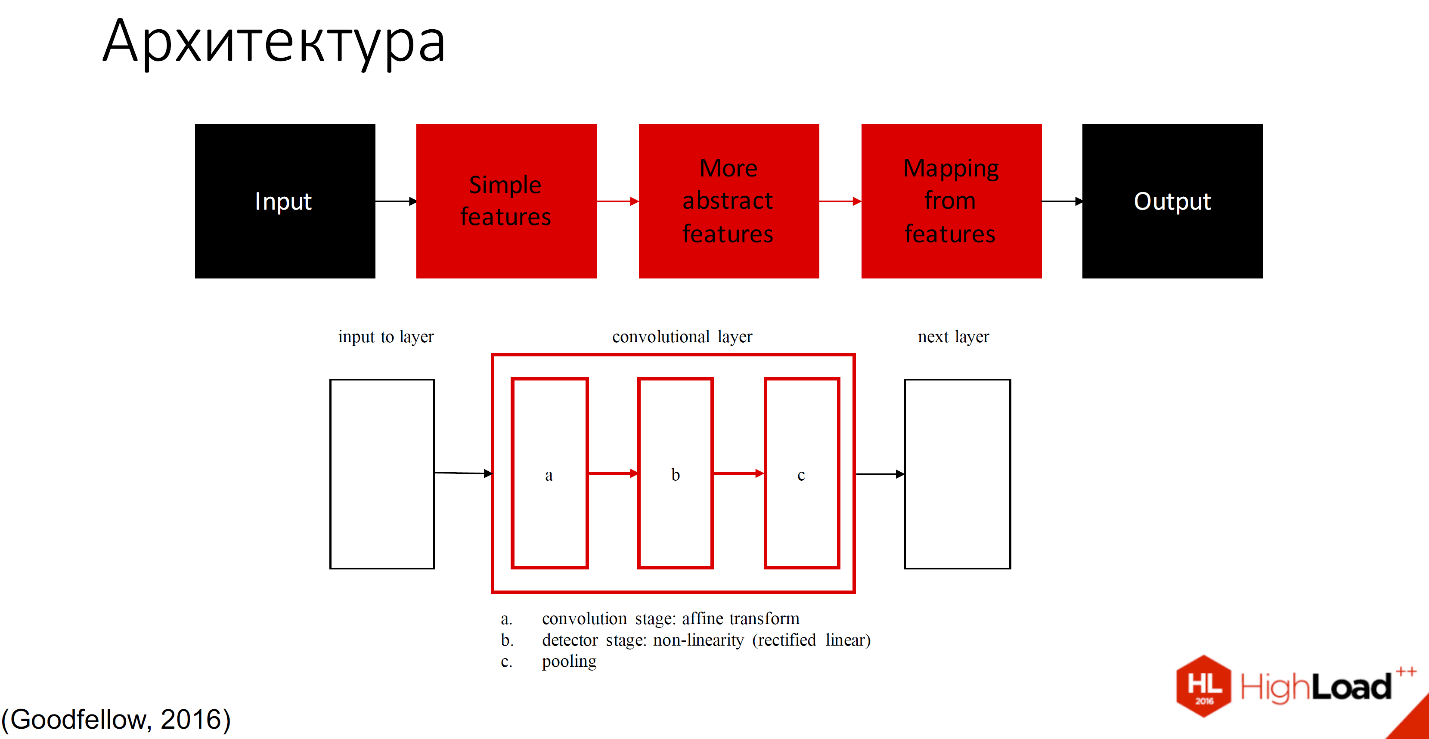
De delar som inte lär sig är markerade med svart, alla andra lager kan lära sig. Det finns många definitioner av vad som finns inuti varje faltningslager. En av de accepterade beteckningarna är att ett lager med tre komponenter är uppdelat i ett faltningssteg, ett detektorsteg och ett poolsteg.
Jag kommer inte gå in på detaljer, det kommer att finnas många fler rapporter som beskriver hur det fungerar. Jag ska berätta med ett exempel.
Eftersom arrangörerna bad mig att inte nämna många formler, kastade jag ut dem helt och hållet.

Så ingångsbilden hamnar i ett nätverk av lager, som kan kallas filter av olika storlekar och olika komplexitet hos de element som de känner igen. Dessa filter utgör sitt eget index eller en uppsättning funktioner, som sedan hamnar i klassificeraren. Vanligtvis är det antingen SVM eller MLP - flerskiktsperceptron, vad som är bekvämt för vem som helst.
I bilden och likheten med ett biologiskt neuralt nätverk känns igen objekt av varierande komplexitet. När antalet lager ökade förlorade allt detta sin förbindelse med cortex, eftersom det finns ett begränsat antal zoner i det neurala nätverket. 269 eller många, många abstraktionszoner, så bara en ökning av komplexitet, antal element och mottagliga fält återstår.

Om vi tittar på exemplet med ansiktsigenkänning, så kommer det receptiva fältet för det första lagret att vara litet, sedan lite större, mer och så vidare tills vi äntligen kan känna igen ansiktet som helhet.

Ur synvinkeln av vad vi har inuti filtren kommer det först att finnas lutande pinnar plus lite färg, sedan delar av ansikten, och sedan kommer hela ansikten att kännas igen av varje cell i lagret.
Det finns människor som hävdar att en person alltid känner igen bättre än ett nätverk. Är det så?
2014 beslutade forskare att testa hur väl vi känner igen i jämförelse med neurala nätverk. De tog de 2 bästa nätverken för tillfället - det här är AlexNet och nätverket av Matthew Ziller och Fergus, och jämförde det med svaret från olika områden i hjärnan hos en makak, som också lärdes känna igen vissa föremål. Föremålen var från djurriket för att apan inte skulle bli förvirrad, och experiment gjordes för att se vem som känner igen bättre.
Eftersom det är helt klart omöjligt att få ett svar från apan, implanterades elektroder i den och svaret från varje neuron mättes direkt.
Det visade sig att hjärnceller under normala förhållanden reagerade lika bra som den dåvarande toppmoderna modellen, det vill säga Matthew Zillers nätverk.
Men med en ökning av hastigheten för att visa objekt, en ökning av mängden brus och objekt i bilden, minskar igenkänningshastigheten och dess kvalitet av vår hjärna och hjärnan hos primater avsevärt. Även det enklaste konvolutionella neurala nätverket känner igen objekt bättre. Det vill säga, neurala nätverk fungerar officiellt bättre än våra hjärnor.
Klassiska problem med konvolutionella neurala nätverk
Det finns faktiskt inte så många av dem, de tillhör tre klasser. Bland dem finns sådana uppgifter som objektidentifiering, semantisk segmentering, ansiktsigenkänning, igenkänning av mänskliga kroppsdelar, semantisk definition av gränser, framhävning av uppmärksamhetsobjekt i en bild och framhävning av ytnormaler. De kan villkorligt delas in i 3 nivåer: från den lägsta nivån till den högsta nivån.
Med den här bilden som ett exempel, låt oss titta på vad varje uppgift gör.
- Att definiera gränserär den uppgift på lägsta nivå för vilken faltningsneurala nätverk redan används klassiskt.
- Definiera en vektor till normalen låter oss rekonstruera en 3D-bild från en 2D-bild.
- Framträdande, identifiera föremål för uppmärksamhet- Det här är vad en person skulle vara uppmärksam på när han överväger den här bilden.
- Semantisk segmentering låter dig dela in objekt i klasser enligt deras struktur, utan att veta något om dessa objekt, det vill säga redan innan de känns igen.
- Semantisk gränsmarkering– Det här är urvalet av gränser, uppdelat i klasser.
- Isolering av delar av människokroppen.
- Och uppgiften på högsta nivå är igenkänning av själva föremålen, som vi nu ska överväga att använda exemplet med ansiktsigenkänning.
Ansiktsigenkänning
Det första vi gör är att köra ansiktsdetektorn över bilden för att hitta ansiktet. Därefter normaliserar vi, centrerar ansiktet och kör det för bearbetning i det neurala nätverket. Efter det får vi en uppsättning eller vektor av funktioner som unikt beskriv egenskaperna hos detta ansikte.
Sedan kan vi jämföra denna vektor av funktioner med alla vektorer av funktioner som finns lagrade i vår databas, och få en referens till en specifik person, till hans namn, till hans profil - allt som vi kan lagra i databasen.
Så här fungerar vår FindFace-produkt – det är det gratis tjänst, som hjälper till att söka efter profiler för personer i VKontakte-databasen.
Dessutom har vi ett API för företag som vill prova våra produkter. Vi tillhandahåller tjänster för ansiktsdetektion, verifiering och användaridentifiering.
Vi har nu utvecklat 2 scenarier. Den första är identifiering, sökning efter en person i en databas. Det andra är verifiering, detta är en jämförelse av två bilder med en viss sannolikhet att de är en och samma person. Dessutom utvecklar vi för närvarande emotionsigenkänning, bildigenkänning på video och livlighetsdetektering - detta är att förstå om en person är vid liv framför en kamera eller ett fotografi.
Lite statistik. När vi identifierar, när vi söker efter 10 tusen bilder, har vi en noggrannhet på cirka 95%, beroende på kvaliteten på basen, 99% noggrannhet för verifiering. Och förutom detta är den här algoritmen mycket motståndskraftig mot förändringar - vi behöver inte titta in i kameran, vi kan ha några hindrande föremål: glasögon, solglasögon, ett skägg, en medicinsk mask. I vissa fall kan vi övervinna till och med sådana otroliga svårigheter för datorseende som glasögon och en mask.
Mycket snabb sökning, tar 0,5 sekunder att bearbeta 1 miljard bilder. Vi har tagit fram ett unikt index snabbsökning... Vi kan även arbeta med bilder av låg kvalitet från CCTV-kameror. Vi kan hantera allt i realtid. Du kan ladda upp bilder via webbgränssnittet, via Android, iOS och söka 100 miljoner användare och deras 250 miljoner bilder.
Vi tog som sagt förstaplatsen på MegaFace-tävlingen – en analog för ImageNet, men för ansiktsigenkänning. Det har varit igång i flera år nu, förra året var vi bäst bland 100 team från hela världen, inklusive Google.
Återkommande neurala nätverk
Vi använder återkommande neurala nätverk när det inte räcker för oss att bara känna igen bilden. I de fall det är viktigt för oss att upprätthålla en sekvens behöver vi ordningen på vad som händer, vi använder vanliga återkommande neurala nätverk.Den används för naturligt språkigenkänning, för videobearbetning, även för bildigenkänning.
Jag kommer inte att prata om erkännande av naturligt språk – efter mitt betänkande kommer det två till, som kommer att syfta till erkännande av naturligt språk. Därför kommer jag att berätta om arbetet med återkommande nätverk med hjälp av exemplet med känsloigenkänning.
Vad är återkommande neurala nätverk? Detta är ungefär detsamma som konventionella neurala nätverk, men med återkoppling. Vi behöver feedback för att överföra systemets tidigare tillstånd till ingången av det neurala nätverket eller till några av dess lager.
Låt oss säga att vi bearbetar känslor. Även i ett leende - en av de enklaste känslorna - finns det flera saker: från ett neutralt ansiktsuttryck till ögonblicket när vi har ett fullt leende. De går en efter en i följd. För att förstå detta väl måste vi kunna observera hur detta händer, överföra det som fanns i föregående bildruta till nästa steg i systemet.

2005, vid Emotion Recognition in the Wild, specifikt för att känna igen känslor, presenterade ett team från Montreal ett återkommande system som såg väldigt enkelt ut. Hon hade bara ett fåtal konvolutionerande lager och arbetade uteslutande med video. I år har de också lagt till ljudigenkänning och aggregerad bildruta-för-bildruta-data som kommer från konvolutionella neurala nätverk, ljuddata med ett återkommande neuralt nätverk (med tillståndsretur) som fungerar, och vann förstaplatsen i tävlingen.
Förstärkningsinlärning
Nästa typ av neurala nätverk, som mycket ofta används nyligen, men som inte har fått lika stor publicitet som de tidigare 2 typerna, är djup förstärkningsinlärning, förstärkningsinlärning.Faktum är att vi i de två föregående fallen använder databaser. Vi har antingen ansiktsdata, bilddata eller känslodata från videor. Om vi inte har det, om vi inte kan skjuta det, hur kan vi lära roboten att ta föremål? Vi gör detta automatiskt – vi vet inte hur det fungerar. Ett annat exempel: komponera stora databaser i datorspel svårt, och inte nödvändigt, du kan göra det mycket lättare.
Alla har säkert hört talas om framgången med djup förstärkningsinlärning i Atari och i Go.
Vem har hört talas om Atari? Nåväl, någon hörde, okej. Jag tror att alla har hört talas om AlphaGo, så jag kommer inte ens berätta vad exakt som händer där.

Vad händer på Atari? Arkitekturen för detta neurala nätverk visas till vänster. Hon lär sig genom att leka med sig själv för att få maximal belöning. Den maximala belöningen är det snabbaste möjliga resultatet av spelet med största möjliga poäng.
Överst till höger - det sista lagret av det neurala nätverket, som visar hela antalet tillstånd i systemet, som spelade mot sig själv i bara två timmar. Önskvärda resultat av spelet med maximal belöning visas i rött och oönskade resultat i blått. Nätverket bygger ett slags fält och rör sig genom sina tränade lager till det tillstånd som det vill uppnå.
Inom robotteknik är situationen lite annorlunda. Varför? Vi har några komplikationer här. För det första har vi inte många databaser. För det andra måste vi samordna tre system samtidigt: uppfattningen av roboten, dess handlingar med hjälp av manipulatorer och dess minne - vad som gjordes i föregående steg och hur det gjordes. I allmänhet är allt detta väldigt svårt.
Faktum är att inte ett enda neuralt nätverk, inte ens djupinlärning för tillfället, kan klara av denna uppgift tillräckligt effektivt, därför är djupinlärning bara enbart delar av vad robotar behöver göra. Till exempel har Sergei Levin nyligen tillhandahållit ett system som lär en robot att ta tag i föremål.

Här visas experimenten som han utförde på sina 14 robotarmar.
Vad händer här? I dessa bassänger, som du ser framför dig, finns olika föremål: pennor, suddgummi, mindre och större muggar, trasor, olika texturer, olika hårdhet. Det är oklart hur man ska träna roboten att fånga dem. I många timmar, och till och med, verkar det, veckor, har robotar tränat för att kunna ta tag i dessa objekt, databaser har sammanställts om detta.
Databaser är ett slags svar från omgivningen som vi behöver samla på oss för att kunna träna roboten att göra något i framtiden. I framtiden kommer robotar att lära sig om denna uppsättning systemtillstånd.
Icke-standardiserade tillämpningar av neurala nätverk
Tyvärr är detta slutet, jag har inte mycket tid. Jag kommer att berätta om de där icke-standardiserade lösningarna som finns nu och som enligt många prognoser kommer att ha någon form av tillämpning i framtiden.Så Stanford-forskare kom nyligen med en mycket ovanlig tillämpning av CNN:s neurala nätverk för att förutsäga fattigdom. Vad gjorde de?
Konceptet är faktiskt väldigt enkelt. Faktum är att fattigdomsnivån i Afrika går utöver alla tänkbara och otänkbara gränser. De har inte ens möjlighet att samla in socialdemografisk data. Därför har vi sedan 2005 inga uppgifter alls om vad som händer där.
Forskare samlade dag- och nattkartor från satelliter och matade dem till det neurala nätverket under en tid.
Det neurala nätverket var förkonfigurerat på ImageNet "e. Det vill säga, de första lagren av filter trimmades så att det redan kunde känna igen några mycket enkla saker, till exempel hustak, för att söka efter en bosättning på dagtidskartor. Sedan dagtidskartor. jämfördes med nattkartor, belysningen av samma område av ytan för att säga hur mycket pengar befolkningen har för att åtminstone belysa sina hem under natten.

Här kan du se resultaten av förutsägelsen byggd av det neurala nätverket. Prognosen gjordes med olika upplösningar. Och du förstår - den senaste ramen är verklig data som samlades in av den ugandiska regeringen 2005.
Du kan se att det neurala nätverket har gjort en ganska exakt förutsägelse, även med en liten förändring sedan 2005.
Det fanns förstås biverkningar. Deep learning forskare är alltid förvånade över att hitta olika biverkningar. Till exempel som de som nätverket har lärt sig känna igen vatten, skogar, stora byggarbetsplatser, vägar – allt detta utan lärare, utan förbyggda databaser. Generellt helt självständigt. Det var vissa lager som reagerade på till exempel vägarna.
Och den sista applikationen som jag skulle vilja prata om är semantisk segmentering av 3D-bilder inom medicin. Generellt sett är medicinsk bildbehandling ett komplext område som är mycket svårt att arbeta med.
Det finns flera anledningar till detta.
- Vi har väldigt få databaser. Det är inte så lätt att hitta en bild av en hjärna, dessutom en skadad, och det är också omöjligt att ta den från någonstans.
- Även om vi har en sådan bild måste vi ta en läkare och tvinga honom att manuellt placera alla lagerbilder, vilket är väldigt långt och extremt ineffektivt. Alla läkare har inte resurser att göra detta.
- En mycket hög precision krävs. Det medicinska systemet kan inte ha fel. När de kände igen till exempel katter kände de inte igen – det är okej. Och om vi inte kände igen tumören så är den inte särskilt bra. Det ställs särskilt hårda krav på systemtillförlitlighet.
- Bilder är i tredimensionella element - voxlar, inte i pixlar, vilket ger ytterligare svårigheter för systemdesigner.
Var det används: Bestämning av skada efter stroke, för att hitta en tumör i hjärnan, inom kardiologi för att avgöra hur hjärtat fungerar.

Här är ett exempel för att bestämma moderkakans volym.
Automatiskt fungerar detta bra, men inte så mycket att det kommer i produktion, så det är bara att sätta igång. Det finns flera startups där ute för att bygga sådana medicinska synsystem. Generellt sett finns det många startups inom djupinlärning inom en snar framtid. Det sägs att riskkapitalister har avsatt mer budget för startups med djupinlärning under de senaste sex månaderna än under de senaste 5 åren.
Detta område utvecklas aktivt, det finns många intressanta riktningar. Vi lever i en intressant tid. Om du är engagerad i djupinlärning är det förmodligen dags för dig att öppna din startup.
Nåväl, på detta kommer jag nog att avrunda. Tack så mycket.
Ris. 13.12. Ris. 13.13. Ris. 13.14. Ris. 13.15. Ris. 13.16. Ris. 13.17. Ris. 13.18. Ris. 13.19. Ris. 13.20. Ris. 13.21. Ris. 13.22. Ris. 13.23. Ris. 13.24. Ris. 13.25. Ris. 13.26. Ris. 13.28. Allmänt tekniskt system för databehandling
Finansmarknadernas dagliga praxis står i intressant motsägelse till den akademiska synpunkten, enligt vilken förändringar i priserna på finansiella tillgångar sker omedelbart, utan någon ansträngning, vilket effektivt återspeglar all tillgänglig information. Förekomsten av hundratals market makers, handlare och fondförvaltare, vars uppgift det är att göra vinst, tyder på att marknadsaktörerna ger ett visst bidrag till allmän information... Eftersom detta arbete är dyrt måste dessutom mängden information som tas in vara betydande.
Förekomsten av hundratals market makers, handlare och fondförvaltare på finansmarknaderna tyder på att de alla behandlar finansiell information och fattar beslut.
Det är svårare att svara på frågan om hur exakt information som kan vara lönsam uppstår och används på finansmarknaderna. Forskning visar nästan alltid att ingen hållbar handelsstrategi ger konsekvent avkastning, och detta är åtminstone fallet när man räknar in kostnaderna för att göra affärer. Det är också välkänt att marknadsaktörer (och hela marknaden som helhet) kan fatta helt olika beslut baserat på liknande eller till och med oföränderlig information.
Marknadsdeltagare i sitt arbete är tydligen inte begränsade till linjära konsekventa beslutsfattande regler, utan har flera scenarier för åtgärder på lager, och vilken av dem som används beror ibland på externa omärkliga tecken. En av de möjliga tillvägagångssätten för multidimensionella och ofta olinjära informationsserier på finansmarknaden är att imitera modeller av beteende hos marknadsdeltagare, om möjligt, genom att använda sådana artificiella intelligensmetoder som expertsystem eller neurala nätverk.
Mycket arbete har lagts ned på att modellera beslutsprocesser med dessa metoder. Det visade sig dock att expertsystem i komplexa situationer fungerar bra bara när systemet är i sig är stationärt (dvs när det finns ett enda svar som inte ändras över tiden för varje ingångsvektor). Till viss del lämpar sig denna beskrivning för problemen med komplex klassificering eller distribution av lån, men den verkar helt föga övertygande för finansmarknaderna med deras kontinuerliga strukturella förändringar. När det gäller finansiella marknader kan det knappast hävdas att det är möjligt att uppnå fullständiga eller åtminstone till viss del adekvata kunskaper om ett givet ämnesområde, medan det för expertsystem med regelbaserade algoritmer är ett vanligt krav.
Neurala nätverk erbjuder helt nya och lovande möjligheter för banker och andra finansiella institutioner, som på grund av sin verksamhet måste lösa problem under förhållanden med liten kunskap om miljön på förhand. Finansmarknadernas karaktär förändras dramatiskt sedan försvagningen av kontroller, privatiseringar och uppkomsten av nya finansiella instrument har slagit samman nationella marknader till globala marknader och ökat friheten inom de flesta marknadssektorer. finansiella transaktioner... Självklart kunde själva grunden för risk- och inkomsthantering inte låta bli att genomgå en förändring då möjligheterna till diversifiering och strategier för att skydda sig mot risk har förändrats till oigenkännlighet.
Ett av tillämpningsområdena för neurala nätverk för ett antal ledande banker är problemet med förändringar i US-dollarns position på valutamarknaden med ett stort antal oförändrade objektiva indikatorer. Möjligheterna för sådana applikationer underlättas av det faktum att det finns enorma databaser med ekonomisk data - trots allt är komplexa modeller alltid glupska när det gäller information.
Obligationskurser och arbitrage är ett annat område där utmaningarna med att expandera och minska risker, ränte- och likviditetsskillnader, marknadsdjup och likviditet bidrar till kraftfulla beräkningstekniker.
Ett annat problem som har ökat i betydelse på sistone är modelleringen av flöden av medel mellan institutionella investerare. Räntefallet har spelat en avgörande roll för att öka attraktiviteten för öppna investeringsfonder och indexfonder, och tillgången på optioner och terminer på deras aktier gör att de kan köpas med hel eller partiell garanti.
Det är uppenbart att optimeringsproblemet under förhållanden när antalet partiella jämviktsbegränsningar är oändligt (till exempel på termins- och kontantmarknaderna för vilken vara som helst i någon marknadssektor spelar korsskillnaderna mellan räntor en roll) blir ett problem för extrem komplexitet, alltmer utöver kapaciteten hos någon näringsidkare.
Under sådana omständigheter måste handlare, och därmed alla system som försöker beskriva sitt beteende, när som helst fokusera på att minska problemets dimension. Ett sådant fenomen som en säkerhet med hög efterfrågan är välkänt.
När det kommer till finanssektorn är det säkert att säga att de första resultaten som erhålls med hjälp av neurala nätverk är mycket uppmuntrande, och forskningen inom detta område behöver utvecklas ytterligare. Precis som fallet var med expertsystem kan det ta flera år innan finansiella institutioner är tillräckligt säkra på neurala nätverks kapacitet och börjar använda dem till sin fulla kapacitet.
Naturen för utvecklingen inom området för neurala nätverk skiljer sig fundamentalt från expertsystem: de senare är baserade på uttalanden som "om ... då ..." formella logiska strukturer. Neurala nätverk bygger på ett övervägande beteendemässigt förhållningssätt till det problem som ska lösas: nätverket "lär sig av exempel" och justerar sina parametrar med hjälp av så kallade inlärningsalgoritmer genom en återkopplingsmekanism.
OLIKA TYPER AV KONSTGIVNA NEURONER
En artificiell neuron (Fig. 13.1) är ett enkelt element som först beräknar den viktade summan av V-ingångsvärden formeln "src =" http://hi-edu.ru/e-books/xbook725/files/13.1. gif "border =" 0 " align = "absmiddle" alt = "(! LANG:(13.1)
Här är N dimensionen av utrymmet för insignaler.
Sedan jämförs det resulterande beloppet med tröskelvärdet (eller bias) formeln "src =" http://hi-edu.ru/e-books/xbook725/files/18.gif "border =" 0 "align =" absmitta "alt = "(! LANG:i den viktade summan brukar (1) kallas synaptiska koefficienter eller vikter. Vi kommer att kalla den viktade summan V själv potentialen för neuron i. Utsignalen har då formen f (V).
Tröskelvärdet kan ses som ytterligare en viktningsfaktor för en konstant insignal. I det här fallet talar vi om utökat entréutrymme: neuron med N-dimensionell ingång har N + 1 viktningsfaktor..2.gif "border =" 0 "align =" absmiddle "alt =" (! LANG:(13.2)
Beroende på metoden för signalomvandling och arten av aktiveringsfunktionen uppstår olika typer av neurala strukturer. Vi kommer bara att överväga deterministiska neuroner(i motsats till probabilistiska neuroner, vars tillstånd för tillfället t är en slumpmässig funktion av potentialen och tillståndet i ögonblicket t-1). Vidare kommer vi att skilja statiska neuroner- de där signalen sänds utan fördröjning, - och dynamiska, där möjligheten till sådana fördröjningar beaktas, ( Fördröjda synapser).
OLIKA SLAG AV AKTIVERINGSFUNKTIONER
Aktiveringsfunktioner f kan vara av olika typer:
Formel "src =" http://hi-edu.ru/e-books/xbook725/files/20.gif "border =" 0 "align =" absmiddle "alt =" (! LANG:, lutningen b kan tas med i beräkningen genom värdena för vikterna och tröskelvärdena, och utan förlust av allmänhet kan antas vara lika med enhet.
Det är också möjligt att definiera neuroner utan mättnad, med en kontinuerlig uppsättning värden vid utgången. I klassificeringsproblem kan utgångsvärdet bestämmas av en tröskel - när man fattar ett enda beslut - eller vara sannolikhet - när man bestämmer klasstillhörighet. För att ta hänsyn till detaljerna för en specifik uppgift kan olika andra typer av aktiveringsfunktioner väljas - Gaussisk, sinusformad, vågor, etc.
NEURALA NÄTVERK FÖR DIREKT KOMMUNIKATION
Vi kommer att överväga två typer av neurala nätverk: statiska, som också ofta kallas feed-forward-nätverk, och dynamiska eller återkommande nätverk. I det här avsnittet kommer vi att ta itu med statiska nätverk. Andra typer av nätverk kommer att diskuteras kort senare.
Feedforward neurala nätverk är sammansatta av statiska neuroner, så att signalen vid utgången av nätverket visas i samma ögonblick som ingångssignalerna ges. Organisationen (topologin) av nätverket kan vara annorlunda. Om inte alla dess ingående neuroner matas ut, sägs nätverket innehålla dolda neuroner. Den mest allmänna typen av nätverksarkitektur erhålls när alla neuroner är anslutna till varandra (men utan återkopplingar). V specifika uppgifter neuroner är vanligtvis grupperade i lager. I fig. Figur 13.2 visar ett typiskt neuralt nätverk för feed-forward med ett dolt lager.
Det är intressant att notera att, enligt teoretiska resultat, är neurala nätverk med feedforward- och sigmoidfunktioner ett universellt verktyg för approximation (approximation) av funktioner. Närmare bestämt kan vilken verkligt värderad funktion som helst av flera variabler på en kompakt definitionsdomän approximeras så noggrant som önskas med hjälp av ett treskiktsnätverk. Samtidigt vet vi dock varken storleken på nätverket som kommer att krävas för detta, eller vikternas värden. Dessutom kan det ses från beviset för dessa resultat att antalet dolda element ökar oändligt med en ökning av noggrannheten hos approximationen. Feedforward-nätverk kan verkligen fungera som ett universellt approximationsverktyg, men det finns ingen regel för att hitta den optimala nätverkstopologin för en given uppgift.
Uppgiften att bygga ett neuralt nätverk är alltså inte trivial. Frågor om hur många dolda lager som ska tas, hur många element som finns i var och en av dem, hur många länkar och vilka träningsparametrar, i den tillgängliga litteraturen, tolkas vanligtvis lätt.
På träningsstadiet beräknas synaptiska koefficienter i processen att lösa uppgifter av det neurala nätverket (klassificering, förutsägelse av tidsserier, etc.), där det önskade svaret inte bestäms av reglerna, utan med hjälp av exempel grupperade i träningsuppsättningar... En sådan uppsättning består av ett antal exempel med värdet på utgångsparametern angivet för vart och ett av dem, som det skulle vara önskvärt att få. De åtgärder som inträffar i det här fallet kan kallas övervakat lärande: "Läraren" matar en vektor av initiala data till nätverkets ingång och rapporterar det önskade värdet av beräkningsresultatet till utmatningsnoden. Övervakad inlärning av ett neuralt nätverk kan ses som en lösning på ett optimeringsproblem. Dess syfte är att minimera felfunktionen, eller resterande, E på denna uppsättning exempel genom att välja värdena för vikterna W.
FELKRITERIER
Målet med minimeringsproceduren är att hitta ett globalt minimum - dess uppnående kallas inlärningsprocessens konvergens. Eftersom återstoden beror på vikterna olinjärt är det omöjligt att få en lösning i analytisk form, och sökandet efter det globala minimumet genomförs genom en iterativ process - den s.k. inlärningsalgoritm, som undersöker restens yta och försöker hitta en global minimipunkt på den. Vanligtvis tas medelkvadratfelet (MSE) som ett mått på fel, vilket definieras som summan av kvadraterna av skillnaderna mellan det önskade utdatavärdet med formeln "src =" http://hi-edu.ru /e-books/xbook725/files/22.gif " border = "0" align = "absmiddle" alt = "(! LANG:för varje exempel till.
exempel "> efter maximal sannolikhetskriteriet:
exempel ">" epoker "). Vikterna ändras i motsatt riktning till den brantaste riktningen för kostnadsfunktionen:
är en användardefinierad parameter som kallas av gradientstegets storlek eller inlärningsfaktorn.
En annan möjlig metod kallas stokastisk gradient.
I den räknas vikterna om efter varje beräkning av alla exempel från en träningsuppsättning, och samtidigt används en delkostnadsfunktion motsvarande denna, till exempel, k-th, set:
undertext ">
TILBAKSPRIDNING AV FELET
Tänk nu på den vanligaste inlärningsalgoritmen för neurala nätverk för feedforward - algoritm för återförökning(Backpropagation, BP), vilket är utvecklingen av den sk generaliserad deltaregel... Denna algoritm återupptäcktes och populariserades 1986 av Rumelhart och McCleland från berömd grupp om studiet av parallella distribuerade processer vid Massachusetts Institute of Technology. I det här avsnittet kommer vi att titta närmare på den matematiska essensen av algoritmen. Det är en gradient descent-algoritm som minimerar det totala kvadratiska felet:
formeln "src =" http://hi-edu.ru/e-books/xbook725/files/24.gif "border =" 0 "align =" absmiddle "alt =" (! LANG:... Beräkningen av partiella derivator utförs enligt kedjeregeln: vikten av ingången av den j:te neuronen som kommer från den j:te neuronen omräknas med formeln
formeln "src =" http://hi-edu.ru/e-books/xbook725/files/23.gif "border =" 0 "align =" absmiddle "alt =" (! LANG:- längden på steget i motsatt riktning mot lutning.
Om vi betraktar det k:te provet separat, är motsvarande förändring i vikter
beräknas genom liknande faktorer från nästa lager, och felet överförs alltså i motsatt riktning.
För utdataelementen får vi:
formeln "src =" http://hi-edu.ru/e-books/xbook725/files/25.gif "border =" 0 "align =" absmiddle "alt =" (! LANG:definieras så här:
formeln "src =" http://hi-edu.ru/e-books/xbook725/files/13.14.gif "border =" 0 "align =" absmiddle "alt =" (! LANG:(13.14)
vi får:
exempel "> i den stokastiska versionen räknas vikterna om varje gång efter att nästa prov har beräknats, och i den" epokgörande "eller offline-versionen ändras vikterna efter att hela träningssetet har beräknats.
En annan ofta använd teknik är att när man bestämmer sökningens riktning läggs en ändring till den aktuella gradienten - förskjutningsvektorn för föregående steg, taget med en viss koefficient. Vi kan säga att den redan existerande rörelseimpulsen beaktas. Den slutliga formeln för att ändra vikterna ser ut så här:
formeln "src =" http://hi-edu.ru/e-books/xbook725/files/26.gif "border =" 0 "align =" absmiddle "alt =" (! LANG:- ett nummer i intervallet (0,1), som ställs in av användaren.
Ofta betydelsen av undertexten ">
ANDRA LÄRANDEALGORITMER
Slutligen den sk genetiska algoritmer, där en uppsättning vikter betraktas som en individ som är föremål för mutationer och korsning, och felkriteriet tas som en indikator på dess "kvalitet". När nya generationer växer fram blir det mer sannolikt att en optimal individ kommer att växa fram.
I finansiella applikationer är data särskilt bullriga. Till exempel kan utförandet av transaktioner registreras i databasen med en fördröjning, och i olika fall med olika. Saknade värden eller inte fullständig information kallas också ibland för brus: i sådana fall tas det genomsnittliga eller bästa värdet, och detta leder naturligtvis till databasbrus. Den felaktiga definitionen av objektklassen i igenkänningsproblem har en negativ effekt på inlärningen - detta försämrar systemets förmåga att generalisera när man arbetar med nya (d.v.s. inte inkluderade i antalet prov) objekt.
KORSBEKRÄFTELSE
Upprepade samplingstekniker kan användas för att eliminera godtycklighet i databaspartitionering. Överväg en av dessa metoder, som kallas korsbekräftelse... Dess idé är att slumpmässigt dela upp databasen i q parvis osammanhängande delmängder. Sedan utförs q-träningar på (q -1) set, och felet beräknas över den återstående uppsättningen. Om q är tillräckligt stor, till exempel lika med 10, använder varje träning det mesta av originaldata. Om inlärningsproceduren är tillförlitlig bör resultaten för q olika modeller ligga mycket nära varandra. Därefter bestäms den slutliga karakteristiken som medelvärdet av alla erhållna felvärden. Tyvärr, när man tillämpar denna metod, är mängden beräkning ofta mycket stor, eftersom det krävs för att göra q utbildningar, och i en verklig applikation med en större dimension kanske detta inte är genomförbart. I begränsningsfallet när q = P, där P är det totala antalet exempel, kallas metoden för korsvalidering med en rest. Denna uppskattningsmetod har en bias, och en metod har utvecklats "hopfällbar kniv" minska denna nackdel till bekostnad av ännu mer beräkning.
Nästa klass av neurala nätverk som vi kommer att överväga är dynamiska, eller återkommande, nätverk. De är byggda av dynamiska neuroner, vars beteende beskrivs av differential- eller differensekvationer, vanligtvis av första ordningen. Nätverket är organiserat på ett sådant sätt att varje neuron får indata från andra neuroner (eventuellt från sig själv) och från omgivningen. Denna typ av nätverk är viktig eftersom den kan användas för att modellera olinjära dynamiska system. Det är mycket allmän modell som potentiellt kan användas mest olika applikationer till exempel: associativt minne, icke-linjär signalbehandling, finita tillståndsmaskinmodellering, systemidentifiering, kontrollproblem.
Tidsfördröjning neurala nätverk
Innan du beskriver själva de dynamiska nätverken, överväg hur feedforward-nätverket används för att bearbeta tidsserier. Metoden består i att bryta upp tidsserien i flera segment och på så sätt erhålla ett statistiskt urval för att mata ingången från ett flerlagers feedforward-nätverk. Detta görs med hjälp av en så kallad gaffelfördröjningslinje (se figur 13.3).
Arkitekturen för ett sådant neuralt nätverk med en tidsfördröjning tillåter modellering av vilket ändligt tidsberoende som helst av formen:
undertext ">
HOPFIELD NÄTVERK
Med hjälp av Hopfields återkommande nätverk kan du bearbeta oordnade (handskrivna bokstäver), ordnade i tid (tidsserier) eller rumsmönster (grafer, grammatik) (Fig. 13.4). Det enklaste återkommande neurala nätverket introducerades av Hopfield; den är uppbyggd av N neuroner, var och en ansluten till var och en, och alla neuroner produceras.
Nätverk av denna design används huvudsakligen som associativt minne, såväl som i problem med olinjär datafiltrering och grammatisk slutledning. Dessutom har de nyligen använts för att förutsäga och känna igen mönster i aktiekursernas beteende.
Den "självorganiserande särdragskartan" introducerad av Kohonen kan ses som en variant av ett neuralt nätverk. Denna typ av nätverk är designad för självutbildning: Det är inte nödvändigt att ge henne de rätta svaren under träningen. I inlärningsprocessen matas olika mönster till nätverksingången. Nätverket fångar särdragen i deras struktur och delar upp proverna i 436 kluster, och det redan erhållna nätverket tilldelar varje nyanlända exempel till ett av klustren, styrt av något kriterium om "närhet".
Nätverket består av ett ingångs- och ett utgångsskikt. Antalet element i utdatalagret avgör direkt hur många kluster nätverket kan känna igen. Vart och ett av utgångselementen tar emot hela ingångsvektorn som inmatning. Som med alla neurala nätverk tilldelas viss synoptisk vikt till varje anslutning. I de flesta fall är varje utgångselement också anslutet till sina grannar. Dessa interna kopplingar spelar en viktig roll i inlärningsprocessen, eftersom vikterna justeras endast i närheten av det element som det bästa sättet svarar på nästa inlägg.
Outputelement tävlar sinsemellan om rätten att gå till handling och "lära sig en läxa". Vinnaren är den vars viktvektor är närmast ingångsvektorn i betydelsen av avståndet som bestäms till exempel av den euklidiska metriken. Det vinnande elementet kommer att ha detta avstånd mindre än alla andra. Vid det aktuella träningssteget är det bara det vinnande elementet (och kanske dess närmaste grannar) tillåtet att ändra vikterna; vikten av de återstående elementen är så att säga frysta. Det vinnande föremålet ersätter sin viktvektor genom att flytta det något mot ingångsvektorn. Efter att ha tränat på ett tillräckligt antal exempel, matchar uppsättningen viktvektorer mer exakt strukturen för ingångsexemplen - viktvektorerna modellerar bokstavligen fördelningen av ingångsproverna.

Ris. 13.5. Självorganiserande Kohonen-nätverk. Bara länkar som går till i-te noden... Närheten till noden visas med en prickad linje
Uppenbarligen, för att nätverket ska förstå ingångsfördelningen korrekt, är det nödvändigt att varje nätverkselement blir en vinnare lika många gånger - viktvektorerna måste vara lika sannolikt.
Innan du startar Kohonen-nätverket måste två saker göras:
kvantitetens vektorer måste vara slumpmässigt fördelade över enhetssfären;
alla vikt- och ingångsvektorer måste normaliseras till en.
Motförökande nätverk(CPN, Counterpropagation Network) kombinerar egenskaperna hos Kohonens självorganiserande nätverk och konceptet Oustar – Grossberg-nätverket. Inom ramen för denna arkitektur har elementen i Kohonen nätverkslagret inte ett direkt utlopp till yttre världen, och tjänar som indata för utgångsskiktet, i vilket Grossberg-vikterna är adaptivt tilldelade länkarna. Detta schema uppstod från Hecht-Nielsens arbete. CPN-nätverket syftar till att gradvis bygga den önskade mappningen av ingångar till utgångar baserat på exempel på verkan av en sådan mappning. Nätverket är bra på att lösa problem där det krävs förmåga att adaptivt bygga matematisk reflektion utifrån dess exakta värden på enskilda punkter.
Nätverk av denna typ används framgångsrikt i sådana finansiella och ekonomiska tillämpningar som att granska låneansökningar, förutsäga trender i aktiekurser, råvaror och växelkurser. Generellt sett kan man förvänta sig framgångsrik tillämpning av CPN-nätverk i uppgifter där det krävs att extrahera kunskap från stora mängder data.
PRAKTISK TILLÄMPNING AV NEURAL NÄTVERK FÖR KLASSIFICERING (KLUSTERISERING) UPPGIFTER
Lösningen på klassificeringsproblemet är en av kritiska applikationer neurala nätverk. Klassificeringsproblemet är problemet med att tilldela ett sampel till en av flera parvis osammanhängande uppsättningar. Ett exempel på sådana problem kan till exempel vara problemet med att fastställa kreditvärdigheten hos en bankklient, medicinska problem där det är nödvändigt att bestämma till exempel resultatet av en sjukdom, lösa problem med att hantera en portfölj av värdepapper ( sälja, köpa eller "hålla" aktier beroende på marknadssituationen), uppgiften att identifiera livskraftiga och konkursbenägna företag.
SYFTE MED KLASSIFICERING
Vid lösning av klassificeringsproblem är det nödvändigt att ta med det befintliga statiska prover(kännetecken på marknadssituationen, läkarundersökningsdata, kundinformation) till vissa klasser... Flera sätt att presentera data är möjliga. Det vanligaste sättet är att provet representeras som en vektor. Komponenterna i denna vektor representerar olika egenskaper hos ett prov som påverkar beslutet om vilken klass ett givet prov ska tilldelas. Till exempel, för medicinska problem, kan komponenterna i denna vektor vara data från en patients journal. Baserat på viss information om exemplet är det alltså nödvändigt att bestämma vilken klass det kan hänföras till. Klassificeraren klassificerar alltså ett objekt i en av klasserna i enlighet med en viss uppdelning av det N-dimensionella rummet, vilket kallas entréutrymme, och dimensionen för detta utrymme är antalet vektorkomponenter.
Först och främst måste du bestämma nivån på systemets komplexitet. I verkliga problem uppstår ofta en situation när antalet prover är begränsat, vilket komplicerar bestämningen av problemets komplexitet. Det är möjligt att urskilja tre huvudsakliga svårighetsgrader. Den första (enklaste) är när klasserna kan separeras med raka linjer (eller hyperplan, om inmatningsutrymmet har en dimension större än två) - den s.k. linjär separerbarhet... I det andra fallet kan klasserna inte separeras med linjer (plan), men det är möjligt att separera dem med en mer komplex division - icke-linjär separerbarhet... I det tredje fallet överlappar klasserna, och vi kan bara prata om probabilistisk separerbarhet.

Ris. 13.6. Linjärt och icke-linjärt separerbara klasser
Helst bör vi efter förbearbetning få ett linjärt separerbart problem, eftersom konstruktionen av klassificeraren efter det är mycket förenklad. Tyvärr, när vi löser verkliga problem, har vi ett begränsat antal prover, på grundval av vilka klassificeraren är byggd. Samtidigt kan vi inte utföra sådan förbearbetning av data där linjär separerbarhet av proverna kommer att uppnås.
ANVÄNDNING AV NEURALNÄTVERK SOM KLASSIFICERING
Feedforward-nätverk är ett universellt verktyg för att approximera funktioner, vilket gör att de kan användas för att lösa klassificeringsproblem. Som regel visar sig neurala nätverk vara den mest effektiva metoden för klassificering, eftersom de faktiskt genererar ett stort antal regressionsmodeller (som används för att lösa klassificeringsproblem med statistiska metoder).
Tyvärr uppstår ett antal problem vid tillämpningen av neurala nätverk i praktiska uppgifter. För det första är det inte känt i förväg vilken komplexitet (storlek) nätverket kan kräva för att implementera mappningen tillräckligt exakt. Denna komplexitet kan vara oöverkomlig och kräver komplex nätverksarkitektur. Således bevisade Minsky i sitt arbete "Perceptrons" att de enklaste enskiktiga neurala nätverken bara kan lösa linjärt separerbara problem. Denna begränsning kan övervinnas genom att använda flerskiktiga neurala nätverk. V allmän syn vi kan säga att i ett nätverk med ett dolt lager, omvandlas vektorn som motsvarar inmatningsmönstret av det dolda lagret till något nytt utrymme, som kan ha en annan dimension, och sedan delar sig hyperplanen som motsvarar neuronerna i utdatalagret. det in i klasser. Nätverket känner således inte bara igen egenskaperna hos originaldata, utan också de "karakteristika egenskaper" som bildas av det dolda lagret.
FÖRBEREDELSE AV INLEDANDE DATA
För att bygga en klassificerare är det nödvändigt att bestämma vilka parametrar som påverkar beslutet om vilken klass ett prov tillhör. Detta kan orsaka två problem. För det första, om antalet parametrar är litet, kan en situation uppstå där samma uppsättning initiala data motsvarar exempel i olika klasser. Då är det omöjligt att träna det neurala nätverket, och systemet kommer inte att fungera korrekt (det är omöjligt att hitta ett minimum som motsvarar en sådan uppsättning initiala data). De initiala uppgifterna måste vara konsekventa. För att lösa detta problem är det nödvändigt att öka dimensionen av funktionsutrymmet (antalet komponenter i ingångsvektorn som motsvarar provet). Men med en ökning av dimensionen av funktionsutrymmet kan en situation uppstå när antalet exempel kan bli otillräckligt för att träna nätverket, och istället för att generalisera kommer det helt enkelt att komma ihåg exempel från träningsuppsättningen och inte kunna fungera korrekt. . Sålunda, när du identifierar funktioner, är det nödvändigt att hitta en kompromiss med deras nummer.
Därefter måste du bestämma sättet att representera indata för det neurala nätverket, dvs. bestämma ransoneringsmetoden. Normalisering är nödvändig, eftersom neurala nätverk arbetar med data som representeras av siffror i intervallet 0..1, och de initiala data kan ha ett godtyckligt intervall eller till och med vara icke-numeriska data. I det här fallet är olika metoder möjliga, allt från en enkel linjär transformation till det erforderliga området och slutar med multivariat analys av parametrar och olinjär normalisering, beroende på parametrarnas inverkan på varandra.
UTGÅNGSKODNING
Klassificeringsproblemet i närvaro av två klasser kan lösas i ett nätverk med en neuron i utgångsskiktet, som kan ta ett av två värden 0 eller 1, beroende på vilken klass provet tillhör. När det finns flera klasser är det problem med presentationen av dessa data för nätverksutgången. Mest på ett enkelt sätt representation av utdata i detta fall är en vektor, vars komponenter motsvarar olika nummer klasser. Vart i i-te komponenten vektorn motsvarar den i:e klassen. I detta fall är alla andra komponenter satta till 0. Då kommer till exempel den andra klassen att motsvara 1 vid 2 nätverksutgångar och 0 vid resten. Vid tolkning av resultatet brukar man anta att klassnumret bestäms av numret på det nätverksuttag på vilket maxvärdet förekom. Till exempel, om vi i ett nätverk med tre utgångar har en vektor med utgångsvärden (0,2; 0,6; 0,4), och vi ser att den andra komponenten i vektorn har det maximala värdet, då klassen till vilken detta exempel tillhör är 2 Denna kodningsmetod introducerar ibland föreställningen om nätverkets förtroende för att ett exempel tillhör denna klass. Det enklaste sättet att bestämma konfidens är att bestämma skillnaden mellan den maximala uteffekten och den andra uteffekten som är närmast maximum. Till exempel, för exemplet ovan, bestäms nätverkets förtroende för att exemplet tillhör den andra klassen som skillnaden mellan vektorns andra och tredje komponenter och är lika med 0,6-0,4 = 0,2. Följaktligen, ju högre förtroende, desto mer sannolikt är det att nätverket har gett rätt svar. Denna kodningsmetod är det enklaste, men inte alltid det bästa sättet att representera data.
Andra metoder är också kända. Till exempel är utdatavektorn klusternumret skrivet i binär form. Sedan, om det finns 8 klasser, behöver vi en vektor med 3 element, och säg, klass 3 kommer att motsvara vektor 011. Men samtidigt, om ett felaktigt värde tas emot vid en av utgångarna, kan vi få ett felaktig klassificering (felaktigt klusternummer), så det är vettigt att öka avståndet mellan två kluster genom att använda Hamming-kodning, vilket kommer att öka klassificeringens tillförlitlighet.
Ett annat tillvägagångssätt är att dela upp problemet med k klasser i k * (k-l) / 2 underproblem med två klasser (2 gånger 2 kodning) vardera. I det här fallet innebär en deluppgift att nätverket bestämmer närvaron av en av vektorkomponenterna. De där. den ursprungliga vektorn är uppdelad i grupper av två komponenter var och en på ett sådant sätt att de inkluderar alla möjliga kombinationer av komponenterna i utvektorn. Antalet av dessa grupper kan definieras som antalet oordnade prover av två från originalkomponenterna.
352 "gräns =" 0 ">
Där 1 vid utgången indikerar närvaron av en av komponenterna. Sedan kan vi gå till klassnumret enligt resultatet av beräkningen av nätverket enligt följande: vi bestämmer vilka kombinationer som fick ett enda (mer exakt, nära ett) utdatavärde (dvs. vilka deluppgifter som aktiverades för oss), och vi anta att klassnumret kommer att vara det som angett flest antal aktiverade deluppgifter (se tabell).
namnlöst dokument
Denna kodning i många uppgifter ger ett bättre resultat än den klassiska kodningsmetoden.
SANNOLIKHETSKLASSIFICERING
Vid statistisk mönsterigenkänning hänvisar den optimala klassificeraren till provet med formeln "src =" http://hi-edu.ru/e-books/xbook725/files/1.gif "border =" 0 "align =" absmiddle "alt =" (! LANG:
tillskriv formeln "src =" http://hi-edu.ru/e-books/xbook725/files/4.gif "border =" 0 "align =" absmiddle "alt =" (! LANG:avser gruppen med högst posterior sannolikhet. Denna regel är optimal i den meningen att den minimerar det genomsnittliga antalet felklassificeringar..gif "border =" 0 "align =" absmiddle "alt =" (! LANG:
då förblir den bayesianska relationen mellan föregående och bakre sannolikheter giltig, och därför kan dessa funktioner användas som förenklade beslutsfunktioner... Det är vettigt att göra detta om dessa funktioner byggs och beräknas enklare.
Även om regeln ser väldigt enkel ut, visar det sig vara svårt att tillämpa den i praktiken, eftersom posteriora sannolikheter (eller till och med värdena för förenklade beslutsfunktioner) är okända. Deras värden kan uppskattas. I kraft av Bayes sats kan posteriora sannolikheter uttryckas i termer av tidigare sannolikheter och densitetsfunktioner med hjälp av formeln "src =" http://hi-edu.ru/e-books/xbook725/files/8.gif "border =" 0 "align = "absmiddle" alt = "(! LANG:.
KLASSIFIERARE AV BILDER
Den tidigare sannolikhetstätheten kan uppskattas olika sätt... V parametriska metoder det antas att sannolikhetstätheten (PDF) är en funktion av ett visst slag med okända parametrar. Du kan till exempel försöka zooma in på en PDF med en Gaussisk funktion. För att göra klassificeringen måste du först få de uppskattade värdena för medelvektorn och kovariansmatrisen för var och en av dataklasserna och sedan använda dem i beslutsregeln. Resultatet är en polynombeslutsregel som endast innehåller kvadrater och parvisa produkter av variabler. Hela proceduren som beskrivs kallas kvadratisk diskriminantanalys(QDA). Under antagandet att kovariansmatriserna är desamma för alla klasser, minskar QDA till linjär diskriminantanalys(LDA).
I metoder av annan typ - icke-parametrisk- inga preliminära antaganden om sannolikhetstätheten krävs. Metoden "till närmaste grannar" (NN) beräknar avståndet mellan det nyinkomna provet och träningssetets vektorer, varefter provet tillhör den klass som de flesta av dess närmaste grannar tillhör. Som ett resultat är gränserna som separerar klasserna bitvis linjära. Olika modifieringar av denna metod använder olika avståndsmått och speciella tekniker för att hitta grannar. Ibland, istället för själva uppsättningen av prover, tas en uppsättning centroider, motsvarande kluster i den adaptiva vektorkvantiseringsmetoden (LVQ).
I andra metoder delar klassificeraren upp data i grupper enligt trädschemat. Vid varje steg delas undergruppen i två, och resultatet är en hierarkisk struktur av ett binärt träd. Separerande gränser erhålls som regel styckvis linjära och motsvarar klasser som består av ett eller flera blad av trädet. Det som är bra med denna metod är att den genererar en klassificeringsmetod baserad på logiska beslutsregler. Idéerna med trädliknande klassificerare används i metoder för att konstruera självväxande neurala klassificerare.
NEURALNÄTVERK MED DIREKT KOMMUNIKATION SOM KLASSIFICERARE
Eftersom feedforward-nätverk är ett universellt sätt att approximera funktioner, kan de användas för att uppskatta de bakre sannolikheterna i ett givet klassificeringsproblem. På grund av flexibiliteten i konstruktionen av kartläggningen är det möjligt att uppnå en sådan noggrannhet av approximationen av posteriora sannolikheter att de praktiskt taget sammanfaller med värdena beräknade enligt Bayes regel (de så kallade optimala klassificeringsprocedurerna.
TIDSERIEN ANALYS PROBLEM
En tidsserie är en ordnad sekvens av reella tal formeln "src =" http://hi-edu.ru/e-books/xbook725/files/10.gif "border =" 0 "align =" absmiddle "alt = "(! LANG:i n-dimensionellt utrymme av tidsförskjutna värden, eller fördröjningsutrymme.
Syftet med tidsserieanalys är att extrahera användbar information från en given serie. För detta är det nödvändigt att bygga en matematisk modell av fenomenet. En sådan modell bör förklara essensen av processen som genererar data, i synnerhet beskriva karaktären av data (slumpmässig, trendmässig, periodisk, stationär, etc.). Efter det kan du tillämpa olika metoder för datafiltrering (utjämning, borttagning av extremvärden, etc.) med det slutliga målet - att förutsäga framtida värden.
Detta tillvägagångssätt bygger alltså på antagandet att tidsserien har någon matematisk struktur (som t.ex. kan vara en konsekvens av fenomenets fysiska natur). Denna struktur finns i den sk fasutrymme, vars koordinater är oberoende variabler som beskriver det dynamiska systemets tillstånd. Därför är den första uppgiften som måste ställas inför i simuleringen att bestämma fasutrymmet på lämpligt sätt. För att göra detta måste du välja några egenskaper hos systemet som fasvariabler. Efter det är det redan möjligt att ta upp frågan om förutsägelse eller extrapolering. I de tidsserier som erhålls som ett resultat av mätningar förekommer som regel slumpmässiga fluktuationer och brus i olika proportioner. Därför bestäms kvaliteten på en modell till stor del av dess förmåga att approximera den avsedda datastrukturen genom att separera den från brus.
STATISTISK ANALYS AV TIDSERIER
En detaljerad beskrivning av metoder för statistisk tidsserieanalys ligger utanför denna bok. Vi kommer kort att överväga traditionella tillvägagångssätt, samtidigt som vi lyfter fram de omständigheter som är direkt relaterade till ämnet för vår presentation. Sedan Yules banbrytande arbete har linjära ARIMA-modeller tagit centrala scenen i statistisk tidsserieanalys. Med tiden har detta område utvecklats till en komplett teori med en uppsättning metoder - Box-Jenkins teorin.
Närvaron av en autoregressiv term i ARIMA-modellen uttrycker det faktum att de nuvarande värdena för en variabel beror på dess tidigare värden. Sådana modeller kallas endimensionella. Ofta är dock värdena för målvariabeln som studeras associerade med flera olika tidsserier.

Ris. 13.7. Implementering av ARIMA (p, q) modell på det enklaste neurala nätverket
Detta skulle till exempel vara fallet om målvariabeln är växelkursen och de andra variablerna är räntor (i var och en av de två valutorna).
Motsvarande metoder kallas flerdimensionella. Den matematiska strukturen för linjära modeller är ganska enkel, och beräkningar på dem kan utföras utan några speciella svårigheter med standardpaket med numeriska metoder. Nästa steg i tidsserieanalys var utvecklingen av modeller som kan ta hänsyn till de olinjäriteter som vanligtvis finns i verkliga processer och system. En av de första sådana modellerna föreslogs av Tong och kallas den tröskel autoregressiva modellen (TAR).
Den växlar från en linjär AR-modell till en annan när vissa (förinställda) tröskelvärden nås. Således särskiljs flera driftlägen i systemet.
Då föreslås STAR eller "släta" TAR-modeller. En sådan modell är en linjär kombination av flera modeller tagna med koefficienter som är kontinuerliga funktioner av tiden.
MODELLER BASERADE PÅ NEURALA NÄTVERK FÖR DIREKTA KOMMUNIKATION
Det är konstigt att notera att alla modeller som beskrivs i föregående stycke kan implementeras med hjälp av neurala nätverk. Eventuellt beroende av formen
urval "> fig. 13.8
Handlingar till en början scen-scen NS förbearbetning av data- uppenbarligen starkt beroende av uppgiftens särdrag. Det är nödvändigt att korrekt välja antalet och typen av indikatorer som kännetecknar processen, inklusive strukturen för förseningar. Efter det måste du välja nätverkstopologi. Om feedforward-nätverk används måste antalet dolda element bestämmas. Vidare, för att hitta parametrarna för modellen, måste du välja ett felkriterium och en optimerande (tränings)algoritm. Sedan, med hjälp av diagnostiska verktyg, bör du kontrollera modellens olika egenskaper. Slutligen måste du tolka utdata från nätverket och kanske mata det till input från något annat beslutsstödssystem. Därefter kommer vi att överväga de problem som måste lösas i stadierna av förbearbetning, optimering och analys (felsökning) av nätverket.
DATAINSAMLING
Det viktigaste beslutet en analytiker måste fatta är valet av en uppsättning variabler för att beskriva processen som modelleras. För att föreställa dig möjliga samband mellan olika variabler behöver du ha en god förståelse för problemets väsen. I detta avseende kommer det att vara mycket användbart att prata med en erfaren specialist inom detta ämnesområde. När det gäller de variabler du väljer måste du förstå om de är signifikanta i sig själva, eller om de bara återspeglar andra, riktigt signifikanta variabler. Signifikanstestning inkluderar korskorrelationsanalys. Med dess hjälp är det till exempel möjligt att avslöja en tillfällig anslutning av typen av fördröjning (lag) mellan två rader. I vilken utsträckning ett fenomen kan beskrivas med en linjär modell testas med minsta kvadratregression (OLS).
Undertextrester erhålls efter optimering ">
NEURALNÄTVERK SOM ETT MEDEL FÖR DATAUTHANDLING
Ibland uppstår problemet med att analysera data som knappast kan representeras i matematisk numerisk form. Detta är ett fall när du behöver extrahera data, vars urvalsprinciper inte är tydligt definierade: välj pålitliga partners, identifiera en lovande produkt, etc. Låt oss överväga en typisk situation för uppgifter av detta slag - förutsägelse av konkurser. Anta att vi har information om flera dussin bankers verksamhet (deras öppna bokslut) under en viss tidsperiod. I slutet av denna period vet vi vilka av dessa banker som gick i konkurs, vilka fick sina licenser indragna och vilka som fortsatte att fungera stabilt (i slutet av perioden). Och nu måste vi bestämma vilken av bankerna som är värda att placera medel. Naturligtvis är det osannolikt att vi vill placera medel i en bank som snart kan gå i konkurs. Det betyder att vi på något sätt måste lösa problemet med att analysera riskerna med investeringar i olika kommersiella strukturer.
Vid första anblicken är det inte svårt att lösa detta problem - trots allt har vi data om bankernas arbete och resultaten av deras verksamhet. Men i själva verket är denna uppgift inte så enkel. Ett problem uppstår relaterat till att de uppgifter vi har beskriver den gångna perioden, och vi är intresserade av vad som kommer att hända i framtiden. Vi behöver alltså få en prognos för nästa period baserat på de a priori-data vi har. Olika metoder kan användas för att utföra denna uppgift.
Så det mest uppenbara är användningen av metoder för matematisk statistik. Men här finns det ett problem med mängden data, eftersom statistiska metoder fungerar bra med en stor mängd a priori-data, och vi kan ha ett begränsat antal av dem. Statistiska metoder kan dock inte garantera ett framgångsrikt resultat.
Ett annat sätt att lösa detta problem kan vara användningen av neurala nätverk, som kan tränas på den tillgängliga datamängden. I det här fallet används uppgifterna från olika bankers finansiella rapporter som den initiala informationen, och resultatet av deras aktiviteter används som målfält. Men när vi använder metoderna som beskrivs ovan, påtvingar vi resultatet utan att försöka hitta mönster i originaldata. I princip liknar alla bankrutta banker varandra, om så bara genom att de gått i konkurs. Det betyder att det i deras verksamhet måste finnas något mer generellt, som ledde dem till detta resultat, och man kan försöka hitta dessa mönster för att använda dem i framtiden. Och här står vi inför frågan om hur man hittar dessa mönster. För detta, om vi använder statistiska metoder, måste vi bestämma vilka kriterier för "likhet" vi använder, vilket kan kräva att vi har ytterligare kunskap om problemets natur.
Det finns dock en metod som gör det möjligt att automatisera alla dessa åtgärder för att hitta mönster – en analysmetod som använder sig av självorganiserande Kohonen-kartor. Fundera på hur sådana problem löses och hur Kohonens kartor hittar mönster i den initiala datan. För allmän övervägande kommer vi att använda termen objekt (till exempel kan ett objekt vara en bank, som i exemplet ovan, men den beskrivna metodiken utan ändringar är lämplig för att lösa andra problem, till exempel att analysera en kunds kreditvärdighet, hitta en optimal strategi för beteende på marknaden etc. ). Varje objekt kännetecknas av en uppsättning olika parametrar som beskriver dess tillstånd. Till exempel, för vårt exempel, kommer parametrarna att vara data från finansiella rapporter. Dessa parametrar är ofta numeriska eller kan reduceras till det. Baserat på analysen av parametrarna för objekt måste vi alltså välja liknande objekt och presentera resultatet i en form som är bekväm för uppfattning.
Alla dessa uppgifter löses genom att självorganisera Kohonen-kartor. Låt oss titta närmare på hur de fungerar. För att förenkla övervägandet kommer vi att anta att objekt har 3 funktioner (i själva verket kan det finnas hur många som helst).
Föreställ dig nu att alla dessa tre parametrar för objekt representerar deras koordinater i det tredimensionella rummet (i samma utrymme som omger oss i Vardagsliv). Sedan kan varje objekt representeras som en punkt i detta utrymme, vilket vi kommer att göra (för att vi inte ska ha problem med olika skalor längs axlarna, kommer vi att numrera alla dessa tecken i ett intervall av ev. på lämpligt sätt), som ett resultat av vilket alla punkter faller in i en kub av enhetsstorlek i fig. 13.9. Låt oss visa dessa punkter. När vi tittar på denna figur kan vi se hur objekt befinner sig i rymden, och det är lätt att lägga märke till områden där objekt är grupperade, d.v.s. de har liknande parametrar, vilket betyder att dessa objekt själva, troligen, tillhör samma grupp. Vi måste hitta ett sätt att transformera detta system in i ett lättförståeligt, helst tvådimensionellt system (eftersom redan en tredimensionell bild inte kan visas korrekt på ett plan) så att objekt intill det önskade utrymmet finns i närheten och på den resulterande bilden. För detta använder vi en självorganiserande Kohonen-karta. Som en första approximation kan den representeras som ett nät av gummi, Fig. 13.10.
Vi, som tidigare har "krympt ihop", kastar detta nätverk i utrymmet med funktioner, där vi redan har objekt, och fortsätter sedan enligt följande: vi tar ett objekt (en punkt i detta utrymme) och hittar den närmaste nätverksnoden till det. Efter det dras denna knut upp till föremålet (eftersom nätet är "gummi" dras tillsammans med denna knut de närliggande noderna upp på samma sätt, men med mindre kraft).
Sedan väljs ett annat objekt (punkt) och proceduren upprepas. Som ett resultat får vi en karta, vars nodernas placering sammanfaller med platsen för huvudklustren av objekt i det ursprungliga utrymmet i fig. 13.11. Dessutom har den resulterande kartan följande anmärkningsvärda egenskap - dess noder är placerade på ett sådant sätt att intilliggande kartnoder motsvarar objekt som liknar varandra. Nu bestämmer vi vilka objekt vi fick in i vilka noder på kartan. Det bestäms också av den närmaste noden - objektet faller in i den nod som är närmare den. Som ett resultat av alla dessa operationer kommer objekt med liknande parametrar att hamna i en nod eller i angränsande noder. Således kan vi anta att vi kunde lösa problemet med att hitta liknande föremål och deras gruppering.
Men möjligheterna med Kohonens kort slutar inte där. De låter dig också presentera den mottagna informationen i en enkel och visuell form genom att använda färg. För att göra detta färgar vi den resulterande kartan (mer exakt, dess noder) med färger som motsvarar egenskaperna hos objekt av intresse för oss. För att återgå till exemplet med klassificeringen av banker kan du färglägga de noder där minst en av bankerna vars licens har återkallats kan färgas med en färg. Sedan, efter att ha applicerat färgningen, kommer vi att få en zon som kan kallas en riskzon, och om banken av intresse för oss faller in i denna zon, indikerar det dess opålitlighet.
Men det är inte allt. Vi kan också få information om beroenden mellan parametrar. Genom att sätta på kartan en färgsättning som motsvarar olika artiklar av rapporter kan du få en så kallad atlas, som lagrar information om marknadsläget. När man analyserar, jämför arrangemanget av färger på målarbok genererade av olika parametrar, kan man få fullständig information om det finansiella porträttet av banker - förlorare, välmående banker, etc.
Med allt detta är den beskrivna tekniken en universell analysmetod. Med dess hjälp kan du analysera olika affärsstrategier, analysera resultaten av marknadsundersökningar, kontrollera kundernas kreditvärdighet etc.
Genom att ha en karta framför oss och veta information om några av de föremål som studeras, kan vi ganska tillförlitligt bedöma de föremål som vi är lite bekanta med. Behöver du veta hur din nya partner är? Låt oss visa det på kartan och titta på grannarna. Som ett resultat är det möjligt att extrahera information från databasen baserat på luddiga egenskaper.
RENGÖRING OCH KONVERTERING AV DATABAS
Preliminärt, innan du går in i nätverket, kan datatransformation med hjälp av standardstatistiska tekniker avsevärt förbättra både träningsparametrarna (varaktighet, komplexitet) och systemdriften. Till exempel, om ingångsserien har en distinkt exponentiell form, kommer en enklare serie att erhållas efter att ha tagit dess logaritm, och om den innehåller komplexa beroenden av hög ordning blir det nu mycket lättare att upptäcka dem. Mycket ofta utsätts onormalt fördelade data preliminärt för en icke-linjär transformation: den ursprungliga värdeserien för variabeln transformeras av någon funktion, och serien som erhålls vid utgången tas som en ny ingångsvariabel. Typiska konverteringar är exponentiering, rotextraktion, reciprok, exponentiell eller logaritm.
För att förbättra informationsstrukturen i datan kan vissa kombinationer av variabler - verk, kvoter etc. vara användbara. Till exempel, när du försöker förutsäga förändringar i aktiekurser baserat på positionsdata på optionsmarknaden, är förhållandet mellan antalet säljoptioner och antalet köpoptioner större än mer informativt än båda dessa indikatorer separat. Med hjälp av sådana mellankombinationer är det dessutom ofta möjligt att få fram fler enkel modell, vilket är särskilt viktigt när antalet frihetsgrader är begränsat.
Slutligen har några av transformationsfunktionerna implementerade i utgångsnoden skalningsproblem. Sigmoiden är definierad på ett segment, så utdatavariabeln måste skalas så att den tar värden i detta intervall. Flera metoder för skalning är kända: skift med en konstant, proportionell förändring av värden med ett nytt minimum och maximum, centrering genom att subtrahera medelvärdet, bringa standardavvikelsen till ett, standardisering (de två sista åtgärderna tillsammans). Det är vettigt att se till att värdena för alla in- och utdatakvantiteter i nätverket alltid ligger, till exempel i intervallet (eller [-1,1]), då kommer det att vara möjligt att använda alla transformationsfunktioner utan risk.
MODELLBYGGNAD
Värdena för målserien (detta är serien som måste hittas, till exempel vinsten på aktier för den kommande dagen) beror på N faktorer, som kan inkludera kombinationer av variabler, tidigare värden för målet variabla, kodade kvalitativa indikatorer.
Utvärdering av modellkvalitet baseras vanligtvis på ett godhetstest, såsom medelkvadratfel (MSE) eller kvadratrot (RMSE). Dessa kriterier visar hur nära de förutsagda värdena var träningen, bekräftelsen eller testuppsättningen.
I linjär tidsserieanalys kan en opartisk uppskattning av generaliserbarhet erhållas genom att undersöka prestandan på träningsuppsättningen (MSE), antalet fria parametrar (W) och storleken på träningsuppsättningen (N). Bedömningar av denna typ kallas informationskriterier(1C) och inkludera en komponent som uppfyller kriteriet för god passform och en straffkomponent som tar hänsyn till modellens komplexitet. Följande informationskriterier har föreslagits: Normaliserad (NAIC), Normaliserad Bayesian (NBIC) och Forecast Final Error (FPE):
undertext ">
PROGRAMVARA
Hittills många mjukvarupaket implementera neurala nätverk. Här är några av de mest kända: neurala nätverkssimulatorer på mjukvarumarknaden: Nestor, Cascade Correlation, Neudisk, Mimenice, Nu Web, Brain, Dana, Neuralworks Professional II Plus, Brain Maker, HNet, Explorer, Explorenet 3000, Neuro Solutions, Prapagator, Matlab Toolbox. Det är också värt att nämna simulatorer som distribueras fritt via universitetsservrar (till exempel SNNS (Stuttgart) eller Nevada QuickPropagation). En viktig egenskap hos paketet är dess kompatibilitet med andra program som är involverade i databehandling. Dessutom är ett användarvänligt gränssnitt och prestanda viktigt, vilket kan gå upp till många megaflops (miljoner flyttalsoperationer per sekund). Acceleratorkort minskar träningstiden när du arbetar på konventionella personliga datorer... Men för att få tillförlitliga resultat med hjälp av neurala nätverk krävs som regel en kraftfull dator.
Väletablerade paradigm inom finansvetenskap, såsom random walk-modellen och hypotesen om effektiva marknader, antar att finansmarknaderna svarar på information på ett rationellt och flytande sätt. I det här fallet kan du knappast tänka dig något bättre än linjära relationer och stationärt beteende med en reversibel trend. Tyvärr, i det verkliga beteendet på finansmarknaderna, ser vi inte bara reversibiliteten av trender, utan ständigt framväxande räntefelmatchningar, volatilitet som uppenbarligen inte motsvarar den inkommande informationen och periodiskt förekommande prisnivå- och volatilitetshopp. Flera nya modeller har utvecklats för att beskriva beteendet på finansmarknaderna och har haft viss framgång.
FINANSIELL ANALYS PÅ VÄRDEPAPPERSMARKNADEN
Finansiell analys på värdepappersmarknaden med hjälp av neurala nätverksteknologier i detta arbete utförs i relation till handel med olja och oljeprodukter.
Makroekonomisk tillväxt och landets välfärd beror till stor del på basindustriernas utvecklingsnivå, bland vilka oljeutvinnings- och oljeraffineringsindustrin spelar en oerhört viktig roll. Situationen i oljeindustrin avgör till stor del tillståndet för hela den ryska ekonomin. I samband med det rådande prisläget på världsmarknaden för oljeprodukter är exporten för Ryssland den mest lönsamma sidan i oljeindustrins verksamhet. Oljeexport är en av de viktigaste och snabbaste källorna till valutainkomster. En av oljeindustrins bästa representanter är oljebolaget LUKOIL. NK LUKOIL är det ledande vertikalt integrerade oljebolaget i Ryssland, som är specialiserat på oljeproduktion och raffinering, produktion och marknadsföring av petroleumprodukter. Företaget verkar inte bara i Ryssland utan också utomlands och deltar aktivt i lovande projekt.
Företagets finansiella och produktionsverksamhet beskrivs i tabell 13.1.
Tabell. 13.1
Finansiella och operativa nyckelindikatorer för 1998
namnlöst dokument
| Oljeproduktion (inklusive gaskondensat) | 64192 1284 |
|
| Kommersiell gasproduktion | miljoner kubikmeter m / år miljoner kubikmeter fot / dag | 3748 369 |
| Oljeraffinering (egna raffinaderier, inklusive utländska) | tusen ton / år tusen bar / dag | 17947 359 |
| Oljeexport | tusen ton/år | 24711 |
| Export av petroleumprodukter | tusen ton/år | 3426 |
| Nettointäkter från försäljning | miljoner rubel miljoner USD * | 81660 8393 |
| Vinst från försäljning | miljoner rubel miljoner USD * | 5032 517 |
| Resultat före skatt (enligt rapporten) | miljoner rubel miljoner USD * | 2032 209 |
| Resultat före skatt (exklusive valutakursdifferens) | miljoner rubel miljoner USD * | 5134 528 |
| Behållna intäkter (rapporterade) | miljoner rubel miljoner USD * | 118 12 |
| Balanserade vinstmedel (exklusive valutakursdifferenser) | miljoner rubel miljoner USD * | 3220 331 |
| Tillgångar (i slutet av året) | miljoner rubel miljoner USD * | 136482 6638 |
På grund av den fortsatta nedgången i världsmarknadspriserna på oljeprodukter 1998 uppgick deras export till 3,4 miljoner ton mot 6,3 miljoner 1997. För att bevara Bolagets vunna positioner på världsmarknaden för petroleumprodukter planeras exportvolymerna ökas under 1999 till 5-6 miljoner, med förbehåll för en förbättring av marknadsvillkoren. Den prioriterade uppgiften är att skapa en stimulerande miljö för exporttillväxt och få ut maximal vinst.
En viktig komponent i processen att sälja olja och oljeprodukter för export, inklusive alla former av kontrakt, förfarandet för prissättning, parternas ansvar, etc., är utbytet. Det ackumulerar alla processer som inträffar vid köp och försäljning av en viss produkt, och hjälper till att försäkra sig mot tillhörande risker.
Börserna där olje- och oljeproduktterminskontrakt handlas: New York Mercantile Exchange (NYMEX) och London International Petroleum Exchange (IPE). En börs är en grossistmarknad som är juridiskt uppbyggd som en organisation av handlare. Utvecklingen av mekanismer för handel med terminskontrakt och införandet av det senare på alla tillgångar som tidigare handlades av råvaru-, termins- och valutabörser, ledde till att skillnaderna mellan dessa typer av börser suddas ut och till uppkomsten av båda terminsbörserna, på vilka endast terminskontrakt handlas, eller universella börser, där de handlar både terminskontrakt och traditionella börshandlade tillgångar som aktier, valutor och till och med enskilda råvaror.
Funktionerna för utbytet är följande:
anordnande av börsmöten för att hålla öppna offentliga affärer;
utveckling av utbyteskontrakt;
börsskiljedom, eller lösning av tvister som uppstår från avslutade valutatransaktioner under börshandel;
börsens värdefunktion. Denna funktion har två aspekter. Den första är att börsens uppgift är att identifiera "sanna" marknadspriser, men samtidigt att reglera dem för att förhindra illegala manipulationer med priser på börsen. Den andra är börsens prisprognosfunktion;
säkringsfunktion, eller börsförsäkring av börshandlande deltagare mot prisfluktuationer som är ogynnsamma för dem. Säkringsfunktionen är baserad på användningen av en mekanism för handel med terminskontrakt. Kärnan i denna funktion är att näringsidkaren - hedgaren (det vill säga den som är försäkrad) - måste bli både säljare av varan och dess köpare. I detta fall neutraliseras varje förändring av priset på hans varor, eftersom säljarens vinst samtidigt är köparens förlust och vice versa. Denna situation uppnås genom att hedgern, till exempel tar en köpares ställning på den vanliga marknaden, måste inta den motsatta ställningen, i detta fall säljaren, på marknaden för börshandlade terminskontrakt. Vanligtvis säkrar tillverkare av en produkt sig mot en minskning av priserna för sina produkter och köpare - mot en ökning av priserna för inköpta produkter:
spekulativ utbytesverksamhet;
funktion att garantera genomförandet av transaktioner. Uppnås med hjälp av börsbaserade clearing- och avvecklingssystem;
informationsfunktionen för utbytet.
De huvudsakliga informationskällorna om tillståndet och utvecklingsmöjligheterna för världsmarknaden för olje- och oljeprodukter är publikationer från offertbyråerna Piatt's (en strukturell division av det största amerikanska förlagsföretaget McGraw-Hill) och Argus Petroleum (ett oberoende företag, Storbritannien ).
Citat ger en uppfattning om prisintervallet för en viss oljekvalitet för en viss dag. Följaktligen består de av minimipriset (det lägsta transaktionspriset eller det lägsta vägda genomsnittspriset för erbjudandet om att köpa en given oljekvalitet) och maximipriset (det högsta transaktionspriset eller det högsta vägda genomsnittspriset för erbjudandet att sälja) .
Riktigheten av offerter beror på mängden information som samlas in. De första uppgifterna om offerter ges i realtid (du kan få dem om du har tillgång till lämplig utrustning) kl. 21.00-22.00 Moskva-tid. Dessa uppgifter kan korrigeras om ny information om affärer kommer in i slutet av dagen, vilket förtydligar preliminära offerter. Den slutliga versionen av citaten finns i de officiella tryckta publikationerna från de angivna byråerna.
Offerter anges både för transaktioner med omedelbar leverans - spotpriser (leverans inom två veckor, och för vissa råoljekvaliteter - inom tre veckor), och för transaktioner med uppskjuten leverans (för nyckelkvaliteter av olja) - priser "framåt" (leverans om en månad, två månader och tre månader).
Spot- och forwardinformation är ett nyckelelement i oljehandeln på den fria marknaden. Spotkurser används för att bedöma riktigheten av det valda priset på en tidigare avslutad terminsaffär; för att utfärda fakturor för leveranser, vars beräkningar utförs på grundval av formler baserade på punktpriser vid tidpunkten för leverans av varorna; och även som utgångspunkt från vilken motparter börjar diskutera prisvillkoren för transaktioner nästa noteringsdag.
Terminskurser, som återspeglar fasta priser för försenade leveranstransaktioner, representerar i huvudsak en prognostiserad bedömning av marknadsaktörerna av situationen en månad, två och tre månader i förväg. I kombination med avistakurser visar terminskurser den mest sannolika trenden i ögonblicket av prisförändringar för denna oljeklass i framtiden om en, två och tre månader.
Offerter ges för denna klass av standardkvalitet. Om kvaliteten på ett visst parti olja skiljer sig från standarden, fastställs priset på partiet vid transaktionens slut på basis av offerter med hänsyn till en rabatt eller premie för kvalitet.
Storleken på en rabatt eller premie för kvalitet beror på i vilken utsträckning nettopriset för en viss sändning av varor skiljer sig från nettopriset för en given kvalitet av standardkvalitet.
För att sammanfatta allt som har sagts, noterar vi att för att säkerställa effektiv oljeexport måste leverantören ha data om spot- och terminskurser, priser för oljeprodukter och terminspositioner, information om nettopriser, frakt- och försäkringspriser, dynamik i spreadar och lager, olja. Minimikraven på information reduceras till kunskapen om "spot" och "forward" offerter för exporterad olja och konkurrenskraftiga oljekvaliteter, dynamiken i spridningar, frakt- och försäkringspriser. De viktigaste typerna av terminskontrakt som ingås på börsen inkluderar:
Terminskontrakt- ett kontrakt för köp och försäljning av varor i framtiden till priset vid tidpunkten för transaktionen.
Option - ett kontrakt som ger rätten, men inte skyldigheten, att köpa eller sälja ett terminskontrakt för olja eller petroleumprodukter i framtiden till ett önskat pris. Optioner handlas på samma börser där terminskontrakt handlas.
Forward transaktion- en affär vars genomförandeperiod inte sammanfaller med tidpunkten för dess slutande på börsen och som anges i avtalet.
En avistatransaktion kännetecknas av det faktum att löptiden för dess ingående sammanfaller med datumet för genomförandet, och i en sådan transaktion måste valutan levereras omedelbart (som regel senast två arbetsdagar efter transaktionens slutförande ).
Vid avtalsslutet spelar en särskild roll av träffsäkerheten i prognosen för situationen på marknaden för denna typ av produkter, samt en prognos för priset på den. Därför anser vi att det är viktigt att överväga vilken roll prognosestimat har för att uppnå effekten av handel med olja och oljeprodukter.
När du gör de listade transaktionerna finns det en viktig punkt - prognosernas noggrannhet. Ur teoretisk synvinkel verkar det förstås som att vi inte bryr oss om var priserna kommer att ligga i framtiden. Efter att ha öppnat en position stängde vi oljepriset för oss själva, för oss kan det inte längre vara varken högre eller lägre. Därför ger en korrekt prognos oss en möjlighet till nödvändiga åtgärder när priset ändras. En felaktig prognos innebär förluster. Det finns många sätt att prognostisera på marknaden, men bara ett fåtal av dem förtjänar särskild uppmärksamhet. Under många år har prognoser på finansiella marknader baserats på teori om rationella förväntningar, tidsserieanalys och teknisk analys.
Enligt teorin om rationella förväntningar ökar eller minskar priserna på grund av att investerare rationellt och omedelbart reagerar på ny information: eventuella skillnader mellan investerare i förhållande till till exempel investeringsmål eller information som är tillgänglig för dem ignoreras som statistiskt obetydliga. Detta tillvägagångssätt bygger på antagandet om fullständig informationsöppenhet på marknaden, dvs. på att ingen av dess deltagare har information som de andra deltagarna inte skulle ha. Samtidigt kan det inte finnas några konkurrensfördelar, eftersom att ha information som inte är tillgänglig för andra är det omöjligt att öka chanserna att göra vinst.
Syftet med tidsserieanalys är att med statistiska metoder identifiera ett visst antal faktorer som påverkar prisförändringar. Detta tillvägagångssätt låter dig identifiera trender i utvecklingen av marknaden, men om det finns upprepning eller enhetliga cykler i dataserien, kan tillämpningen vara allvarligt svår.
Teknisk analysär en uppsättning metoder för analys och beslutsfattande endast baserade på studiet av aktiemarknadens interna parametrar: priser, transaktionsvolymer och värdet av öppet intresse (antalet öppna köp- och säljkontrakt). Alla olika prognosmetoder för teknisk analys kan delas in i två stora grupper: grafiska metoder och analytiska metoder.
Grafisk teknisk analys är analys av olika marknader grafiska modeller, bildad av vissa mönster av prisrörelser på diagram, för att anta sannolikheten för fortsättning eller förändring av den befintliga trenden. Låt oss överväga huvudtyperna av diagram:
Linjär. På ett linjediagram markeras endast slutkursen för varje efterföljande period. Rekommenderas för korta perioder (upp till flera minuter).

Segmentdiagram (staplar) - stapeldiagrammet visar maxpriset (den översta punkten på stapeln), minimipriset (den nedre punkten av stapeln), det öppna priset (streck till vänster om den vertikala stapeln) och stängningen pris (strecket till höger om den vertikala stapeln). Rekommenderas för perioder på 5 minuter eller mer.

Japanska ljusstakar (byggda i analogi med barer).

Tic-tac-toe - det finns ingen tidsaxel, och en ny priskolumn byggs efter uppkomsten av en annan dynamikriktning. Ett kryss dras om priserna har minskat med ett visst antal poäng (omkastningskriteriet), om priserna har ökat med ett visst antal poäng dras en nolla.

Aritmetiska och logaritmiska skalor. För vissa typer av analyser, särskilt när det gäller att analysera långsiktiga trender, är det lämpligt att använda en logaritmisk skala. I en aritmetisk skala är avstånden mellan divisionerna oförändrade. På en logaritmisk skala motsvarar samma avstånd samma procentuella förändring.
Volymdiagram.

Postulaten för denna typ av teknisk analys är följande grundläggande begrepp för teknisk analys: trendlinjer, marknadsmotstånd och stödnivåer, korrigeringsnivåer för den aktuella trenden. Till exempel:

Motståndslinjer:
uppstår när köpare antingen inte längre kan eller inte vill köpa en viss produkt till högre priser. Försäljningstrycket överstiger köparens tryck, som ett resultat stoppar tillväxten och ger vika för ett fall;
koppla ihop viktiga toppar (toppar) på marknaden.

Stödlinjer:
koppla ihop viktiga dalar (botten) på marknaden;
uppstår när säljare antingen inte längre kan eller inte vill sälja en viss produkt till lägre priser. Vid en given prisnivå är köplusten stark nog att stå emot säljtrycket. Nedgången avbryts och priserna börjar gå upp igen.

När man går ner förvandlas stödlinjen till motstånd. När den stiger förvandlas motståndslinjen till stöd.

Om priserna fluktuerar mellan två parallella raka linjer (kanallinjer), kan vi prata om närvaron av en uppåtgående (nedåt eller horisontell) kanal.

Det finns två typer av grafiska modeller:
1. Mönster av vändningstendenser - mönster som bildas på diagrammen, som, om vissa villkor är uppfyllda, kan förutse en förändring av den befintliga trenden på marknaden. Dessa inkluderar huvud och axlar, dubbel topp, dubbel botten, trippel topp, trippel botten.
Låt oss ta en titt på några av dem.
"Huvud - Axlar" - bekräftar trendvändningen.

Figur 13.22. 1-första topp; 2-sekunders topp; 3-linjers hals
HeadShoulders - huvud - axlar.

Figur 13.23. 1-topp på vänster axel; 2-topp på huvudet, 3-topp på höger axel; 4-linjers hals.
2. Mönster för fortsättningen av trenden - mönster som bildas på diagrammen, som, om vissa villkor är uppfyllda, tillåter oss att hävda att det finns en möjlighet att fortsätta den nuvarande trenden. Trenden kan ha utvecklats för snabbt och tillfälligt hamnat i ett överköpt eller översålt tillstånd. Sedan, efter en mellankorrigering, kommer den att fortsätta sin utveckling i riktning mot den tidigare trenden. I denna grupp finns det modeller som "trianglar", "diamanter", "flaggor", "vimplar" och andra. Till exempel:


Som regel avslutar dessa figurer sin bildning på ett avstånd från det övre P (skaftet) lika med:
def-e ">
Triangel

Du bör vara rädd för trianglar på marknaden. P är prisbasen. T är tidsbasen. Utbrytningen av figuren sker på ett avstånd: ">
insamling och lagring av data - möjliga deltagare i prognosen (antingen som ett kriterium, eller som ett förutsagt värde, eller båda);
definition för trenden eller uppsättningen av kriterier som övervägs (dettare kan data som är direkt lagrade i databasen inte alltid användas, det är ofta nödvändigt att göra vissa datatransformationer, till exempel är det rationellt att använda relativa värdeförändringar som kriterier);
identifiering av förhållandet mellan det förutsagda värdet och en uppsättning kriterier i form av en viss funktion;
beräkning av värdet av intresse i enlighet med en viss funktion, värdena för kriterierna för det förutsagda ögonblicket och typen av prognos - kortsiktig eller lång sikt).
I den praktiska delen av arbetet, baserat på historiska data om en trend för en viss tidsperiod (månad, år, flera år), presenteras också i en viss tidsskala (minut, 5 minuter, halvtimme, dagligen, etc.) . citat), måste vi få en prognostiserad utveckling av offerter för flera tidsintervall framåt. Information om tillgångskurser presenteras av alla eller delar av standardparametrarna som beskriver kurser för en diskret tid: öppen, stäng, maximum, minimum, handelsvolym vid stängning, öppen ränta.
Användningen av neurala nätverk för att få en snabb och högkvalitativ prognos kan ses i fig. 13.27 "Teknologiskt system för prognoser på aktiemarknaden med hjälp av neurala nätverk."
För en fullfjädrad prognos över trender på de tre mest utvecklade marknaderna i vårt land, som inkluderar många finansiella instrument, krävs en tillräcklig mängd initiala data för prognosen. Som du kan se av diagrammet har följande information mottagits för tillfället:
information och handelsdata från byrån "REUTERS", "DOW JONES TELERATE", "BLOOMBERG";
handelsdata från MICEX- och RTS-plattformarna;
andra data med hjälp av manuell inmatning.
All nödvändig data går till databasen (DB MS SQL Server). Därefter sker ett urval och förberedelse av data för deltagande i prognosen. I detta preliminära skede uppstår problemet med att välja de viktigaste kriterierna för att prognostisera värdet av ett visst finansiellt instrument eller grupp av finansiella instrument från mer än 200 typer av information och handelsdata. Det primära valet av kriterier utförs av analytikern och beror på den senares erfarenhet och intuition. För att hjälpa analytikern tillhandahålls tekniska analysverktyg, presenterade i form av diagram, som analyserar vilka du kan fånga dolda relationer. Prognostidsserien är markerad.
Därefter skickas den bearbetade datan till STATIS-TICA Neural Networks neurala nätverkspaket, där 5-dagarsperioder identifieras med hjälp av en tränad perceptron. Nätverket tilldelar var och en av perioderna en av fyra indikatorer som kännetecknar trendförändringar (som diagram i teknisk analys): stabil period, uppåt, nedåt och obestämd. Nätverket bygger en prognos baserat på den bearbetade datan, men för att uppnå en förfining av de erhållna resultaten komplicerar vi prognosprocessen. Ytterligare bearbetning sker i STATIST1CA-systemet. Uppgifterna behöver inte konverteras, eftersom de är av samma typ.
Under bearbetningen av tidsserierna i STATISTICA-paketet i modulen TIME Series / Forecasting med hjälp av exponentiell utjämningsprognoser framhävs en trend, som delas upp i lika (5-dagarsperioder) för efterföljande korttidsprognoser. Trendsättningen utförs med en av de fyra presenterade metoderna (linjär, exponentiell, horisontell, polynom). Vi valde den exponentiella metoden för vårt experiment. Vi bearbetade trenden och fick data om dess utjämning. Dessa data matas återigen till neurala nätverksbehandlingar med användning av en flerskiktsperceptron. Träning utförs med den exponentiella utjämningsmetoden, som ett resultat av vilket nätverket bekräftar riktigheten av den tidigare erhållna prognosen. Du kan se resultaten med hjälp av arkiveringsfunktionen.
De resulterande förutsagda värdena analyseras av näringsidkaren, som ett resultat av vilket det korrekta beslutet fattas att genomföra transaktioner med värdepapper.
Ett av tillvägagångssätten för att lösa problemet med att analysera och prognostisera aktiemarknaden är baserad på den cykliska karaktären hos utvecklingen av ekonomiska processer. Uttrycket av cyklikalitet är den böljande utvecklingen av ekonomiska perioder. Vid prognostisering av tidsserier i ekonomin är det omöjligt att korrekt bedöma situationen och göra en tillräckligt korrekt prognos utan att ta hänsyn till att konjunktursvängningar är överlagrade på trendlinjen. Mer än 1380 typer av cyklikalitet är kända inom modern ekonomisk vetenskap. Ekonomin verkar främst med följande fyra:
Kitchin-cykler är inventeringscykler. Kitchin (1926) fokuserade på studiet av korta våglängder från 2 till 4 år på grundval av analysen av finansiella konton och försäljningspriser i lagerrörelser.
Zhuglyars cykler. Denna cykel har också andra namn: konjunkturcykel, industricykel, etc. Cykler upptäcktes genom att studera arten av industriella fluktuationer i Frankrike, Storbritannien och USA baserat på fundamental analys av fluktuationer i räntor och priser. Det visade sig att dessa fluktuationer sammanföll med investeringscykeln, vilket i sin tur utlöste förändringar i BNP, inflation och sysselsättning.
Smedens cykler. J. Riggalmen, W. Newman på 1930-talet. och flera andra analytiker har byggt de första statistiska indexen för den aggregerade årliga volymen av bostadsbyggande och hittat i dem successiva långa intervall av snabb tillväxt och djupa lågkonjunkturer eller stagnation. Då dök begreppet "konstruktionscykler" upp för första gången.
Kondratyevs cykler. Stora cykler kan ses som en störning och återställande av ekonomisk jämvikt under en lång period. Deras främsta skäl ligger i mekanismen för ackumulation, ackumulation och spridning av kapital som är tillräckligt för att skapa de viktigaste produktionskrafterna. Verkan av denna huvudorsak förstärker emellertid verkan av sekundära faktorer. I enlighet med ovanstående antar utvecklingen av en stor cykel följande belysning. Början av uppgången sammanfaller med det ögonblick då ackumulationen och ackumulationen av kapital når en sådan spänning, vid vilken det blir möjligt att lönsamt investera kapital för produktivkrafternas syften och en radikal återupprustning av teknologin. Dessutom, enligt de huvudsakliga "sanningarna" om Kondratyev, under perioden med den uppåtgående vågen av den stora cykeln, kännetecknas medel- och kortvågorna av korta spridningar och intensiteten i uppgångarna och i perioderna med nedåtgående våg av den stora cykeln, den motsatta bilden observeras.
På aktiemarknaden manifesteras dessa fluktuationer i successiva upp- och nedgångar i affärsaktivitetsnivåer över en tidsperiod: topp i cykeln, nedgång, dalgång och återhämtningsfas.
I denna artikel utgår vi från antagandet att prisfluktuationer på värdepappersmarknaden är resultatet av en överlagring av olika vågor och serier av slumpmässiga, stokastiska faktorer som anges ovan. Ett försök görs att identifiera förekomsten av cykler och att bestämma i vilken fas processen befinner sig. Utifrån detta görs en prognos ytterligare utveckling process med hjälp av ARIMA-verktyg under lämpliga processparameterantaganden.
Systemövergångarna är en överlagring av vågor av olika längd. Som ni vet har vågor flera faser som ersätter varandra. Detta kan vara en återhämtning, lågkonjunktur eller stagnationsfas. Om dessa faser tilldelas symboliska värden A, B, C, kan de representeras som en sekvens av primitiver (liknande diagram i teknisk analys) och genom att känna igen dessa sekvenser (som också representerar perioder av uppgång, fall, stagnation, dvs a, b, c, bara i mindre skala), kan vi, baserat på reglerna för att känna igen grammatik med viss sannolikhet, formeln "src =" http://hi-edu.ru/e-books/xbook725/ files/28.gif "border = "0" align = "absmiddle" alt = "(! LANG:... Sedan kan vi också titta på sekvenser som AAABBCD…. Det visar sig att vi kände igen både själva vågen och dess fas.
Nu kan vi inte bara göra en mer exakt kortsiktig prognos, utan vi kan också spåra den allmänna dynamiken på aktiemarknaden i framtiden (efter att ha bestämt fasen för den långa vågen, kan vi bedöma arten av nästa, eftersom faserna fortsätter i en viss sekvens). I vårt experiment försökte vi träna perceptronen att känna igen vågornas faser (A, B, C, D).
För experimentet togs data från resultaten av handeln på RTS i aktier i LUKOIL (LKON) för perioden 1 juni 1998. till den 31 december 1999. Följande variabler ingick i den ursprungliga databasen: vägt genomsnittligt inköpspris, vägt genomsnittligt försäljningspris, högsta dagliga pris, minimipris per dag, antal transaktioner. Databasen med värdena för de listade variablerna importerades till Excel från Internet och överfördes sedan till SNW-paketet. Denna procedur diskuteras mer i detalj på ris. 13.28 - vikterna som seriens individuella observationer tar.
Bredden på utjämningsintervallet togs lika med 4 observationer. Sedan lades de numeriska trenduttrycken (Figur 13.30) till den nya variabeln utjämning.
Således har vi bildat en databas med variabler som kommer att matas till ingången av det neurala nätverket. Dessutom sedan SNW är helt kompatibelt med SNN, det fanns inget behov av att specifikt importera data till SNN. Vid ingången var det meningen att den skulle ta emot värden av typen a, b, c, d, men för detta var perceptronen tvungen att känna igen den fas vi befinner oss i och baserat på den göra en mer exakt kortsiktig prognos. Med andra ord måste han överväga sekvenserna av primitiver och identifiera dem med faserna i cykeln. Dessutom matar perceptronen inte ut faserna i cykeln av typ A, B, C, D.
För att implementera den inställda uppgiften att träna perceptronen tilldelas ett mobilt fönster med en bredd på 5 dagar. Ett tidsfönster består av en sekvens av primitiver a, b, c eller d. En mer exakt prognos kan således erhållas genom en bitvis approximation av den numeriska trenden vid det vägda genomsnittliga köpeskillingen.
För att träna perceptronen att känna igen femdagarssekvenser och identifiera dem som A, B, C eller D, var vi tvungna att själva definiera deras fas för ett antal alternativ och lägga till våra resultat till en ny variabel i den ursprungliga databasen (tillstånd) . Således innehåller den slutligen genererade databasen värdena för följande variabler: det vägda genomsnittliga inköpspriset, det vägda genomsnittliga försäljningspriset, det högsta dagliga priset, det lägsta dagspriset, antalet transaktioner, den markerade trenden i förhållande till det viktade genomsnittligt köpeskilling, och slutligen en variabel som bestämmer tillståndet i den ekonomiska processen. Alla variabler utom den sista matades in i ingången. Det var tänkt att det bara skulle erhållas vid utgången, så att perceptronen inte reagerade på värdet av denna variabel under träning, utan justerade vikterna så att endast fyra värden kunde erhållas vid utgången: A, B, C , D, och sedan, enligt den erkända staten, samt tog hänsyn till att efter uppgångsfasen följt av en fas av konstanthet, och sedan lågkonjunktur igen, och på denna grund kunde göra en kortsiktig prognos. Därmed har all data samlats in för prognosen. Nu finns det bara en fråga: vilka parametrar man ska välja för nätverket och vilken metod man ska träna. I detta avseende utfördes ett antal experiment och som ett resultat drogs följande slutsatser.
Ursprungligen var det tänkt att träna en flerskiktsperceptron med hjälp av bakåtförökning av fel. Ingången var 7 variabler (de är listade ovan), utgången är bara en - STATE. Förutom ingångs- och utgångsskikten byggdes ett mellanskikt, bestående av 6, och sedan av 8 neuroner. Inlärningsfelet var ungefär 0,2-0,4, men perceptronen reagerade dåligt på transienta tillstånd. Därför bestämde vi oss för att först öka antalet neuroner i mellanlagret till 14, och sedan ändrade vi metoden för att träna perceptronen ("konjugerade gradienter"). Felet började fluktuera inom intervallet 0,12-0,14, och hela uppsättningen av värden av variablerna betraktades som träning.
Som ett resultat av experimenten visade sig det neurala nätverket med följande parametrar vara optimalt: 7 variabler matas till ingången: Smoothly, Average, Open_Buy, VoLTrad. Val_Q, Min_PR, Max_PR, utgång - STATE. Träningen genomfördes med ett steg på 6, med metoden med konjugerade gradienter, totalt - 3 lager (på de första 7 neuronerna, på det andra - 14, på det tredje - 3) (Fig. 13.29), som en Resultatet var att perceptronen tydligt reagerade på trendens tillstånd (stigande - 1 neuron i utgångsskiktet, fallande ndash; 2 neuron i utgångsskiktet och horisontell - 3 neuron) (Fig. 13.31).
Som ett resultat av den utförda forskningen gjordes ett urval av data - möjliga objekt i prognosen, de förutspådda värdena och uppsättningarna av kriterier bestämdes, och även sambanden mellan dem identifierades.
Under experimentet fann man att trenddetektering ökar inlärningshastigheten för en flerskiktsperceptron, och med en viss nätverksreglering känner den igen uppåtgående, nedåtgående och horisontella trender.
De erhållna positiva resultaten gör det möjligt att gå vidare till en djupare studie av cykliska beroenden på marknaderna och att använda andra metoder för neurala teknologier (Kohonen-kartor) i finansiella transaktioner.
Skicka ditt goda arbete i kunskapsbasen är enkelt. Använd formuläret nedan
Studenter, doktorander, unga forskare som använder kunskapsbasen i sina studier och arbete kommer att vara er mycket tacksamma.
- Introduktion
- Slutsats
- Introduktion
- Skapandet av metoder för parallell bearbetning av information hade en gynnsam effekt på utvecklingen av neurala nätverksteknologier.
- Det är nödvändigt att uttrycka tacksamhet till den anmärkningsvärda kirurgen, filosofen och cybernetiken N.M. Amosov, som tillsammans med sina elever systematiserade tillvägagångssättet för att skapa artificiell intelligens (AI). Detta tillvägagångssätt är som följer.
- AI-strategier är baserade på konceptet med ett paradigm - en syn (konceptuell representation) på kärnan i ett problem eller en uppgift och principen för dess lösning. Betrakta två paradigm av artificiell intelligens.
- 1. Expertparadigmet antar följande objekt, såväl som utvecklings- och funktionsstadierna för AI-systemet:
- * kunskapsformatering - en experts omvandling av problematisk kunskap till den form som föreskrivs av den valda kunskapsrepresentationsmodellen;
- * bildande av en kunskapsbas<БЗ) - вложение формализованных знаний в программную систему;
- * deduktion - att lösa problemet med logisk slutledning baserat på kunskapsbas.
- Detta paradigm ligger till grund för användningen av expertsystem, logiska slutledningssystem, inklusive i det logiska programmeringsspråket PROLOGUE. Man tror att system baserade på detta paradigm är mer studerade.
- 2. Elevens paradigm, som inkluderar följande bestämmelser och sekvens av åtgärder:
- * bearbetning av observationer, studera upplevelsen av privata exempel - bildandet av en databas<БД>AI-system;
- * induktivt lärande - omvandlingen av en databas till en kunskapsbas baserad på generaliseringen av kunskap som samlats i databasen. och motivering av förfarandet för att utvinna kunskap från kunskapsbasen. Detta innebär att man utifrån data drar en slutsats om det generella beroendet mellan objekt som vi observerar. Huvudfokus här ligger på studiet av approximerande, probabilistiska och logiska mekanismer för att erhålla allmänna slutsatser från särskilda påståenden. Sedan kan vi till exempel underbygga giltigheten av den generaliserade interpolationsproceduren (extrapolering), eller den associativa sökproceduren, med hjälp av vilken vi kommer att tillfredsställa frågor till kunskapsbasen;
- * avdrag - enligt ett motiverat eller antaget förfarande väljer vi information från kunskapsbasen på begäran (till exempel den optimala styrstrategin för en vektor som kännetecknar den aktuella situationen).
- Forskningen inom ramen för detta paradigm och dess utveckling är fortfarande svag, även om de ligger till grund för konstruktionen av självlärande kontrollsystem (nedan kommer ett underbart exempel på ett självlärande kontrollsystem - reglerna för skjutning i artilleri).
- Hur skiljer sig en kunskapsbas, en vanlig och oumbärlig del av ett AI-system, från en databas? Möjlighet till logisk slutledning!
- Låt oss nu övergå till "naturlig" intelligens. Naturen har inte skapat något bättre än den mänskliga hjärnan. Det betyder att hjärnan är både bärare av kunskapsbasen och medel för logisk slutledning utifrån den, oavsett vilket paradigm vi har organiserat vårt tänkande, det vill säga på vilket sätt vi fyller kunskapsbasen. - lärande!
- JA. Pospelov, i ett anmärkningsvärt, unikt verk, belyser de högsta sfärerna av artificiell intelligens - tänkandets logik. Syftet med denna bok är att åtminstone delvis dissekera det neurala nätverket som ett sätt att tänka, och därigenom uppmärksamma den nedre, initiala länken i hela kedjan av artificiell intelligensmetoder.
- Genom att avvisa mystik, inser vi att hjärnan är ett neuralt nätverk, ett neuralt nätverk - neuroner sammankopplade, med många ingångar och en enda utgång vardera. Neuronen implementerar en ganska enkel överföringsfunktion som gör att du kan omvandla excitationen vid ingångarna, med hänsyn till ingångarnas vikter, till värdet av excitationen vid utgången av neuronen. Det funktionellt kompletta fragmentet av hjärnan har ett ingångsskikt av neuroner - receptorer, exciterade från utsidan, och ett utgångsskikt, vars neuroner exciteras beroende på konfigurationen och storleken på excitationen av neuroner i ingångsskiktet. Det är tänkt att vara ett neuralt nätverk. imiterar hjärnans arbete, bearbetar inte själva data, utan deras tillförlitlighet, eller, i konventionell mening, vikten, bedömningen av dessa data. För de flesta kontinuerliga eller diskreta data reduceras deras tilldelning till att indikera sannolikheten för de intervall som deras värden tillhör. För en stor klass av diskreta data - delar av uppsättningar - är det tillrådligt att stelt fixera neuronerna i inmatningsskiktet.
1. Erfarenhet av att använda neurala nätverk i ekonomiska problem
Med hjälp av neurala nätverk löser vi problemet med att utveckla algoritmer för att hitta en analytisk beskrivning av regelbundenhet i hur ekonomiska objekt (företag, industri, region) fungerar. Dessa algoritmer används för att prognostisera några av objektens "output"-indikatorer. Problemet med neurala nätverksimplementering av algoritmer håller på att lösas. Användningen av metoder för mönsterigenkänning eller motsvarande neurala nätverksmetoder gör det möjligt att lösa vissa akuta problem med ekonomisk och statistisk modellering, vilket ökar matematiska modellers adekvathet och för dem närmare den ekonomiska verkligheten. Användningen av mönsterigenkänning i kombination med regressionsanalys har lett till nya typer av modeller – klassificering och styckvis linjär. Att hitta dolda beroenden i databaser är grunden för modellerings- och kunskapsbearbetningsuppgifter, inklusive för ett objekt med mönster som är svåra att formalisera.
Valet av den mest föredragna modellen från en viss uppsättning av dem kan förstås antingen som ett rangordningsproblem eller som ett urvalsproblem baserat på en uppsättning regler. Praxis har visat att metoder baserade på användning av a priori vikter av faktorer och sökning efter en modell som motsvarar den maximala viktade summan av faktorer leder till partiska resultat. Vikter är det som måste bestämmas, och det är utmaningen. Dessutom är viktuppsättningarna lokala - var och en av dem är endast lämplig för en given specifik uppgift och ett givet objekt (grupp av objekt).
Låt oss överväga problemet med att välja den önskade modellen mer detaljerat. Antag att det finns en uppsättning objekt M, vars aktivitet syftar till att uppnå ett visst mål. Funktionen för varje objekt kännetecknas av värdena för n funktioner, det vill säga det finns en mappning φ: M -> Rn. Därför är vår utgångspunkt vektorn för det ekonomiska objektets tillstånd: x =. Prestandaindikatorer för ett ekonomiskt objekt: f0 (x), f1 (x),..., fm (x). Dessa indikatorer bör ligga inom vissa gränser, och vi strävar efter att göra några av dem till antingen minimum eller maximum.
En sådan generell formulering kan vara motsägelsefull, och det är nödvändigt att använda en apparat för att lösa motsägelser och föra problemformuleringen till rätt form som överensstämmer med den ekonomiska innebörden.
Vi ordnar objekt i termer av någon kriteriefunktion, men kriteriet är vanligtvis dåligt definierat, vagt och möjligen motsägelsefullt.
Låt oss överväga problemet med att modellera empiriska mönster baserat på ett begränsat antal experimentella och observerade data. Den matematiska modellen kan vara en regressionsekvation eller en diagnostisk regel eller en prediktionsregel. Med ett litet urval är igenkänningsmetoderna mer effektiva. I det här fallet beaktas påverkan av faktorhantering genom att variera värdena på faktorer när de ersätts med regelbundenhetsekvationen eller i beslutsregeln för diagnostik och prognoser. Dessutom tillämpar vi urvalet av viktiga funktioner och genereringen av användbara funktioner (sekundära parametrar). Denna matematiska apparat behövs för att förutsäga och diagnostisera ekonomiska objekts tillstånd.
Betrakta ett neuralt nätverk utifrån teorin om kommittéstrukturer, som en grupp av neuroner (individer. Ett neuralt nätverk som en mekanism för att optimera neuronernas arbete i kollektiva beslut är ett sätt att komma överens om individuella åsikter, där de kollektiv åsikt är det korrekta svaret på input, det vill säga det nödvändiga empiriska beroendet.
Därav följer att användningen av kommittéstrukturer i problemen med urval och diagnostik är motiverad. Tanken är att leta efter ett kollektiv av beslutsregler istället för en beslutsregel, detta kollektiv arbetar fram ett kollektivt beslut i kraft av ett förfarande som behandlar kollektivmedlemmarnas individuella beslut. Valmöjligheter och diagnostik leder som regel till inkonsekventa system av ojämlikheter, för vilka det i stället för lösningar är nödvändigt att leta efter generaliseringar av begreppet lösning. Denna generalisering är det kollektiva beslutet.
Så, till exempel, en kommitté för ett system av ojämlikheter är en sådan uppsättning av element att varje ojämlikhet tillfredsställs av de flesta av elementen i denna uppsättning. Kommittékonstruktioner är en viss klass av generaliseringar av begreppet lösning för problem som kan vara både kompatibla och inkonsekventa. Detta är en klass av diskreta approximationer för inkonsekventa problem; de kan också korreleras med otydliga lösningar. Metoden för kommittéer bestämmer för närvarande ett av områdena för analys och lösning av problem med effektivt val av alternativ, optimering, diagnostik och klassificering. Låt oss till exempel ge definitionen av en av huvudkommittékonstruktionerna, nämligen: för 0< p < 1: p - комитетом системы включений называется такой набор элементов, что каждому включению удовлетворяет более чем р - я часть этого набора.
Kommittékonstruktioner kan betraktas både som en viss klass av generaliseringar av konceptet med en lösning på fallet med inkompatibla system av ekvationer, ojämlikheter och inneslutningar, och som ett medel för parallellisering vid lösning av problem med val, diagnostik och prognoser. Som en generalisering av konceptet att lösa ett problem är kommittékonstruktioner uppsättningar av element som har vissa (men som regel inte alla) egenskaper hos en lösning; detta är ett slags luddiga lösningar.
Som ett medel för parallellisering uppträder kommittékonstruktioner direkt i flerskiktiga neurala nätverk. Vi har visat att för att träna ett neuralt nätverk för att korrekt lösa klassificeringsproblemet kan vi tillämpa metoden för att konstruera en kommitté av ett visst system av affina ojämlikheter.
Baserat på det föregående kan vi dra slutsatsen att kommittémetoden är förknippad med ett av de viktiga forskningsområdena och den numeriska lösningen av både diagnostiska problem och valet av alternativ, och uppgifterna att sätta upp neurala nätverk för att erhålla erforderligt svar på den ingående informationen om ett särskilt problem hos den person som tar emot lösningar.
Under driften av kommittémetoden avslöjades sådana viktiga egenskaper för tillämpade problem som heuristik, tolkningsbarhet, flexibilitet - möjligheten till ytterligare träning och omställning, möjligheten att använda den mest naturliga klassen av funktioner - styckvis-affin; att samma objekt inte är tilldelat olika klasser.
Den andra sidan av frågan om kommittéstrukturer är förknippad med begreppet koalitioner i utvecklingen av kollektiva beslut, medan situationerna skiljer sig kraftigt åt när det gäller kollektiva preferenser (det finns många fallgropar) och när det gäller kollektiva klassificeringsregler, i I det här fallet kan förfarandena noggrant motiveras och de har bredare möjligheter. ... Därför är det viktigt att kunna reducera besluts- och prognosproblem till klassificeringsproblem.
2. Tabellform - grunden för artificiell intelligens
I allmänhet är principerna för hjärnaktivitet kända och används aktivt. Vi använder osynliga bord i vårt minne, tvångsfullt och fritt fyllda vid ett skrivbord, vid ratten, med och utan ministerportfölj, och vänder våra huvuden på en bullrig gata, vid en bok, vid en bänk och vid ett staffli. Vi studerar, vi studerar hela våra liv: både en skolbarn som tillbringar sömnlösa nätter med att skriva en primer, och en professor med visdom. För med samma bord förknippar vi inte bara beslutsfattande, utan också röra, gå, spela boll.
Om vi motsätter oss matematiska beräkningar till associativt tänkande, vad är då deras vikt i mänskligt liv? Hur utvecklades en person när han inte alls visste hur man räknade? Genom att använda associativt tänkande, att kunna interpolera och extrapolera, samlade en person erfarenhet. (Låt oss förresten komma ihåg D. Mendeleevs tes: Vetenskapen börjar när de börjar räknas.) Du kan fråga läsaren: Hur många gånger har du räknat idag? Du körde bil, spelade tennis, rusade till bussen, planerade dina handlingar. Kan du föreställa dig hur mycket du skulle behöva beräkna (och var du kan få tag på algoritmen?) För att höja foten på trottoaren, kringgå trottoarkanten? Nej, vi räknar inte ut någonting varje minut, och det är kanske det viktigaste i vårt intellektuella liv, även inom vetenskap och näringsliv. Mekanismerna för förnimmelser, intuition, automatism, som vi, oförmögna att förklara, adresserar subkortikalt tänkande, är i själva verket normala mekanismer för associativt tänkande med hjälp av tabeller av kunskapsbasen.
Och viktigast av allt, vi gör det snabbt! Hur kan vi inte tänka, försöka förstå och reproducera utvecklingen av figurativt minne, en produkt av tillväxt i utvecklingsprocessen. Vi tror att detta är helt materiellt förkroppsligat och därför kan realiseras på konstgjord väg, med förbehåll för modellering och reproduktion.
Låt oss nu formulera en tillräcklig, dagens princip för att bygga ett neuralt nätverk som en del av AI:
1. Det bör erkännas att grunden för imitation av hjärnans neurostruktur är metoden för tabellinterpolation.
2. Tabeller fylls antingen enligt välkända beräkningsalgoritmer, eller experimentellt eller av experter.
3. Det neurala nätverket ger en hög hastighet av bearbetningstabeller på grund av möjligheten till en lavinliknande parallellisering.
4. Dessutom tillåter det neurala nätverket inträde i tabellen med felaktiga och ofullständiga data, vilket ger ett ungefärligt svar baserat på principen om maximal eller genomsnittlig likhet.
5. Uppgiften med hjärnans neurala nätverksimitation är att omvandla inte den initiala informationen i sig, utan uppskattningarna av denna information, genom att ersätta information med värdena för excitation av receptorer, skickligt fördelade mellan arter, typer, parametrar , intervall för deras förändring eller individuella värden.
6. Neuronerna i utgångsskiktet av varje understruktur genom sin excitation indikerar motsvarande lösningar. Samtidigt kan dessa exciteringssignaler som den ursprungliga förmedlade informationen användas i nästa länk i den logiska kedjan utan extern störning i driftläget.
3. Övervakning av banksystemet
Artikeln ger ett exempel på den briljanta tillämpningen av självorganiserande Kohonen-kartor (SOM - Self-Organizing Map) för studien av Rysslands banksystem 1999-2000.
Övervakningen är baserad på en ratingbedömning baserad på automatisk utförande av en procedur: den visas på datorskärmen enligt den flerdimensionella vektorn av bankparametrar. Uppmärksamhet dras till det faktum att neurala nätverksteknologier gör det möjligt att konstruera visuella funktioner av många variabler, som om man omvandlar ett flerdimensionellt utrymme till en-, två- eller tredimensionellt. För varje separat studie av olika faktorer är det nödvändigt att bygga sina egna SOM. Prognosen är möjlig endast baserat på analysen av tidsserien av SOM-uppskattningar. Nya SOM behövs också för att förlänga uttagskedjan, med anslutning av data utifrån till exempel av politisk karaktär.
Detta tillvägagångssätt är utan tvekan effektivt och effektivt. Men det verkar som om det, i jämförelse med hjärnans neurostrukturers potential, begränsar tankens omfattning och mod, tillåter inte att dra långa kedjor av premisseffekt, kombinera analys med prognos, omedelbart ta hänsyn till utvecklingssituationen och introducera nya faktorer och experterfarenhet beaktas. Man bör komma överens om att allt detta är föremål för hjärnan, och vi vänder oss igen till dess strukturer och föreslår ett projekt för övervakningssystemets programvara.
Det neurala nätverkets struktur och träningsmetoder. De logiska funktionerna som ligger bakom övervakningen är huvudsakligen baserade på kombinationen av logiska värden av variabler som återspeglar intervallen för förändringar i parametrar eller indikatorer för banker.
Följande indikatorer presenteras:
* eget kapital;
* Nettade tillgångar;
* likvida tillgångar;
* begära skulder;
* avlagringar av befolkningen;
* Kassalikviditeten;
* budgetresurser.
Du kan utöka styrkortet:
* Investeringsvolymen i en era av en blomstrande ekonomi;
* vinstvolym;
* Tidigare rangordning och betydelsen av migration;
* avdrag till fonden för stöd till vetenskap och utbildning;
* skatteavdrag;
* avgifter till pensionsfonden;
* avdrag till en välgörenhets- och kulturfond;
* deltagande i UNESCO-program m.m.
En sådan enkel form av den logiska funktionen när den passerar in i sfären av reella variabler indikerar tillräckligheten av ett enskiktigt neuralt nätverk som innehåller ett ingångsskikt av receptorer och ett utgångsskikt på vilket övervakningsresultaten bildas.
När du konstruerar inmatningsskiktet är det nödvändigt att ta hänsyn till inte bara de nuvarande indikatorerna, utan också dynamiken i betygsändringen under de senaste tidsperioderna. Utdatalagret bör inte bara återspegla betyget, utan också expertråd och andra beslut och slutsatser.
Den enklaste typen av träning är ändamålsenlig - att bygga en kunskapsbas som motsvarar konceptet att skapa ett neuralt nätverk för en uppgift: direkt införande av anslutningar av en operatör-forskare manuellt - från receptorer till neuroner i utgångsskiktet i enlighet med orsakssamband . Således skapas nätverket redan tränat.
Då kommer överföringsfunktionen också att vara den enklaste och baserad på summeringen av excitationsvärdena vid ingången av neuronen, multiplicerat med anslutningens vikt:
Tilldelningen av anslutningarnas vikt ha, i jämförelse med grovtilldelningen av alla vikter lika med en, är mer ändamålsenlig i samband med en operatörs eller en experts eventuella önskan att ta hänsyn till olika indikatorers inverkan i varierande grad.
Tröskeln h skär bort uppenbart oacceptabla slutsatser, vilket förenklar vidare bearbetning (till exempel att hitta medelvärdet). Reduktionskoefficienten till beror på följande överväganden.
Det maximala värdet för V kan nå n. För att värderingsvärdet ska vara inom ett visst acceptabelt område, till exempel in, måste excitationsvärdena transformeras genom att sätta k = Yn.
Ovanstående antaganden gör det möjligt att snabbt införa ändringar och förtydliganden av operatören - experten - användaren, utveckla nätverket genom att introducera nya faktorer och ta hänsyn till erfarenhet. För att göra detta behöver operatören bara välja receptorn, och sedan neuronen i utgångsskiktet, genom att klicka med musen, och anslutningen upprättas! Det återstår bara att ungefär tilldela vikten av den inmatade anslutningen från intervallet.
Ett mycket viktigt meddelande (HIA) bör göras här om hela materialet i boken och avsedd för en mycket uppmärksam läsare.
Tidigare, när vi övervägde utbildning, klassificerade vi tydligt de initiala referenssituationerna, och antog att förtroendet för varje komponent var lika med en. När vi sedan spårar och lägger ut dynamiska excitationsbanor sätter vi också bindningsvikterna till ett (eller något maximalt konstant värde). Men läraren kan omedelbart få en ytterligare frihetsgrad, med hänsyn till faktorerna i den utsträckning och med de vikter som han sätter! Låt oss anta att olika faktorer påverkar resultatet i olika grad, och vi kommer att kraftfullt lägga ett sådant inflytande på träningsstadiet.
Till exempel är det känt att på tröskeln till kriget köper befolkningen enorma mängder tvål, tändstickor och salt. Genom att observera denna faktor kan man därför förutsäga den nära förestående starten av kriget.
När du skapar ett neuralt nätverk för analys av historiska eller sociala händelser, bör en eller flera receptorer identifieras, vars excitation motsvarar olika nivåer av köp av tvål, salt och tändstickor samtidigt. Excitationen av dessa receptorer måste överföras, påverka (tillsammans med andra faktorer) graden av excitation av neuronen i utgångsskiktet, motsvarande uttalandet War is Coming!
Inte desto mindre är det intensiva köpet av tvål, tändstickor och salt en nödvändig men inte så tillräcklig förutsättning för krigsutbrottet. Det kan till exempel tyda på ett snabbt återupplivande av turismen i regionen Main Kaukasus. Ord innehåller egentligen inte innebörden av fuzzy logic, som tillåter att man inte tar hänsyn till oföränderligheten av en händelse, inte en boolesk variabel ja - nej, men något mellanliggande, obestämt, viktat tillstånd av typen "påverkar, men inte så direkt, att det är nödvändigt...". Därför sätts kopplingarna (alla eller vissa) som härrör från en given (data)receptor lika med något antaget värde, mindre än ett och korrigeras därefter, vilket återspeglar effekten av excitation av receptorn på utmatningen.
Sålunda räknas det samtidiga köpet av tvål, salt och tändstickor två gånger: inköpsnivån kommer att visas i graden av excitation av motsvarande receptorer, och arten av köpets inverkan på uttag.Krig kommer snart! - använda vikterna av synaptiska anslutningar.
Håller med om att när man bygger nätverk på en nivå, föreslår detta tillvägagångssätt sig själv och implementeras mycket enkelt.
Receptorskärmstruktur. Huvuddelen av det är ett rullningsfönster, där du kan se och ställa in receptorlagrets tillstånd, som utan tvekan inte får plats på en statisk skärm.
Rullningsfönstret visar indikatorerna och deras uppskattade värden i intervallet för motsvarande receptorer. Dessa är probabilistiska värden baserade på tillförlitlighet, intuition, expertbedömning. Uppskattningar förutsätter täckning av flera receptorer. Till exempel en uppskattning av att eget kapital är antingen 24 eller 34 eller 42 tusen. Det vill säga, men snarare lika 24, kan leda till en ungefärlig uppskattning av de inställda värdena för excitation av 0,6, 0,2 och 0,2 receptorer som motsvarar intervallen (20 - 25], (30 - 35], (40 - 45]. Skärmen visar statiskt inställda värden, såsom betyg som ett resultat av tidigare mätningar, selektiva tidigare hittade indikatorer, såväl som indikatorer på politiska, sociala och ekonomiska förhållanden. (Deras överflöd och utveckling kan fortfarande kräva rullning.)
Du bör också visa rullningskontrollerna och huvudåtgärdsmenyn:
* övergång till skärmen för utdatalagret;
* statistisk bearbetning av resultaten (förutsätter övergången till utgångsskärmen);
* införande av en ny anslutning;
* införande av en ny receptor;
* introduktion av en ny neuron i utgångsskiktet (förutsätter skärmbyte);
* införande av ny indikator osv.
Utgångsskiktets skärmstruktur. Skärmen Output Layer (Figur 8.3) visar ett system av koncentriska (kapslade) rektanglar eller andra platta former som representerar en fallande spridning av betyget. I mitten av skärmen markerar ljusa prickar de mest framgångsrika bankerna eller förmodade idealbilder. Varje element på skärmen är styvt associerat med en neuron i utgångsskiktet. Som ett resultat av övervakning kan en neuron som motsvarar standarden exciteras maximalt, men troligtvis kommer en skärmpunkt att visas som inte sammanfaller med någon standard, som är mellanliggande eller genomsnittlig.
Ris. - 8.3. Utdatalagerskärm
Utan tvekan bör en meny tillhandahållas för driften av en genomsnittlig betygsbedömning, demonstration av framgångskategorin, utfärdande av varningssignaler, slutsatser, rekommenderade utvecklingsstrategier, lagring av data för vidare utveckling, etc.
Neural nätverksträning. För att träna ett neuralt nätverk baserat på expertbedömningar är det nödvändigt att ställa in intervallen för tillåtna parametrar som gör att banken kan anses vara idealisk framgångsrik med maximalt betyg. Genom att fastställa flera punkter, vars koordinater (uppsättningar av parametervärden) uppfyller de acceptabla ratingvärdena för kända eller antagna (med hänsyn till möjliga alternativ) banker, kan flera idealiska representanter erhållas. Motsvarande neuroner, dvs. skärmelementen i utmatningsskiktet väljs slumpmässigt, utspridda över skärmområdet. Det är önskvärt att standarderna med högre betyg ligger närmare centrum.
Fortsätt sedan till liknande fyllning av den omslutande rektangeln, baserat på nästa betygskategori, etc. till utomstående banker.
För att utföra sådant arbete bildar experter preliminärt en tabell (tabell 1).
Neuronerna som visar banker på skärmen motsvarar storleken på deras excitation - betyg.
Övervakningsteknik. Det utbildade systemet, som kommer till användarens förfogande efter högkvalificerad expertis från ekonomer och politiker, är redo att användas inom ramen för CASE-teknologi CASE - Computer Aided Software Engineering.
Tabell 1 - Expertuppskattningar för träning av ett neuralt nätverk
I det här fallet utövar användaren sin rätt till ytterligare utbildning, förtydligande (till exempel vikter av anslutningar, för att förbättra eller försvaga inflytandet från vissa indikatorer baserat på hans egen erfarenhet), införandet av ytterligare indikatorer för experimentet på egen risk , etc.
Anta att användaren undersöker situationen kring Invest-There-and-Back Bank. Naturligtvis har han ingen tillfredsställande information om lämpligheten av sina egna investeringar och börjar därför en noggrann insamling av data, som ett resultat av vilket han får ungefärliga, troliga, motsägelsefulla egenskaper för modellering.
Med hjälp av receptorskärmen ställer användaren in värdena för sin excitation baserat på ganska tillförlitliga data, men ibland med hänsyn till alternativen antingen - eller (delvis spännande olika receptorer), ibland på ett infall, ibland bara hoppa över indikatorer. Indikatorer som tidigare rangordning och migration är ännu inte kända, men resultatet förväntas användas i framtiden.
Efter att ha angett data på skärmen på utdataskiktet, vittnar en ljus prick nära outsiderområdet vältaligt om skyddet av den civila lagstiftningen om ett icke-våldsamt val av ett beslut om lämpligheten att investera rättfärdigt ackumulerat kapital.
Koordinaterna för denna punkt på skärmen bestäms av den välkända formeln för att hitta medelvärdet av koordinaterna för de emitterade neuronerna från de banker som den kontrollerade banken är nära, och av storleken på deras excitation. Men enligt samma formler, på grundval av betygen från de markerade bankerna, hittas ratingen för banken som studeras!
Användaren kan bestämma sig för att komplettera kunskapsbasen och följaktligen det neurala nätverket med information om den nya banken, vilket är tillrådligt om expertråden har kritiserat resultatet avsevärt och därmed indikerar ett fel i det neurala nätverket. Du behöver bara använda alternativet. Lägg till, som ett resultat av vilket en dialog mellan datorn och användaren initieras:
- Du vill ändra betyget - Ja.
- Nytt betygsvärde --...
- Spara!
Sedan tilldelas neuronen i utgångsskiktet med de hittade koordinaterna till den nya banken. Dess anslutningar bildas med de receptorer som gavs spänning när man skrev in information om banken. Vikten av varje anslutning antas vara lika med värdet av exciteringen av motsvarande neuronreceptor som användaren matat in. Nu har kunskapsbasen kompletterats på samma sätt som listan över artilleribatteriuppsättningar som riktats efter att ha träffat ett annat mål.
En betydande påtvingad ratingförändring kan dock kräva att den markerade punkten flyttas till området för banker med motsvarande ratingnivå, dvs. det är nödvändigt att tilldela en annan neuron i utgångsskiktet till denna bank, i ett annat område på skärmen. Den installeras också som ett resultat av dialogen mellan datorn och användaren.
Rättelse och utveckling. Ovan har vi redan nämnt behovet och möjligheten av konstant förfining och utveckling av det neurala nätverket. Du kan ändra idén om referensbankens avancemang (verklig eller idealisk) och komplettera kunskapsbasen, d.v.s. detta neurala nätverk. Du kan justera länkvikterna som ett mått på hur individuella indikatorer påverkar resultatet.
Du kan ange nya indikatorer med deras vikter, överväga nya lösningar och fastställa graden av påverkan på dem av samma eller nya indikatorer. Det är möjligt att anpassa det neurala nätverket för att lösa relaterade problem, med hänsyn till inflytandet av individuella indikatorer på migrationen av banker (övergång från en ratingnivå till en annan), etc.
Slutligen, genom att köpa denna mjukvaruprodukt med ett vänligt gränssnitt och utmärkt service, med en utvecklad uppsättning funktioner för att transformera ett neuralt nätverk, kan du göra om den för en helt annan uppgift, till exempel för ett spännande spel med järnvägsroulett, som vi avser att fokusera på nedan.
Sammanfattningsvis noterar vi att i ekonomin och näringslivet, såväl som i hanteringen av komplexa objekt, råder beslutssystem, där varje situation bildas på grundval av ett oföränderligt antal faktorer. Varje faktor representeras av en variant eller ett värde från en uttömmande uppsättning, dvs. varje situation representeras av en konjunktion, där uttalanden om alla faktorer som det neurala nätverket bildas av nödvändigtvis är involverade. Då har alla konjunktioner (situationer) lika många påståenden. Om i detta fall två olika situationer leder till olika beslut, är motsvarande neurala nätverk perfekt. Attraktionskraften hos sådana neurala nätverk ligger i deras reducerbarhet till enskiktiga. Om vi utför multiplikationen av lösningar (se avsnitt 5.2), så får vi ett perfekt neuralt nätverk (utan återkoppling).
Uppgiften för denna sektion kan reduceras till konstruktionen av ett perfekt neuralt nätverk, undersektion. 6.2, samt till exempel uppgiften att bedöma landrisk m.m.
Slutsats
Fördelningen av excitationsvärdena för neuronerna i utgångsskiktet, och oftast neuronen med det maximala excitationsvärdet, gör det möjligt att fastställa en överensstämmelse mellan kombinationen och värdena för excitationer på ingångsskiktet (bild på näthinnan) och det mottagna svaret (vad är det). Således bestämmer detta beroende möjligheten till en logisk slutsats av formen "om - då." det vill säga de tjänar till att länka och memorera relationerna "premiss - effekt." Anslutningen av substrukturerna i det neurala nätverket gör det möjligt för en att erhålla ”långa” logiska kedjor baserade på sådana relationer.
Härav följer att nätverket fungerar i två lägen: i inlärningsläge och i igenkänningsläge (driftläge).
I träningsläget bildas logiska kedjor.
I igenkänningsläget bestämmer det neurala nätverket, baserat på den presenterade bilden, med hög tillförlitlighet vilken typ det tillhör, vilka åtgärder som ska vidtas etc.
Man tror att det finns upp till 100 miljarder neuroner i den mänskliga hjärnan. Men nu är vi inte intresserade av hur en neuron fungerar, där det finns upp till 240 kemiska reaktioner. Vi är intresserade av hur neuronen fungerar på den logiska nivån, hur den utför logiska funktioner. Implementeringen av endast dessa funktioner bör bli grunden och medlet för artificiell intelligens. Genom att förkroppsliga dessa logiska funktioner är vi redo att bryta mot fysikens grundläggande lagar, till exempel lagen om energibevarande. När allt kommer omkring förlitar vi oss inte på fysisk modellering, utan på en tillgänglig, universell - dator.
Så vi fokuserar på den "(direkta" användningen av neurala nätverk i artificiell intelligensuppgifter. Men deras tillämpning sträcker sig till lösningen av andra uppgifter. överföringsfunktion (så kallade sigmoil-anslutningar baserade på exponentens deltagande i bildandet av överföringsfunktionen används ofta), speciellt utvalda och dynamiskt uppdaterade vikter. I det här fallet används egenskaperna för konvergens av värdena för excitation av neuroner, självoptimering. När ingångsvektorn för excitationer tillförs efter ett visst antal klockcykler i det neurala nätverket, är excitationsvärdena för neuronerna i utgångsskiktet (i vissa modeller är alla neuroner i ingångsskiktet neuroner i utgångsskiktet och andra inte) konvergerar till vissa värden. De kan till exempel indikera vilken referens som är mer lik "bullrig". ogiltig indatabild eller något. hur man hittar en lösning på ett problem. Till exempel det berömda Hopfield-nätverket. även med restriktioner, kan lösa problemet med resande säljare - ett problem med exponentiell komplexitet. Hamming-nätverket implementerar framgångsrikt associativt minne. Kohonen-nätverk (Kohonen-kartor), tillagd 2011-06-27
Uppgiften att analysera affärsverksamhet, faktorer som påverkar beslutsfattande. Modern informationsteknik och neurala nätverk: principer för deras arbete. Utredning av användningen av neurala nätverk i uppgifterna att prognostisera ekonomiska situationer och fatta beslut.
avhandling, tillagd 2011-11-06
Beskrivning av den tekniska processen för pappersfyllning. Design av pappersmaskin. Motivering för användningen av neurala nätverk för att styra bildandet av en pappersbana. Matematisk modell av en neuron. Modellera två strukturer av neurala nätverk.
terminsuppsats, tillagd 2012-10-15
Sätt att använda neurala nätverksteknologier i system för intrångsdetektering. Expertsystem för att upptäcka nätverksattacker. Konstgjorda nätverk, genetiska algoritmer. Fördelar och nackdelar med intrångsdetekteringssystem baserade på neurala nätverk.
test, tillagt 2015-11-30
Konceptet med artificiell intelligens som en egenskap hos automatiska system för att ta på sig individuella funktioner av mänsklig intelligens. Expertsystem inom medicinområdet. Olika tillvägagångssätt för att bygga artificiell intelligens. Skapande av neurala nätverk.
presentation tillagd 2015-05-28
Studie av problemet och utsikterna för att använda neurala nätverk på radiella funktioner för att förutsäga de viktigaste ekonomiska indikatorerna: bruttonationalprodukten, Ukrainas nationalinkomst och konsumentprisindex. Utvärdering av resultat.
terminsuppsats, tillagd 2014-12-14
Konceptet och egenskaperna hos artificiella neurala nätverk, deras funktionella likhet med den mänskliga hjärnan, principen för deras arbete, användningsområden. Expertsystem och tillförlitlighet för neurala nätverk. Modell av en artificiell neuron med en aktiveringsfunktion.
abstrakt, tillagt 2011-03-16
Kärnan och funktionerna hos artificiella neurala nätverk (ANN), deras klassificering. Strukturella delar av en artificiell neuron. Skillnader mellan ANN och von Neumann arkitekturmaskiner. Konstruktion och utbildning av dessa nätverk, områden och framtidsutsikter för deras tillämpning.
presentation tillagd 2013-10-14
Användningen av neurodatorer på den ryska finansmarknaden. Tidsserieprognoser baserad på neurala nätverksbearbetningsmetoder. Fastställande av kurser för obligationer och aktier i företag. Tillämpning av neurala nätverk på problemen med analys av utbytesaktivitet.
terminsuppsats, tillagd 2009-05-28
Skapelsens historia och huvudriktningarna i modellering av artificiell intelligens. Inlärningsproblem för visuell perception och igenkänning. Utveckling av element av intelligens hos robotar. Forskning inom området neurala nätverk. Wieners feedbackprincip.
UDC 004.38.032.26
O. V. KONYUKHOVA, K. S. LAPOCHKINA
O. V. KONUKHOVA, K. S. LAPOCHKINA
TILLÄMPNINGEN AV NEURALNÄTVERK I EKONOMI OCH RELEVANSEN AV DERAS ANVÄNDNING FÖR ATT SKAPA EN KORTSIKTIG BUDGETPROGNOS
TILLÄMPNING AV NEURALNÄTVERK I EKONOMI OCH EN Brådskande ANVÄNDNING AV DESSA GENOM ATT UTARBETANDE AV EN KORTFRISTIG PROGNOS FÖR BUDGETEN
Den här artikeln beskriver tillämpningen av neurala nätverk inom ekonomi. Processen för att prognostisera Ryska federationens budget och relevansen av att använda neurala nätverk för att upprätta en kortsiktig budget övervägs.
Nyckelord: ekonomi, Ryska federationens budget, budgetprognoser, neurala nätverk, genetiska algoritmer.
I denna artikel beskrivs tillämpningen av neurala nätverk i ekonomin. Processen för att prognostisera Ryska federationens budget och en brådskande tillämpning av neurala nätverk för att utarbeta den kortsiktiga budgeten övervägs.
Nyckelord: ekonomi, Ryska federationens budget, budgetprognoser, neurala nätverk, genetiska algoritmer.
4) automatisk gruppering av objekt.
Ett av de intressanta försöken att skapa en mekanism för rationell hantering av en deprimerad ekonomi tillhör den engelske cybernetikern Stafford Beer. Han föreslog principerna för kontroll, som blev allmänt kända, baserade på neurofysiologiska mekanismer. Han betraktade modeller av produktionssystem som ett mycket komplext förhållande mellan input (resursflöden), interna, osynliga element och output (resultat). Indata från modellerna var ganska generaliserade index, vars huvudsakliga omedelbart återspeglade produktionen av en viss produktion, det kände behovet av resurser och produktivitet. De lösningar som föreslagits för att sådana system ska fungera effektivt gjordes efter att alla möjliga alternativ i denna situation hittats och diskuterats. Det bästa beslutet fattades av en majoritet av rösterna från de chefer och experter som deltog i diskussionen. För detta ändamål försågs systemet med ett situationsanpassat rum, utrustat med lämpliga tekniska medel. Det tillvägagångssätt som S. Beer föreslog för att skapa ett ledningssystem visade sig vara effektivt för att hantera inte bara stora industriföreningar, som ett stålföretag, utan även den chilenska ekonomin på 70-talet.
Liknande principer användes i metoden för gruppredovisning av argument (MGHA) av en ukrainsk cybernetiker för att modellera ekonomin i ett välmående England. Tillsammans med ekonomer (Parks et al.), som föreslog mer än tvåhundra oberoende variabler som påverkar bruttoinkomsten, identifierade han flera (fem till sex) huvudfaktorer som bestämmer värdet av outputvariabeln med en hög grad av noggrannhet. Utifrån dessa modeller utvecklades olika alternativ för att påverka ekonomin för att öka den ekonomiska tillväxten i olika takter av sparande, inflation och arbetslöshet.
Den föreslagna metoden för gruppövervägande av argument är baserad på principen om självorganisering av modeller av komplexa, särskilt ekonomiska system, och gör det möjligt att bestämma komplexa dolda beroenden i data som inte upptäcks av vanliga statistiska metoder. Denna metod användes framgångsrikt av A. Och Ivakhnenko för att bedöma ekonomins tillstånd och förutsäga dess utveckling i länder som USA, Storbritannien, Bulgarien och Tyskland. använde ett stort antal oberoende variabler (från femtio till tvåhundra) som beskriver ekonomins tillstånd och påverkar bruttoinkomsten i de studerade länderna. Baserat på analysen av dessa variabler med hjälp av metoden för gruppredovisning av argument, identifierades de viktigaste, signifikanta faktorerna som med en hög grad av noggrannhet bestämmer värdet på outputvariabeln (bruttoinkomst).
Forskning i denna riktning har haft en stimulerande effekt på utvecklingen av neurala nätverksmetoder, som har använts intensivt de senaste åren på grund av deras förmåga att utvinna erfarenhet och kunskap från en liten klassificerad sekvens. Efter träning i sådana sekvenser kan neurala nätverk lösa komplexa icke-formaliserbara problem på samma sätt som experter gör utifrån sin kunskap och intuition. Dessa fördelar blir särskilt betydande under villkoren för en övergångsekonomi, som kännetecknas av ojämna utvecklingstakt, olika inflationstakt, kort varaktighet samt ofullständighet och inkonsekvens av kunskap om de nuvarande ekonomiska fenomenen.
Det är allmänt känt att han framgångsrikt tillämpade principerna för självorganisering av modeller av komplexa ekonomiska system för att bygga ett neuralt nätverk för att lösa problem med analys och modellering av ekonomisk utveckling i Mordovia och Penza-regionen.
Ett typiskt exempel på framgångsrik tillämpning av neural computing i finanssektorn är kreditriskhantering. Som ni vet, innan de utfärdar ett lån, utför banker komplexa statistiska beräkningar av låntagarens ekonomiska tillförlitlighet för att bedöma sannolikheten för sina egna förluster från otidig avkastning av medel. Sådana beräkningar baseras vanligtvis på en bedömning av kredithistoriken, dynamiken i företagets utveckling, stabiliteten hos dess viktigaste finansiella indikatorer och många andra faktorer. En välkänd amerikansk bank testade en neural beräkningsmetod och kom fram till att samma problem löses snabbare och mer exakt med beräkningar av detta slag som redan har gjorts. Till exempel, i ett av fallen med att bedöma 100 tusen bankkonton, identifierade ett nytt system baserat på neurala beräkningar över 90% av potentiella försummelser.
Ett annat mycket viktigt tillämpningsområde för neural computing på det finansiella området är att förutsäga situationen på aktiemarknaden. Standardmetoden för detta problem är baserad på en strikt fast uppsättning "spelregler", som så småningom förlorar sin effektivitet på grund av förändringar i handelsförhållandena på börsen. Dessutom visar sig system byggda på basis av detta tillvägagångssätt vara för långsamma för situationer som kräver omedelbart beslutsfattande. Det är därför de viktigaste japanska företagen som verkar på värdepappersmarknaden beslutade att tillämpa metoden för neural beräkning. I ett typiskt system baserat på ett neuralt nätverk lades information in med en total volym på 33 års affärsverksamhet för flera organisationer, inklusive omsättning, tidigare aktiekurs, inkomstnivåer etc. jämfört med det statistiska tillvägagångssättet gav en förbättring av prestanda i generellt med 19 %.
En av de mest avancerade neurala beräkningsteknikerna är genetiska algoritmer som efterliknar evolutionen av levande organismer. Därför kan de användas som en optimerare av parametrar för neurala nätverk. Ett liknande system för att förutsäga prestanda för långfristiga värdepapperskontrakt med hög säkerhet utvecklades och installerades på en Sun-arbetsstation på Hill Samuel Investment Management. Vid simulering av flera handelsstrategier uppnåddes en noggrannhet på 57% i att förutsäga marknadsrörelsens riktning. Försäkringsföretaget TSB General Insurance i Newport använder en liknande metod för att förutsäga risknivån i privata låneförsäkringar. Detta neurala nätverk är självlärande baserat på statistiska uppgifter om tillståndet för arbetslösheten i landet.
Trots att finansmarknaden i Ryssland ännu inte har stabiliserats och, med argument ur en matematisk synvinkel, håller dess modell på att förändras, vilket å ena sidan är kopplat till förväntan om en gradvis kollaps av värdepappersmarknaden och en ökning av andelen av aktiemarknaden i samband med flödet av investeringar, både inhemskt och utländskt kapital, och å andra sidan - med instabiliteten i den politiska kursen, kan man ändå märka uppkomsten av företag som behöver använda olika statistiska metoder från traditionella, såväl som utseendet på marknaden av mjukvaruprodukter och datorer med neurala paket för att emulera neurala nätverk på datorer i IBM-serien och till och med specialiserade neurokort baserade på skräddarsydda neurochips.
I synnerhet är en av de första kraftfulla neurodatorerna för ekonomiskt bruk, CNAPS PC / 128, baserad på 4 neuroBIS från Alaptive Solutions, redan i drift i Ryssland. Enligt företaget Tora-Center har antalet organisationer som använder neurala nätverk för att lösa sina problem redan omfattat centralbanken, krisministeriet, skatteinspektionen, mer än 30 banker och mer än 60 finansiella företag. Några av dessa organisationer har redan publicerat resultaten av sin verksamhet inom området användning av neurodatorer.
Av det föregående följer att för närvarande är användningen av neurala nätverk för att prognostisera en kortsiktig budget ett brådskande ämne för forskning.
Sammanfattningsvis bör det noteras att användningen av neurala nätverk inom alla områden av mänsklig verksamhet, inklusive inom området för finansiella tillämpningar, ökar, delvis av nödvändighet och på grund av de breda möjligheterna för vissa, på grund av prestigen för andra och på grund av intressanta applikationer för tredje part.
BIBLIOGRAFI
1. Ryska federationens federala lag av 01.01.2001 (som ändrat den 01.01.2001) "Om statliga prognoser och program för social och ekonomisk utveckling av Ryska federationen" [Text]
2. Beer S. Hjärnan i företaget [Text] / S. Beer. - M .: Radio och kommunikation, 1993 .-- 524 sid.
3. Galushkin, neurodatorer i finansiell verksamhet [Text] /. - Novosibirsk: Nauka, 2002 .-- 215s.
4., Muller prediktiva modeller [Text] /, - Kiev: Technics, 1985. - 225 s.
5. Kleshchinsky, prognosmetoder i budgetprocessen [Text] / // Elektronisk tidskrift Corporate finance, 2011. - № 3 (19) - s. 71 - 78.
6. Rutkovskaya M., Plinsky L. Neurala nätverk, genetiska algoritmer och fuzzy system: Per. från polska [Text] / M. Rutkovskaya, L. Plinsky -: Hotline - Telekom, 20-talet.
7., Kostyunin-lösningar på neurala nätverk med optimal komplexitet [Text] /, // Automation och modern teknik, 1998. - Nr 4. - P. 38-43.
Federal State Educational Institute of Higher Professional Education "State University - Educational, Scientific and Industrial Complex", Orel
Kandidat för tekniska vetenskaper, docent, docent vid institutionen för "informationssystem"
E-post: ***** @ *** ru
Lapochkin Kristina Sergeevna
Federal State Educational Institute of Higher Professional Education "State University - Educational, Scientific and Industrial Complex", Orel
Elev i grupp 11-PI (m)
Fuzzy-neurala nätverk utför slutsatser baserade på apparaten för fuzzy logik, men parametrarna för medlemskapsfunktionerna justeras med hjälp av inlärningsalgoritmer för neurala nätverk (NN). Därför, för att välja parametrarna för sådana nätverk, kommer vi att tillämpa felbackpropagationsmetoden som ursprungligen föreslagits för att träna en flerskiktsperceptron. För detta presenteras den fuzzy kontrollmodulen i form av ett flerskiktsnätverk. Ett fuzzy neuralt nätverk består som regel av fyra lager: ett fasifieringslager för indatavariabler, ett lager för aggregering av tillståndsaktiveringsvärden, ett aggregeringslager för fuzzy regler och ett utdatalager. De mest utbredda för närvarande är de fuzzy neurala nätverksarkitekturerna som ANFIS och TSK. Det är bevisat att sådana nätverk är universella approximatorer. Algoritmer för snabb inlärning och tolkning av ackumulerad kunskap - dessa faktorer har gjort fuzzy neurala nätverk till ett av de mest lovande och effektiva mjuka beräkningsverktygen idag.
Neurala nätverk inom ekonomi
Det område av AI som har funnit den mest utbredda användningen är neurala nätverk. Deras huvudsakliga egenskap är förmågan att självstudier med hjälp av specifika exempel. Neurala nätverk är att föredra där det finns mycket indata där mönster är dolda. Det är tillrådligt att använda neurala nätverksmetoder i problem med ofullständig eller "bullrig" information, såväl som i de där lösningen kan hittas intuitivt. Neurala nätverk används för att förutsäga marknader, optimera råvaror och kassaflöden, analysera och sammanfatta opinionsundersökningar, förutsäga dynamiken i politiska betyg, optimera produktionsprocessen, omfattande diagnostik av produktkvalitet och mycket, mycket mer. Neurala nätverk används i allt större utsträckning i verkliga affärsapplikationer. Inom vissa områden, såsom bedrägeriupptäckt och riskbedömning, har de blivit de obestridda ledarna bland de metoder som används. Deras användning i prognossystem och marknadsundersökningssystem växer ständigt. Eftersom ekonomiska, finansiella och sociala system är mycket komplexa och är resultatet av olika människors handlingar och motåtgärder, är det mycket svårt (om inte omöjligt) att skapa en komplett matematisk modell, med hänsyn till alla möjliga handlingar och motåtgärder. Det är nästan omöjligt att i detalj approximera en modell baserad på sådana traditionella parametrar som nyttomaximering eller vinstmaximering. I system av sådan komplexitet är det naturligt och mest effektivt att använda modeller som direkt imiterar samhällets och ekonomins beteende. Och det är precis vad den neurala nätverksmetodiken kan erbjuda.
Följande är de områden där effektiviteten av användningen av neurala nätverk har bevisats i praktiken:
För finansiella transaktioner:
- · Förutsäga kundbeteende.
- · Prognos och riskbedömning av den kommande transaktionen.
- · Förutsäga möjliga bedrägliga aktiviteter.
- · Prognostisering av saldon på bankens korrespondentkonton.
- · Prognostisera rörelsen av kontanter, volymer av cirkulerande tillgångar.
- · Prognos av ekonomiska parametrar och aktieindex.
För att planera företagets arbete:
- · Prognos av försäljningsvolymer.
- · Prognostisera utnyttjandet av produktionskapacitet.
- · Prognostisera efterfrågan på nya produkter.
För affärsanalytiker och beslutsstöd:
- · Identifiera trender, korrelationer, mönster och undantag i stora datamängder.
- · Analys av arbetet i företagets filialer.
- · Jämförande analys av konkurrerande företag.
Andra applikationer:
- · Värdevärdering av fastigheter.
- · Kvalitetskontroll av produkter.
- · Övervakningssystem för utrustningens tillstånd.
- · Design och optimering av kommunikationsnät, strömförsörjningsnät.
- · Prognostisera energiförbrukning.
- · Igenkänning av handskrivna tecken, inkl. automatisk igenkänning och signaturautentisering.
- · Igenkänning och bearbetning av video- och ljudsignaler.
Neurala nätverk kan också användas i andra uppgifter. De huvudsakliga förutbestämda villkoren för deras användning är närvaron av "historiska data", med vilka det neurala nätverket kan lära sig, såväl som omöjligheten eller ineffektiviteten att använda andra, mer formella metoder. Det oberoende expertrådet för strategisk analys av utrikes- och inrikespolitiska frågor vid federationsrådet för forskningsinstitutet för artificiell intelligens presenterade projektet "En ny generationsteknologi baserad på underbestämda beräkningar och dess användning för att utveckla en experimentell modell för makroekonomi i Ryssland Federation." Det blev möjligt att beräkna resultatet av varje åtgärd eller förslag som rör landets budget under många år framöver. Systemet låter dig se hur intäktssidan, budgetunderskottet och volymen av industriproduktion kommer att förändras som svar på till exempel en höjning av skatterna. Du kan också se hur mycket pengar som lämnade budgeten förra året: en elektronisk maskin, enligt forskare, kan enkelt klara en sådan uppgift. Hon kommer inte ens behöva förklara begreppet "black cash". Det omvända problemet kan också lösas. Vad behöver till exempel göras för att 2020 ska produktionsvolymen öka, eller åtminstone inte falla? Maskinen kommer att indikera den nedre och övre gränsen för värdena i båda fallen för de släppta budgetpengarna i alla parametrar som på något sätt påverkar produktionen. Dessutom är det möjligt att ta reda på, inte genom horoskopet och utan hjälp av magiker, en möjlig sekvens av "kritiska" och "framgångsrika" ögonblick i utvecklingen av landets ekonomi med de givna initiala uppgifterna. Utvecklarna av projektet har hittills bara skapat en demomodell som täcker cirka 300 parametrar och perioden från 1990 till 1999. Men för normal drift behöver du minst 1000 parametrar. Och sådant arbete kan utföras om medel avsätts för det. Det är nödvändigt att utföra mycket tillämpat arbete, grundläggande forskning behövs om båda huvudkomponenterna i projektet - matematiska och ekonomiska. Här behövs ett seriöst statligt materiellt stöd. Införandet av den nuvarande datormodellen för makroekonomi och Ryska federationens statsbudget kommer att automatisera beredningen av de initiala parametrarna för statsbudgeten för nästa år, godkännandet av den slutliga versionen för godkännande i parlamentet, stöd, bedömning och kontroll budgetgenomförande i alla dess skeden. Intresset för artificiella neurala nätverk i Ryssland har vuxit enormt under de senaste åren. Förmågan att snabbt lära sig och slutsatsernas tillförlitlighet gör att vi kan rekommendera expertsystem för neurala nätverk som ett av de oumbärliga verktygen i många aspekter av modern verksamhet. Neurala nätverk har en enorm fördel framför det traditionella arbetsintensiva och mer tidskrävande sättet att generalisera mänskliga experters kunskap. Neurala nätverkstekniker är tillämpbara inom nästan alla områden, och i uppgifter som att prognostisera aktiekurser och växelkurser har de redan blivit ett välbekant och allmänt använt verktyg. Den utbredda penetrationen av neurala nätverksteknologier i moderna företag är bara en tidsfråga. Införandet av ny högteknologisk teknik är en svår process, men praxis visar att investeringar inte bara lönar sig och ger fördelar, utan också ger dem som använder dem påtagliga fördelar. Användningen av neurala nätverk inom finans är baserad på ett grundläggande antagande: att erkännande ersätts med förutsägelse. I stort sett förutsäger inte det neurala nätverket framtiden, utan "erkänner" i det nuvarande tillståndet på marknaden en tidigare uppkommen situation och återger den efterföljande reaktionen från marknaden.
Den finansiella marknaden är ganska trög, den har sin egen "fördröjda reaktion", att veta vilken det är möjligt att exakt beräkna den framtida situationen. Hur exakt beror på marknadsförhållanden och operatörskvalifikationer. Därför är det naivt att tro att det neurala nätverket automatiskt kommer att förutsäga kurserna för huvudindikatorerna - den nationella valutan eller till exempel ädla metaller på instabila marknader. Men i alla marknadssituationer finns det instrument som upprätthåller stabilitet. Till exempel, när dollarn hoppar, är dessa "avlägsna" terminer, vars reaktion sträcker sig över flera dagar och är förutsägbar. Förresten, under perioder av marknadschocker får spelarna vanligtvis panik, vilket förbättrar fördelarna för ägaren av ett bra analytiskt verktyg. Hundratals världsberömda och små nystartade företag arbetar just nu med att skapa neurala nätverk för olika ändamål. Världsmarknaden erbjuder mer än hundra neurala nätverkspaket, främst amerikanska. År 2005 översteg den totala volymen på marknaden för neurala nätverk 10 miljarder dollar. Och praktiskt taget strävar varje utvecklare av traditionella analytiska paket idag efter att inkludera neurala nätverk i nya versioner av sina program. I USA används neurala nätverk i alla större bankers analytiska system. Enbart försäljningen av det neurala nätverkspaketet "Brain Maker Pro" är jämförbar med försäljningen av det mest populära tekniska analyspaketet MetaStock (mer än 20 000 exemplar av Brain Maker Pro har sålts i USA).
Paketet "The AI Trilogy" har visat sig väl. ("Trilogy of Artificial Intelligence") av det amerikanska företaget "Ward Systems Group". Detta är en uppsättning av tre program, som vart och ett kan användas både oberoende och i kombination med de andra. Så programmet "NeuroShell II" är en uppsättning av 16 typer av neurala nätverk, "NeuroWindows" är ett neuralt nätverksbibliotek med källkoder, "GeneHunter" är ett genetiskt optimeringsprogram. Tillsammans bildar de en kraftfull "konstruktör" som låter dig bygga analytiska system av vilken komplexitet som helst. "The AI Trilogy" är mycket efterfrågad på den amerikanska marknaden. Paketet är installerat i 150 största amerikanska banker. Han har vunnit många prestigefyllda tävlingar av populära finansiella publikationer och hjälper till att hantera miljarder dollar i kapital. Du Pont (US Standards Institute och FBI) anser att "Artificial Intelligence Trilogy" är den bästa för att lösa olika problem. Intressant och betydelsefullt är det föga kända faktumet att nyckelkomponenterna i detta paket skrevs av ryska programmerare. Paketet har sitt utseende att tacka för en grupp utvecklare från ett litet Moskvaföretag "Neuroproject" under ledning av professor Persiyatsev.
I mer än tre år utförde hon order från "Ward Systems Group" och hittade framgångsrika lösningar. Vi kan säga att ryska program styr USA:s finanser och FBI:s uppgifter. Hur användbart kan paketet vara för finansiärer? Kommer han att kunna arbeta på vår oförutsägbara marknad, där ett beslut från centralbanken omedelbart kan störta marknaden? I väntan på dessa frågor erbjuder paketägarna en dedikerad konsulttjänst. Ett särskilt avtal tecknas med en bank vars analytiker inte tror på förutsägbarheten på vår marknad. Under en viss period: två veckor, en månad eller mer, mot en symbolisk avgift, förses banken dagligen med prognoser för morgondagen (eller en vecka framåt) på kurserna för de givna finansiella instrumenten. Om prognosen konsekvent visar acceptabel noggrannhet, åtar sig banken att köpa ett analytiskt komplex tillsammans med inställningarna. Och det var inte ett enda fall då en kund vägrade ett köp. Ett illustrativt och imponerande fall ägde rum mellan valen, då en av storbankerna genomförde ett liknande test av paketet. Priserna på värdepapper dansade, politikerna föll och steg, men varje kväll fick banken en prognos med en uppsättning av morgondagens priser (mini - maxi - vägt genomsnitt - nära) för sexton GKO-papper. Mindre än två veckor senare ingick banken ett avtal om leverans av ett analytiskt komplex som kan upprätthålla effektivitet även i sådana turbulenta och oförutsägbara situationer.
- · Rika möjligheter. Neurala nätverk är en extremt kraftfull modelleringsteknik som kan reproducera extremt komplexa beroenden. I synnerhet är neurala nätverk icke-linjära till sin natur. Under många år har linjär modellering varit den huvudsakliga modelleringstekniken inom de flesta områden på grund av dess välutvecklade optimeringsprocedurer. I problem där linjär approximation är otillfredsställande (och det finns en hel del av dem) fungerar linjära modeller dåligt. Dessutom klarar neurala nätverk "dimensionens förbannelse", som inte tillåter simulering av linjära beroenden i fallet med ett stort antal variabler.
- · Lätt att använda. Neurala nätverk lär sig genom exempel. En användare av neuralt nätverk plockar upp representativ data och kör sedan en inlärningsalgoritm som automatiskt uppfattar datastrukturen. Samtidigt krävs förstås att användaren har någon form av heuristisk kunskap om hur man väljer och förbereder data, väljer önskad nätverksarkitektur och tolkar resultaten, men den kunskapsnivå som krävs för en framgångsrik tillämpning av neurala nätverk är mycket mer blygsam än att till exempel använda traditionella statistiska metoder.
Neurala nätverk är intuitivt attraktiva eftersom de är baserade på en primitiv biologisk modell av nervsystem. I framtiden kan utvecklingen av sådana neurobiologiska modeller leda till skapandet av verkligt tänkande datorer. Samtidigt är de redan "enkla" neurala nätverken som ST Neural Networks-systemet bygger ett kraftfullt vapen i en tillämpad statistikers arsenal.