 Entrada
EntradaRedes neuronales y ejemplos de su uso en la economía. "Redes neuronales
Buenas tardes, mi nombre es Natalia Efremova y soy científica investigadora en NtechLab. Hoy hablaré de vistas. Redes neuronales y su aplicación.
Primero, permítanme decir algunas palabras sobre nuestra empresa. La empresa es nueva, quizás muchos de ustedes no saben lo que hacemos. El año pasado ganamos el desafío MegaFace. Esta es una competencia internacional de reconocimiento facial. En el mismo año se inauguró nuestra empresa, es decir, llevamos en el mercado alrededor de un año, incluso un poco más. Por ello, somos una de las empresas líderes en reconocimiento facial y procesamiento biométrico de imágenes.
La primera parte de mi informe estará dirigida a aquellos que no están familiarizados con las redes neuronales. Estoy directamente involucrado en el aprendizaje profundo. He estado trabajando en esta área durante más de 10 años. Aunque apareció hace poco menos de una década, existían unos rudimentos de redes neuronales que parecían un sistema de aprendizaje profundo.
En los últimos 10 años, el aprendizaje profundo y la visión artificial se han desarrollado a un ritmo increíble. Todo lo que se ha hecho significativo en esta área ha sucedido en los últimos 6 años.
Hablaré de aspectos prácticos: dónde, cuándo, qué usar en términos de aprendizaje profundo para el procesamiento de imágenes y videos, para el reconocimiento de imágenes y rostros, ya que trabajo para una empresa que hace esto. Hablaré un poco sobre el reconocimiento de emociones, qué enfoques se utilizan en los juegos y la robótica. También hablaré sobre la aplicación no estándar del aprendizaje profundo, algo que recién está saliendo de las instituciones científicas y todavía se usa poco en la práctica, cómo se puede aplicar y por qué es difícil de aplicar.
El informe constará de dos partes. Dado que la mayoría de la gente está familiarizada con las redes neuronales, primero explicaré rápidamente cómo funcionan las redes neuronales, qué son las redes neuronales biológicas, por qué es importante para nosotros saber cómo funcionan, qué son las redes neuronales artificiales y qué arquitecturas se utilizan en qué áreas
Pido disculpas de inmediato, saltaré un poco a la terminología en inglés, porque ni siquiera sé la mayor parte de cómo se llama en ruso. Quizás tú también.
Entonces, la primera parte del informe estará dedicada a las redes neuronales convolucionales. Explicaré cómo funciona el reconocimiento de imágenes de la red neuronal convolucional (CNN) utilizando un ejemplo de reconocimiento facial. Hablaré un poco sobre las redes neuronales recurrentes (RNN) y el aprendizaje por refuerzo usando el ejemplo de los sistemas de aprendizaje profundo.
Como una aplicación no estándar de las redes neuronales, hablaré sobre cómo funciona CNN en medicina para el reconocimiento de imágenes de vóxel, cómo se utilizan las redes neuronales para reconocer la pobreza en África.
¿Qué son las redes neuronales?
Curiosamente, las redes neuronales biológicas sirvieron como prototipo para crear redes neuronales. Quizás muchos de ustedes saben cómo programar una red neuronal, pero creo que de dónde vino, algunos no. Dos tercios de toda la información sensorial que nos llega proviene de los órganos visuales de percepción. Más de un tercio de la superficie de nuestro cerebro está ocupado por las dos áreas visuales más importantes: la vía visual dorsal y la vía visual ventral.La vía visual dorsal comienza en la zona visual primaria, en la coronilla, y continúa hacia arriba, mientras que la vía ventral comienza en la parte posterior de la cabeza y termina aproximadamente detrás de las orejas. Todo el reconocimiento de patrones importantes que tenemos, todo el significado del que somos conscientes, tiene lugar justo ahí, detrás de las orejas.
¿Por qué es importante? Porque muchas veces es necesario entender las redes neuronales. En primer lugar, todo el mundo habla de ello, y ya estoy acostumbrado a que suceda, y en segundo lugar, el hecho es que todas las áreas que se utilizan en las redes neuronales para el reconocimiento de patrones nos llegaron precisamente desde la vía visual ventral, donde cada una pequeña zona es responsable de su función estrictamente definida.
La imagen nos llega desde la retina, pasa por una serie de zonas visuales y finaliza en la zona temporal.
En los lejanos años 60 del siglo pasado, cuando apenas comenzaba el estudio de las áreas visuales del cerebro, se realizaron los primeros experimentos en animales, pues no existía la resonancia magnética funcional. El cerebro fue examinado usando electrodos implantados en varias zonas visuales.
La primera zona visual fue explorada por David Hubel y Thorsten Wiesel en 1962. Hicieron experimentos con gatos. A los gatos se les mostraron varios objetos en movimiento. A lo que respondieron las células cerebrales fue al estímulo que el animal reconoció. Incluso ahora, muchos experimentos se llevan a cabo de esta manera draconiana. Sin embargo, esta es la forma más efectiva de averiguar qué está haciendo cada pequeña célula de nuestro cerebro.
De la misma manera, se descubrieron muchas más propiedades importantes de las zonas visuales que usamos en el aprendizaje profundo ahora. Una de las propiedades más importantes es el aumento de los campos receptivos de nuestras células a medida que pasamos de las áreas visuales primarias a los lóbulos temporales, es decir, las áreas visuales posteriores. El campo receptivo es esa parte de la imagen que cada célula de nuestro cerebro procesa. Cada célula tiene su propio campo receptivo. Esta misma propiedad se conserva en las redes neuronales, como probablemente todos saben.
Además, con el aumento de los campos receptivos aumentan los estímulos complejos que las redes neuronales suelen reconocer.

Aquí ves ejemplos de la complejidad de los estímulos, las diferentes formas bidimensionales que se reconocen en las áreas V2, V4 y varias partes de los campos temporales en los macacos. También se están llevando a cabo varios experimentos de resonancia magnética.

Aquí puedes ver cómo se llevan a cabo tales experimentos. Esta es una parte de 1 nanómetro de la corteza de TI "unas zonas del mono al reconocer varios objetos. Resaltado donde se reconoce.
Resumamos. Una propiedad importante que queremos adoptar de las áreas visuales es que aumentan los tamaños de los campos receptivos y aumenta la complejidad de los objetos que reconocemos.
visión por computador
Antes aprendimos cómo aplicar esto a la visión por computadora; en general, como tal, no existía. En cualquier caso, no funcionó tan bien como lo hace ahora.Transferimos todas estas propiedades a la red neuronal, y ahora funciona, si no incluye una pequeña digresión a los conjuntos de datos, de los que hablaré más adelante.
Pero primero, un poco sobre el perceptrón más simple. También se forma a imagen y semejanza de nuestro cerebro. El elemento más simple que se asemeja a una célula cerebral es una neurona. Tiene elementos de entrada que por defecto son de izquierda a derecha, ocasionalmente de abajo hacia arriba. A la izquierda están las partes de entrada de la neurona, a la derecha están las partes de salida de la neurona.
El perceptrón más simple es capaz de realizar solo las operaciones más básicas. Para realizar cálculos más complejos, necesitamos una estructura con más capas ocultas.

En el caso de la visión artificial, necesitamos aún más capas ocultas. Y solo entonces el sistema reconocerá de manera significativa lo que ve.
Entonces, qué sucede al reconocer una imagen, te lo diré usando el ejemplo de las caras.
Para nosotros, mirar esta imagen y decir que representa el rostro de la estatua es bastante simple. Sin embargo, hasta 2010, esta era una tarea increíblemente difícil para la visión artificial. Quienes hayan tratado este tema antes de este momento, probablemente sepan lo difícil que fue describir el objeto que queremos encontrar en la imagen sin palabras.
Tuvimos que hacerlo de alguna manera geométrica, describir el objeto, describir la relación del objeto, cómo estas partes pueden relacionarse entre sí, luego encontrar esta imagen en el objeto, compararlas y obtener lo que reconocimos mal. Por lo general, era un poco mejor que lanzar una moneda. Ligeramente mejor que el nivel de oportunidad.
Ahora este no es el caso. Dividimos nuestra imagen en píxeles o en algunos parches: 2x2, 3x3, 5x5, 11x11 píxeles, según convenga a los creadores del sistema en el que sirven como capa de entrada a la red neuronal.
Las señales de estas capas de entrada se transmiten de una capa a otra mediante sinapsis, cada una de las capas tiene sus propios coeficientes específicos. Así pasamos de capa en capa, de capa en capa, hasta llegar a que hemos reconocido la cara.
Convencionalmente, todas estas partes se pueden dividir en tres clases, las denotaremos como X, W e Y, donde X es nuestra imagen de entrada, Y es un conjunto de etiquetas y necesitamos obtener nuestros pesos. ¿Cómo calculamos W?
Dado nuestro X e Y, esto parece ser fácil. Sin embargo, lo que se indica con un asterisco es una operación no lineal muy compleja que, lamentablemente, no tiene inversa. Incluso con 2 componentes dados de la ecuación, es muy difícil calcularla. Por lo tanto, debemos gradualmente, por prueba y error, seleccionando el peso W, asegurarnos de que el error disminuya lo más posible, es deseable que sea igual a cero.

Este proceso se da de forma iterativa, vamos decreciendo constantemente hasta encontrar el valor del peso W, que nos satisface lo suficiente.
Por cierto, ni una sola red neuronal con la que trabajé alcanzó un error igual a cero, pero funcionó bastante bien.

Esta es la primera red que ganó el concurso internacional ImageNet en 2012. Esta es la llamada AlexNet. Esta es la red que primero anunció, que hay redes neuronales convolucionales, y desde entonces, en todas las competencias internacionales, las redes neuronales convolucionales nunca han perdido sus posiciones.
A pesar de que esta red es bastante pequeña (solo tiene 7 capas ocultas), contiene 650.000 neuronas con 60 millones de parámetros. Para aprender iterativamente a encontrar pesos deseados Necesitamos muchos ejemplos.
La red neuronal aprende del ejemplo de una imagen y una etiqueta. Como nos enseñan en la infancia "este es un gato y este es un perro", las redes neuronales se entrenan en una gran cantidad de imágenes. Pero el hecho es que antes de 2010 no había un conjunto de datos lo suficientemente grande que pudiera enseñar tantos parámetros para reconocer imágenes.
Las bases de datos más grandes que existían hasta ese momento eran PASCAL VOC, que tenía solo 20 categorías de objetos, y Caltech 101, que se desarrolló en el Instituto de Tecnología de California. El último tenía 101 categorías y eso era mucho. Aquellos que no pudieron encontrar sus objetos en ninguna de estas bases de datos tuvieron que costar sus bases de datos, lo cual, diré, es terriblemente doloroso.
Sin embargo, en 2010 apareció la base de datos ImageNet, en la que había 15 millones de imágenes, divididas en 22.000 categorías. Esto resolvió nuestro problema de entrenamiento de redes neuronales. Ahora todos los que tengan alguna dirección académica pueden ir fácilmente al sitio de la base, solicitar acceso y obtener esta base para entrenar sus redes neuronales. Responden bastante rápido, en mi opinión, al día siguiente.
En comparación con los conjuntos de datos anteriores, esta es una base de datos muy grande.

El ejemplo muestra cuán insignificante es todo lo que fue antes de ser. Simultáneamente a la base ImageNet, apareció la competición ImageNet, un reto internacional en el que pueden participar todos los equipos que deseen competir.
Este año ganó la red creada en China, tenía 269 capas. No sé cuántos parámetros, sospecho que son demasiados.
Arquitectura de red neuronal profunda
Convencionalmente, se puede dividir en 2 partes: los que estudian y los que no estudian.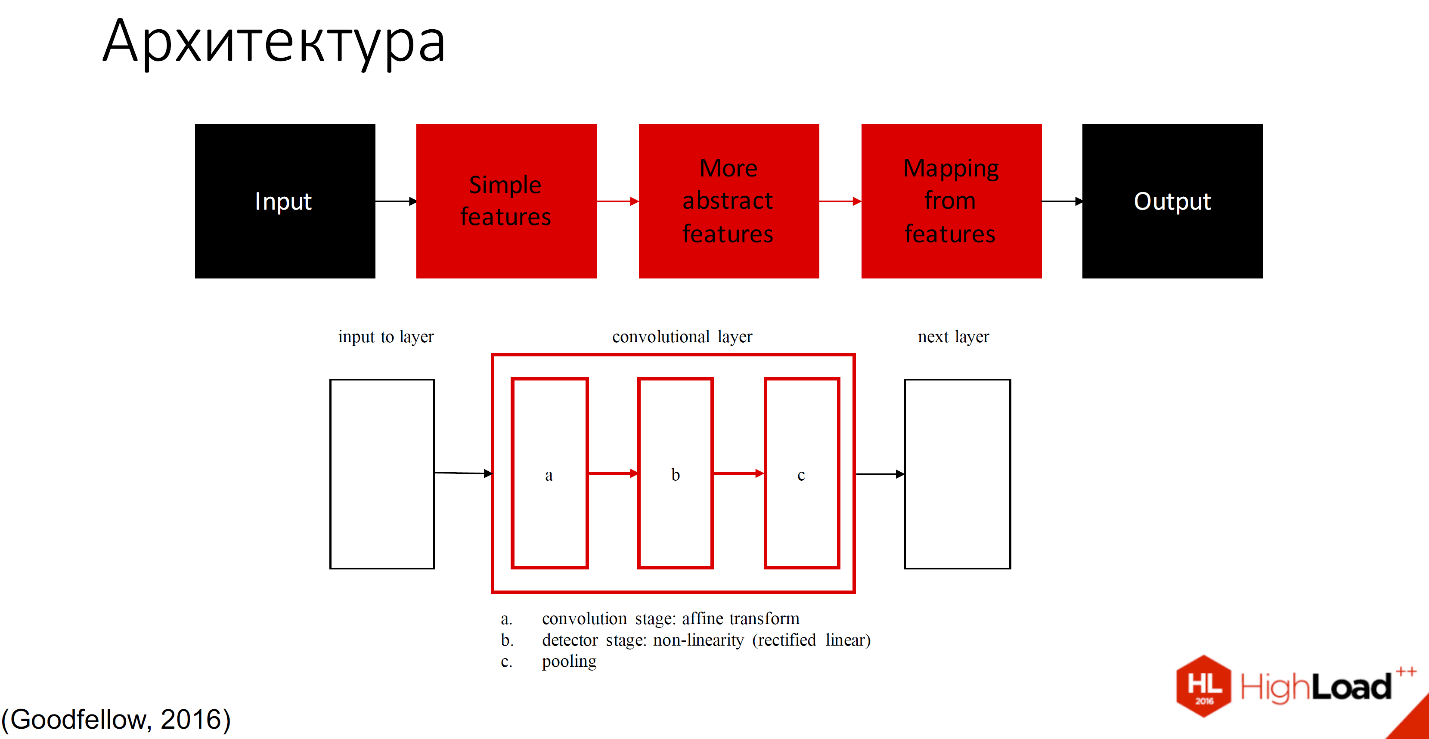
El negro indica aquellas partes que no aprenden, todas las demás capas pueden aprender. Hay muchas definiciones de lo que hay dentro de cada capa convolucional. Una de las designaciones aceptadas es que una capa con tres componentes se divide en etapa de convolución, etapa de detector y etapa de agrupación.
No entraré en detalles, habrá muchos más informes que detallarán cómo funciona esto. Te lo cuento con un ejemplo.
Como los organizadores me pidieron que no mencionara muchas fórmulas, las descarté por completo.

Entonces, la imagen de entrada cae en una red de capas, que pueden llamarse filtros de diferentes tamaños y diferente complejidad de los elementos que reconocen. Estos filtros forman su propio índice o conjunto de características, que luego ingresan al clasificador. Por lo general, esto es SVM o MLP, un perceptrón multicapa, que es conveniente para cualquier persona.
A imagen y semejanza de una red neuronal biológica, se reconocen objetos de diversa complejidad. A medida que aumentaba el número de capas, todo esto perdía contacto con la corteza, ya que hay un número limitado de zonas en la red neuronal. 269 o muchas, muchas zonas de abstracción, por lo que solo se salva un aumento de complejidad, número de elementos y campos receptivos.

Si nos fijamos en el ejemplo del reconocimiento facial, entonces nuestro campo receptivo de la primera capa será pequeño, luego un poco más, más, y así sucesivamente hasta que finalmente podamos reconocer todo el rostro.

En términos de lo que tenemos dentro de los filtros, primero habrá palos inclinados más algo de color, luego partes de las caras y luego la cara completa será reconocida por cada celda de la capa.
Hay gente que asegura que una persona siempre reconoce mejor que una red. ¿Es tan?
En 2014, los científicos decidieron probar qué tan bien reconocemos en comparación con las redes neuronales. Tomaron las 2 mejores redes en este momento, estas son AlexNet y la red de Matthew Ziller y Fergus, y las compararon con la respuesta de diferentes áreas del cerebro del macaco, al que también se le enseñó a reconocer algunos objetos. Los objetos eran del reino animal para que el mono no se confundiera y se hacían experimentos para ver quién los reconocía mejor.
Como es claramente imposible obtener una respuesta de un mono, se le implantaron electrodos y se midió directamente la respuesta de cada neurona.
Resultó que, en condiciones normales, las células cerebrales respondieron tan bien como el modelo de última generación en ese momento, es decir, la red de Matthew Ziller.
Sin embargo, con un aumento en la velocidad de visualización de objetos, un aumento en la cantidad de ruidos y objetos en la imagen, la velocidad de reconocimiento y su calidad en nuestro cerebro y el cerebro de los primates se reducen drásticamente. Incluso la red neuronal convolucional más simple reconoce mejor los objetos. Es decir, oficialmente, las redes neuronales funcionan mejor que nuestro cerebro.
Problemas clásicos de redes neuronales convolucionales
En realidad no hay tantos, pertenecen a tres clases. Entre ellos se encuentran tareas tales como identificación de objetos, segmentación semántica, reconocimiento de rostros, reconocimiento de partes del cuerpo humano, definición semántica de límites, selección de objetos de atención en la imagen y selección de normales a la superficie. Se pueden dividir condicionalmente en 3 niveles: desde las tareas de nivel más bajo hasta las tareas de nivel más alto.
Usando esta imagen como ejemplo, veamos qué hace cada una de las tareas.
- Definición de límites- esta es la tarea de nivel más bajo para la que ya se utilizan clásicamente las redes neuronales convolucionales.
- Definición de un vector a una normal nos permite reconstruir una imagen 3D a partir de una 2D.
- Prominencia, definición de objetos de atención.- esto es a lo que una persona prestaría atención al considerar esta imagen.
- Segmentación semántica le permite dividir los objetos en clases según su estructura, sin saber nada acerca de estos objetos, es decir, incluso antes de que sean reconocidos.
- Resaltado de límites semánticos- esta es la selección de límites, divididos en clases.
- Aislamiento de partes del cuerpo humano..
- Y la tarea de más alto nivel - reconocimiento de los propios objetos, que ahora consideraremos usando el ejemplo del reconocimiento facial.
Reconocimiento facial
Lo primero que hacemos es ejecutar el detector de rostros sobre la imagen para encontrar el rostro. Luego, normalizamos, centramos el rostro y lo procesamos en la red neuronal. Después de eso, obtenemos un conjunto o vector de características que describe de manera única las características de esta cara.
Luego podemos comparar este vector de características con todos los vectores de características que están almacenados en nuestra base de datos y obtener una referencia a una persona específica, a su nombre, a su perfil, todo lo que podemos almacenar en la base de datos.
Así es como funciona nuestro producto FindFace: es servicio gratuito, que ayuda a buscar perfiles de personas en la base de datos de VKontakte.
Además, disponemos de una API para empresas que quieran probar nuestros productos. Brindamos servicios de detección de rostros, verificación e identificación de usuarios.
Ahora hemos desarrollado 2 escenarios. El primero es la identificación, la búsqueda de una persona en una base de datos. La segunda es la verificación, esta es una comparación de dos imágenes con cierta probabilidad de que se trate de la misma persona. Además, actualmente estamos desarrollando el reconocimiento de emociones, el reconocimiento de imágenes de video y la detección de vida: se trata de comprender si una persona está viva frente a la cámara o frente a una fotografía.
Algunas estadísticas. Al identificar, al buscar 10 mil fotos, tenemos una precisión de alrededor del 95% dependiendo de la calidad de la base de datos, 99% de precisión de verificación. Y además de esto, este algoritmo es muy resistente a los cambios: no tenemos que mirar a la cámara, podemos tener algunos objetos que bloquean: anteojos, gafas de sol, una barba, una máscara médica. En algunos casos, incluso podemos superar dificultades tan increíbles para la visión artificial como unas gafas y una máscara.
Búsqueda muy rápida, tarda 0,5 segundos en procesar mil millones de fotos. Hemos desarrollado un índice único búsqueda rápida. También podemos trabajar con imágenes de baja calidad de cámaras de CCTV. Podemos procesarlo todo en tiempo real. Puede cargar fotos a través de la interfaz web, a través de Android, iOS y buscar entre 100 millones de usuarios y sus 250 millones de fotos.
Como dije, obtuvimos el primer lugar en la competencia MegaFace, un análogo de ImageNet, pero para reconocimiento facial. Lleva funcionando varios años, el año pasado fuimos los mejores entre 100 equipos de todo el mundo, incluido Google.
Redes neuronales recurrentes
Usamos redes neuronales recurrentes cuando no nos basta con reconocer solo la imagen. En los casos en que es importante para nosotros seguir la secuencia, necesitamos el orden de lo que está sucediendo con nosotros, usamos redes neuronales recurrentes ordinarias.Se aplica al reconocimiento de lenguaje natural, procesamiento de video, incluso reconocimiento de imágenes.
No hablaré sobre el reconocimiento del lenguaje natural; después de mi informe, habrá dos más que estarán destinados al reconocimiento del lenguaje natural. Por lo tanto, hablaré sobre el trabajo de las redes recurrentes usando el ejemplo del reconocimiento de emociones.
¿Qué son las redes neuronales recurrentes? Esto es casi lo mismo que las redes neuronales regulares, pero con retroalimentación. Necesitamos retroalimentación para transmitir el estado previo del sistema a la entrada de la red neuronal oa una de sus capas.
Supongamos que procesamos emociones. Incluso en una sonrisa, una de las emociones más simples, hay varios momentos, desde una expresión facial neutra hasta el momento en que tenemos una sonrisa completa. Se suceden en secuencia. Para entender esto bien, necesitamos poder observar cómo sucede esto, para transferir lo que había en el cuadro anterior al siguiente paso del sistema.

En 2005, en la competencia Emotion Recognition in the Wild específicamente para el reconocimiento de emociones, un equipo de Montreal presentó un sistema recurrente que parecía muy simple. Tenía solo unas pocas capas convolucionales y trabajaba exclusivamente con video. Este año, también agregaron reconocimiento de audio y datos agregados cuadro por cuadro que se obtienen de redes neuronales convolucionales, datos de señales de audio con una operación de red neuronal recurrente (con estado) y ganaron el primer lugar en la competencia.
Aprendizaje reforzado
El siguiente tipo de redes neuronales, que se usa con mucha frecuencia recientemente, pero que no ha recibido tanta publicidad como los 2 tipos anteriores, es el aprendizaje profundo, el aprendizaje por refuerzo.El caso es que en los dos casos anteriores usamos bases de datos. Tenemos datos de caras, o datos de imágenes, o datos con emociones de videos. Si no lo tenemos, si no lo podemos filmar, ¿cómo podemos enseñarle al robot a recoger objetos? Hacemos esto automáticamente, no sabemos cómo funciona. Otro ejemplo: compilar grandes bases de datos en juegos de computadora difícil, y no necesario, se puede hacer mucho más fácil.
Probablemente todo el mundo haya oído hablar del éxito del aprendizaje por refuerzo profundo en Atari y Go.
¿Quién ha oído hablar de Atari? Bueno, alguien escuchó, está bien. Creo que todo el mundo ha oído hablar de AlphaGo, así que ni siquiera les diré qué está pasando exactamente allí.

¿Qué está pasando en Atari? La arquitectura de esta red neuronal se muestra a la izquierda. Aprende jugando consigo misma para obtener la máxima recompensa. La recompensa máxima es el resultado más rápido del juego con la puntuación más alta posible.
Arriba a la derecha: la última capa de la red neuronal, que representa la cantidad total de estados del sistema, que jugó contra sí mismo durante solo dos horas. El rojo muestra los resultados deseados del juego con la recompensa máxima y el azul, indeseable. La red construye un determinado campo y se mueve a través de sus capas entrenadas hasta el estado que quiere alcanzar.
En robótica, la situación es un poco diferente. ¿Por qué? Aquí tenemos varias complicaciones. Primero, no tenemos muchas bases de datos. En segundo lugar, necesitamos coordinar tres sistemas a la vez: la percepción del robot, sus acciones con la ayuda de manipuladores y su memoria: qué se hizo en el paso anterior y cómo se hizo. En general, todo esto es muy difícil.
El hecho es que ni una sola red neuronal, incluso el aprendizaje profundo en este momento, puede hacer frente a esta tarea de manera suficientemente eficiente, por lo que el aprendizaje profundo es solo una parte de lo que los robots deben hacer. Por ejemplo, Sergey Levin proporcionó recientemente un sistema que le enseña a un robot a agarrar objetos.

Aquí están los experimentos que realizó en sus 14 brazos robóticos.
¿Que está pasando aqui? En estos cuencos que ves frente a ti, hay varios objetos: bolígrafos, gomas de borrar, tazas más pequeñas y más grandes, trapos, diferentes texturas, diferentes durezas. No está claro cómo entrenar al robot para capturarlos. Durante muchas horas, e incluso semanas, robots entrenados para poder capturar estos objetos, se compilaron bases de datos en esta ocasión.
Las bases de datos son una especie de respuesta del entorno que necesitamos acumular para poder entrenar al robot para que haga algo en el futuro. En el futuro, los robots serán entrenados en este conjunto de estados del sistema.
Aplicaciones no estándar de las redes neuronales
Desafortunadamente este es el final, no tengo mucho tiempo. Hablaré de aquellas soluciones no estándar que existen ahora y que, según muchas previsiones, tendrán alguna aplicación en el futuro.Entonces, los científicos de Stanford idearon recientemente una aplicación muy inusual de la red neuronal CNN para la predicción de la pobreza. ¿Que hicieron?
En realidad el concepto es muy simple. El hecho es que en África el nivel de pobreza supera todos los límites imaginables e imaginables. Ni siquiera tienen la capacidad de recopilar datos demográficos sociales. Por lo tanto, desde 2005, no tenemos ningún dato sobre lo que está sucediendo allí.
Los científicos recopilaron mapas diurnos y nocturnos de los satélites y los alimentaron a la red neuronal con el tiempo.
La red neuronal se preconfiguró en ImageNet”e. Es decir, se configuraron las primeras capas de filtros para que ya pudiera reconocer algunas cosas muy simples, por ejemplo, techos de casas, para buscar un asentamiento en mapas diurnos. Luego mapas diurnos se compararon con mapas nocturnos la iluminación de una misma zona de la superficie para poder decir cuánto dinero tiene la población para al menos iluminar sus casas durante la noche.

Aquí se ven los resultados de la predicción construida por la red neuronal. El pronóstico se hizo con diferentes resoluciones. Y verás, el último cuadro, datos reales recopilados por el gobierno de Uganda en 2005.
Se puede ver que la red neuronal hizo una predicción bastante precisa, incluso con un ligero cambio desde 2005.
Hubo, por supuesto, efectos secundarios. Los científicos que se dedican al aprendizaje profundo siempre se sorprenden al encontrar diferentes efectos secundarios. Por ejemplo, como aquellos que la red ha aprendido a reconocer agua, bosques, grandes obras de construcción, carreteras, todo esto sin maestros, sin bases de datos preconstruidas. Generalmente completamente independiente. Había ciertas capas que reaccionaban, por ejemplo, a las carreteras.
Y la última aplicación de la que me gustaría hablar es la segmentación semántica de imágenes 3D en medicina. En general, las imágenes médicas son un área compleja con la que es muy difícil trabajar.
Hay varias razones para esto.
- Tenemos muy pocas bases de datos. No es tan fácil encontrar una foto del cerebro, además de dañado, y además es imposible sacarla de cualquier parte.
- Incluso si tenemos una imagen de este tipo, necesitamos llevar a un médico y obligarlo a colocar manualmente todas las imágenes de varias capas, lo que consume mucho tiempo y es extremadamente ineficiente. No todos los médicos tienen los recursos para hacer esto.
- Se requiere una precisión muy alta. El sistema médico no puede estar equivocado. Al reconocer, por ejemplo, focas, no reconocieron, está bien. Y si no reconocemos el tumor, entonces esto no es muy bueno. Hay requisitos especialmente estrictos para la confiabilidad del sistema.
- Imágenes en elementos tridimensionales: vóxeles, no píxeles, lo que aporta una complejidad adicional a los diseñadores de sistemas.
Dónde se usa: para determinar el daño después de un golpe, para buscar un tumor en el cerebro, en cardiología para determinar cómo funciona el corazón.

Aquí hay un ejemplo para determinar el volumen de la placenta.
Automáticamente, funciona bien, pero no lo suficiente como para lanzarlo a producción, por lo que apenas está comenzando. Hay varias nuevas empresas para construir tales sistemas de visión médica. En general, hay muchas nuevas empresas en aprendizaje profundo en el futuro cercano. Dicen que los capitalistas de riesgo han asignado más presupuesto para nuevas empresas de aprendizaje profundo en los últimos seis meses que en los últimos 5 años.
Esta área se está desarrollando activamente, hay muchas direcciones interesantes. Estamos viviendo tiempos interesantes. Si está involucrado en el aprendizaje profundo, entonces probablemente sea hora de que abra su propia startup.
Bueno, probablemente terminaré con esto. Muchas gracias.
Arroz. 13.12. Arroz. 13.13. Arroz. 13.14. Arroz. 13.15. Arroz. 13.16. Arroz. 13.17. Arroz. 13.18. Arroz. 13.19. Arroz. 13.20. Arroz. 13.21. Arroz. 13.22. Arroz. 13.23. Arroz. 13.24. Arroz. 13.25. Arroz. 13.26. Arroz. 13.28. Esquema tecnológico general del tratamiento de datos
La práctica diaria de los mercados financieros contrasta de manera interesante con la visión académica de que los cambios en los precios de los activos financieros ocurren instantáneamente, sin ningún esfuerzo, reflejando efectivamente toda la información disponible. La existencia de cientos de creadores de mercado, comerciantes y administradores de fondos cuyo trabajo es obtener ganancias sugiere que los participantes del mercado hacen alguna contribución a información general. Además, dado que este trabajo es costoso, la cantidad de información aportada debe ser importante.
La existencia de cientos de creadores de mercado, comerciantes y administradores de fondos en los mercados financieros sugiere que todos procesan información financiera y toman decisiones.
Es más difícil responder a la pregunta de cómo se genera y utiliza específicamente en los mercados financieros la información que puede generar ganancias. La investigación casi siempre muestra que ninguna estrategia comercial sostenible produce ganancias constantes, y al menos ese es el caso cuando se tiene en cuenta el costo de la negociación. También es bien sabido que los participantes del mercado (y el mercado en su conjunto) pueden tomar decisiones muy diferentes basándose en información similar o incluso sin cambios.
Aparentemente, los participantes del mercado en su trabajo no se limitan a reglas de toma de decisiones consistentes y lineales, sino que tienen varios escenarios de acción en stock, y cuál se pone en acción depende a veces de señales externas imperceptibles. Un posible enfoque para la serie de información multidimensional y, a menudo, no lineal del mercado financiero es imitar los patrones de comportamiento de los participantes del mercado siempre que sea posible, utilizando métodos de inteligencia artificial como sistemas expertos o redes neuronales.
Se ha invertido mucho esfuerzo en modelar los procesos de toma de decisiones con estos métodos. Sin embargo, resultó que los sistemas expertos funcionan bien en situaciones complejas solo cuando el sistema es intrínsecamente estacionario (es decir, cuando hay una sola respuesta que no cambia con el tiempo para cada vector de entrada). Tal descripción se ajusta hasta cierto punto a las tareas de clasificación compleja o asignación de préstamos, pero parece completamente poco convincente para los mercados financieros con sus continuos cambios estructurales. En el caso de los mercados financieros, difícilmente se puede argumentar que es posible lograr un conocimiento completo o al menos hasta cierto punto adecuado sobre un área temática determinada, mientras que para los sistemas expertos con algoritmos basados en reglas, este es un requisito común.
Las redes neuronales ofrecen oportunidades prometedoras completamente nuevas para los bancos y otras instituciones financieras que, por la naturaleza de sus actividades, tienen que resolver problemas en condiciones de poco conocimiento a priori sobre el entorno. La naturaleza de los mercados financieros ha cambiado drásticamente desde que la desregulación, la privatización y el surgimiento de nuevos instrumentos financieros han fusionado los mercados nacionales con los mercados globales, y la libertad ha aumentado en la mayoría de los sectores del mercado. Transacciones financieras. Claramente, los cimientos mismos de la gestión de riesgos y rendimientos no podían sino cambiar a medida que las oportunidades de diversificación y las estrategias de protección de riesgos cambiaban más allá del reconocimiento.
Una de las áreas de aplicación de las redes neuronales para varios bancos líderes fue el problema de los cambios en la posición del dólar estadounidense en el mercado de divisas con una gran cantidad de indicadores objetivos sin cambios. La posibilidad de tales aplicaciones se ve facilitada por el hecho de que existen enormes bases de datos de datos económicos, porque los modelos complejos siempre son voraces en términos de información.
Las cotizaciones de bonos y el arbitraje es otra área en la que los problemas de aumento y reducción del riesgo, los diferenciales de tasas de interés y la liquidez, la profundidad y la liquidez del mercado son material favorable para métodos computacionales poderosos.
Otro tema que ha ido cobrando importancia en los últimos años es la modelización del flujo de fondos entre inversores institucionales. La caída de las tasas de interés ha jugado un papel decisivo en el aumento del atractivo de los fondos mutuos y los fondos indexados, y la disponibilidad de opciones y futuros sobre sus acciones le permite comprarlas con garantía total o parcial.
Es obvio que el problema de optimización en condiciones en las que el número de restricciones de equilibrio parcial es infinito (por ejemplo, en los mercados de futuros y al contado de cualquier producto en cualquier sector del mercado, las diferencias cruzadas en las tasas de interés juegan un papel), se convierte en un problema. problema de extrema complejidad, cada vez más allá de las capacidades de cualquier comerciante.
En tales circunstancias, los comerciantes y, por lo tanto, cualquier sistema que busque describir su comportamiento, deberá centrarse en reducir la dimensión del problema en un momento dado. El fenómeno de los valores de alta demanda es bien conocido.
Cuando se trata del sector financiero, es seguro decir que los primeros resultados obtenidos con el uso de redes neuronales son muy alentadores, y es necesario desarrollar investigaciones en esta área. Como ya sucedió con los sistemas expertos, pueden pasar varios años antes de que las instituciones financieras tengan suficiente confianza en las capacidades de las redes neuronales y comiencen a utilizarlas en todo su potencial.
La naturaleza de los desarrollos en el campo de las redes neuronales es fundamentalmente diferente de los sistemas expertos: estos últimos se basan en afirmaciones como "si... entonces...", que se desarrollan como resultado de un largo proceso de aprendizaje del sistema, y el progreso se logra principalmente a través de un mejor uso de las estructuras lógicas formales. Las redes neuronales se basan en un enfoque predominantemente conductual del problema que se resuelve: la red "aprende de los ejemplos" y ajusta sus parámetros utilizando los llamados algoritmos de aprendizaje a través de un mecanismo de retroalimentación.
DIFERENTES TIPOS DE NEURONAS ARTIFICIALES
Una neurona artificial (Fig. 13.1) es un elemento simple que primero calcula la suma ponderada V de los valores de entrada con la fórmula "src="http://hi-edu.ru/e-books/xbook725/ archivos/13.1.gif" align="absmiddle" alt="(!LANG:(13.1)
Aquí N es la dimensión del espacio de las señales de entrada.
Luego, la cantidad resultante se compara con la fórmula del umbral (o sesgo)" src="http://hi-edu.ru/e-books/xbook725/files/18.gif" border="0" align="absmiddle" alt= "(!IDIOMA:en la suma ponderada (1) suelen denominarse coeficientes o pesos sinápticos. La suma ponderada V se llamará potencial de la neurona i. La señal de salida tiene entonces la forma f(V).
El valor de la barrera de umbral se puede considerar como otro factor de ponderación para una señal de entrada constante. En este caso, estamos hablando de espacio de entrada ampliado: neurona con entrada N -dimensional tiene peso N+1..2.gif" border="0" align="absmiddle" alt="(!LANG:(13.2)
Según el método de transformación de la señal y la naturaleza de la función de activación, surgen varios tipos de estructuras neurales. solo consideraremos neuronas deterministas(Opuesto a neuronas probabilísticas, cuyo estado en el tiempo t es una función aleatoria del potencial y estado en el tiempo t-1). A continuación, distinguiremos neuronas estáticas- aquellos en los que la señal se transmite sin demora, - y dinámica, donde se tiene en cuenta la posibilidad de tales demoras ( "sinapsis retardadas").
DIFERENTES TIPOS DE FUNCIÓN DE ACTIVACIÓN
Las funciones de activación f pueden ser de varios tipos:
Fórmula" src="http://hi-edu.ru/e-books/xbook725/files/20.gif" border="0" align="absmiddle" alt="(!LANG:, la pendiente b se puede tener en cuenta en términos de los valores de los pesos y umbrales, y sin pérdida de generalidad se puede suponer que es igual a la unidad.
También es posible definir neuronas sin saturación, que toman un conjunto continuo de valores de salida. En los problemas de clasificación, el valor de salida puede determinarse mediante un umbral, al tomar una sola decisión, o ser probabilístico, al determinar la pertenencia a una clase. Para tener en cuenta las especificaciones de un problema en particular, se pueden elegir otros tipos de funciones de activación: gaussiana, sinusoidal, ondículas, etc.
REDES NEURONALES CON ACOPLAMIENTO DIRECTO
Consideraremos dos tipos de redes neuronales: estáticas, que a menudo también se denominan redes feed-forward, y redes dinámicas o recurrentes. En esta sección, nos ocuparemos de las redes estáticas. Otros tipos de redes se discutirán brevemente más adelante.
Las redes neuronales feed-forward consisten en neuronas estáticas, de modo que la señal a la salida de la red aparece en el mismo momento en que se dan las señales de entrada. La organización (topología) de la red puede ser diferente. Si no se emiten todas las neuronas que la componen, se dice que la red contiene neuronas ocultas. El tipo más general de arquitectura de red se obtiene cuando todas las neuronas están conectadas entre sí (pero sin realimentación). EN Tareas específicas Las neuronas suelen estar agrupadas en capas. En la fig. La figura 13.2 muestra una red neuronal feed-forward típica con una capa oculta.
Es interesante notar que, según los resultados teóricos, las redes neuronales con feed-forward y con funciones sigmoideas son una herramienta universal para aproximar (aproximar) funciones. Más precisamente, cualquier función de valor real de varias variables en un dominio compacto de definición se puede aproximar de forma arbitraria y exacta utilizando una red de tres capas. Al mismo tiempo, sin embargo, no sabemos ni el tamaño de la red que se requiere para esto, ni los valores de los pesos. Además, se puede ver a partir de la prueba de estos resultados que el número de elementos ocultos aumenta indefinidamente a medida que aumenta la precisión de la aproximación. De hecho, las redes feed-forward pueden servir como una herramienta de aproximación general, pero no existe una regla para encontrar la topología de red óptima para un problema dado.
Por lo tanto, la tarea de construir una red neuronal no es trivial. Las preguntas sobre cuántas capas ocultas se deben tomar, cuántos elementos en cada una de ellas, cuántas conexiones y qué parámetros de entrenamiento, en la literatura disponible, por regla general, se tratan a la ligera.
En la etapa de entrenamiento, los coeficientes sinápticos se calculan en el proceso de resolución de problemas por parte de la red neuronal (clasificación, predicción de series temporales, etc.), en los que la respuesta deseada no se determina por las reglas, sino por el uso de ejemplos agrupados en conjuntos de entrenamiento. Dicho conjunto consta de una serie de ejemplos con el valor del parámetro de salida indicado para cada uno de ellos, que sería deseable obtener. Las acciones que tienen lugar pueden llamarse aprendizaje supervisado: el "maestro" alimenta un vector de datos iniciales a la entrada de la red e informa el valor deseado del resultado del cálculo al nodo de salida. El aprendizaje supervisado de una red neuronal puede considerarse como una solución a un problema de optimización. Su objetivo es minimizar la función de error, o residual, E en conjunto dado ejemplos eligiendo los valores de los pesos W.
CRITERIOS DE ERROR
El objetivo del procedimiento de minimización es encontrar un mínimo global; lograrlo se denomina convergencia del proceso de aprendizaje. Dado que el residual depende de los pesos de forma no lineal, es imposible obtener una solución en forma analítica, y la búsqueda del mínimo global se lleva a cabo a través de un proceso iterativo, el llamado algoritmo de aprendizaje, que explora la superficie residual y busca encontrar un punto mínimo global sobre ella. Por lo general, el error cuadrático medio (MSE) se toma como una medida de error, que se define como la suma de las diferencias al cuadrado entre el valor de salida deseado border="0" align="absmiddle" alt="(!LANG:para cada ejemplo.
ejemplo"> criterio de máxima verosimilitud:
ejemplo">"épocas"). El cambio en los pesos ocurre en la dirección opuesta a la dirección de mayor pendiente para la función de costo:
es un parámetro definido por el usuario llamado tamaño de paso de gradiente o factor de aprendizaje.
Otro método posible se llama gradiente estocástico.
En él, los pesos se vuelven a calcular después de cada cálculo de todos los ejemplos de un conjunto de entrenamiento y, al mismo tiempo, se usa una función de costo parcial que corresponde a esto, por ejemplo, k-ésimo conjunto:
subtítulo">
PROPAGACIÓN HACIA ATRÁS
Considere ahora el algoritmo de entrenamiento de red neuronal feedforward más común: algoritmo de retropropagación(Backpropagation, BP), que es un desarrollo del llamado regla delta generalizada. Este algoritmo fue redescubierto y popularizado en 1986 por Rumelhart y McClelland de grupo famoso en el estudio de procesos paralelos distribuidos en el Instituto Tecnológico de Massachusetts. En este párrafo, consideraremos la esencia matemática del algoritmo con más detalle. Es un algoritmo de descenso de gradiente que minimiza el error cuadrático total:
fórmula" src="http://hi-edu.ru/e-books/xbook725/files/24.gif" border="0" align="absmiddle" alt="(!LANG:. El cálculo de las derivadas parciales se realiza según la regla de la cadena: el peso de la entrada de la j-ésima neurona procedente de la j-ésima neurona se recalcula según la fórmula
fórmula" src="http://hi-edu.ru/e-books/xbook725/files/23.gif" border="0" align="absmiddle" alt="(!LANG:- longitud de paso en la dirección opuesta a la pendiente.
Si consideramos por separado la k-ésima muestra, entonces el cambio correspondiente en los pesos es igual a
se calcula en términos de factores similares de la siguiente capa y, por lo tanto, el error se transmite en la dirección opuesta.
Para los elementos de salida, obtenemos:
fórmula" src="http://hi-edu.ru/e-books/xbook725/files/25.gif" border="0" align="absmiddle" alt="(!LANG:se define así:
fórmula" src="http://hi-edu.ru/e-books/xbook725/files/13.14.gif" border="0" align="absmiddle" alt="(!LANG:(13.14)
obtenemos:
ejemplo">versión estocástica, los pesos se recalculan cada vez después del cálculo de la siguiente muestra, y en la versión "epochal" o fuera de línea, los pesos cambian después del cálculo de todo el conjunto de entrenamiento.
Otro truco que se usa con frecuencia es que al determinar la dirección de la búsqueda, se agrega una corrección al gradiente actual: el vector de desplazamiento del paso anterior, tomado con un cierto coeficiente. Podemos decir que se tiene en cuenta el impulso de movimiento ya existente. La fórmula final para cambiar los pesos se ve así:
fórmula" src="http://hi-edu.ru/e-books/xbook725/files/26.gif" border="0" align="absmiddle" alt="(!LANG:- número en el intervalo (0,1), que establece el usuario.
A menudo, el significado del subtítulo ">
OTROS ALGORITMOS DE APRENDIZAJE
Finalmente, los llamados algoritmos genéticos, en el que se considera un conjunto de pesos como un individuo sujeto a mutaciones y cruces, y se toma un criterio de error como indicador de su "calidad". A medida que nacen nuevas generaciones, la aparición de un individuo óptimo se vuelve cada vez más probable.
En aplicaciones financieras, los datos son especialmente ruidosos. Por ejemplo, las transacciones pueden registrarse en la base de datos con un retraso y, en diferentes casos, con diferentes. Los valores faltantes o la información incompleta a veces también se consideran ruido: en tales casos, se toma el valor promedio o el mejor, y esto, por supuesto, conduce a una base de datos ruidosa. La definición incorrecta de la clase de objeto en los problemas de reconocimiento afecta negativamente el aprendizaje; esto empeora la capacidad del sistema para generalizar cuando se trabaja con objetos nuevos (es decir, no incluidos en el número de muestras).
CONFIRMACIÓN CRUZADA
Para eliminar la arbitrariedad en la partición de la base de datos, se pueden aplicar técnicas de reintento. Considere uno de estos métodos, que se llama validación cruzada. Su idea es dividir aleatoriamente la base de datos en q subconjuntos disjuntos por pares. Luego, el entrenamiento q se realiza en el conjunto (q -1), y el error se calcula en el conjunto restante. Si q es lo suficientemente grande, como 10, cada entrenamiento utiliza la mayor parte de los datos de entrada. Si el procedimiento de aprendizaje es confiable, entonces los resultados para q varios modelos deben estar muy cerca uno del otro. Después de eso, la característica final se determina como el promedio de todos los valores de error obtenidos. Desafortunadamente, al aplicar este método, la cantidad de cálculos muchas veces resulta ser muy grande, ya que se requieren q capacitaciones, y en una aplicación real de mayor dimensión, esto puede no ser factible. En el caso límite, cuando q = P, donde P es el número total de ejemplos, el método se denomina validación cruzada con un resto. Este método de estimación tiene un sesgo, y se ha desarrollado un método "cuchillo plegable", lo que reduce esta desventaja a costa de aún más cómputo.
La siguiente clase de redes neuronales que consideraremos son las redes dinámicas o recurrentes. Se construyen a partir de neuronas dinámicas cuyo comportamiento se describe mediante ecuaciones diferenciales o en diferencias, normalmente de primer orden. La red está organizada de tal manera que cada neurona recibe información de entrada de otras neuronas (posiblemente de sí misma) y del entorno. Este tipo de red es importante porque puede usarse para modelar sistemas dinámicos no lineales. Esto es muy modelo general, que potencialmente se puede utilizar en la mayoría diferentes aplicaciones ej.: memoria asociativa, procesamiento de señales no lineales, modelado de máquinas de estados finitos, identificación de sistemas, problemas de control.
Redes neuronales con retardo de tiempo
Antes de describir las redes dinámicas propiamente dichas, consideremos cómo se usa una red de avance para procesar series de tiempo. El método consiste en dividir la serie temporal en varios segmentos y así obtener una muestra estadística para alimentar a la entrada una red multicapa feed-forward. Esto se hace usando la llamada línea de retardo ramificada (ver Fig. 13.3).
La arquitectura de una red neuronal de este tipo con un retraso de tiempo le permite modelar cualquier dependencia de tiempo finito de la forma:
subtítulo">
REDES DE HOPFIELD
Con la ayuda de las redes recurrentes de Hopfield, puede procesar muestras desordenadas (letras escritas a mano), ordenadas en el tiempo (series temporales) o espaciales (gráficos, gramáticas) (Fig. 13.4). Hopfield introdujo una red neuronal recurrente del tipo más simple; está construido a partir de N neuronas, cada una conectada a cada una, y todas las neuronas son de salida.
Las redes de este diseño se utilizan principalmente como memoria asociativa, así como en problemas de filtrado no lineal de datos e inferencia gramatical. Además, recientemente se han aplicado para predecir y reconocer patrones en el comportamiento de los precios de las acciones.
El “mapa de características de autoorganización” introducido por Kohonen puede considerarse como una variante de una red neuronal. Este tipo de red está diseñada para autoeducación: no es necesario decirle las respuestas correctas durante el entrenamiento. Durante el proceso de aprendizaje, se alimentan varias muestras a la entrada de la red. La red captura las características de su estructura y divide las muestras en 436 conglomerados, y la red ya obtenida asigna cada ejemplo recién llegado a uno de los conglomerados, guiado por algún criterio de "proximidad".
La red consta de una capa de entrada y una de salida. La cantidad de elementos en la capa de salida determina directamente cuántos clústeres puede reconocer la red. Cada uno de los elementos de salida recibe todo el vector de entrada como entrada. Como en cualquier red neuronal, a cada conexión se le asigna un cierto peso sinóptico. En la mayoría de los casos, cada elemento de salida también está conectado a sus vecinos. Estas conexiones internas juegan un papel importante en el proceso de aprendizaje, ya que los pesos se ajustan solo en la vecindad del elemento que la mejor manera responde a otra entrada.
Los elementos de salida compiten entre sí por el derecho a entrar en acción y "aprender la lección". El ganador es aquel cuyo vector de peso es el más cercano al vector de entrada en términos de distancia, determinada, por ejemplo, por la métrica euclidiana. El elemento ganador tendrá esta distancia menor que todos los demás. En el paso de entrenamiento actual, solo el elemento ganador (y, quizás, sus vecinos inmediatos) puede cambiar de peso; los pesos de los elementos restantes están, por así decirlo, congelados. El elemento ganador reemplaza su vector de peso moviéndolo ligeramente hacia el vector de entrada. Después de entrenar en una cantidad suficiente de ejemplos, el conjunto de vectores de peso coincide con mayor precisión con la estructura de los ejemplos de entrada: los vectores de peso literalmente modelan la distribución de las muestras de entrada.

Arroz. 13.5. Red Kohonen autoorganizada. Sólo conexiones que van a i-ésimo nodo. La vecindad del nodo se muestra con la línea de puntos
Obviamente, para que la red comprenda correctamente la distribución de entrada, es necesario que cada elemento de la red sea el ganador la misma cantidad de veces; los vectores de peso deben ser equiprobable.
Hay dos cosas que deben hacerse antes de que se pueda iniciar la red de Kohonen:
los vectores de magnitud deben distribuirse aleatoriamente sobre la esfera unitaria;
todos los vectores de peso y de entrada deben normalizarse a uno.
Red de retropropagación(CPN, Counterpropagation Network) combina las propiedades de la red autoorganizada de Kohonen y el concepto de Oustar - red de Grossberg. Dentro de esta arquitectura, los elementos de la capa de red de Kohonen no tienen acceso directo a mundo externo, pero sirven como entradas para la capa de salida, en la que los pesos de Grossberg se asignan de forma adaptativa a los bonos. Este esquema se originó a partir del trabajo de Hecht-Nielsen. La red CPN tiene como objetivo la construcción gradual del mapeo deseado de entradas a salidas basado en ejemplos de la acción de dicho mapeo. La red es buena para resolver problemas en los que se requiere la capacidad de construir de forma adaptativa una reflexión matemática basada en sus valores exactos en puntos individuales.
Las redes de este tipo se han utilizado con éxito en aplicaciones financieras y económicas como la revisión de solicitudes de préstamos, la predicción de tendencias de precios de acciones, precios de productos básicos y tipos de cambio de divisas. En términos generales, se puede esperar un uso exitoso de las redes CPN en tareas en las que se requiere extraer conocimiento de grandes cantidades de datos.
APLICACIÓN PRÁCTICA DE REDES NEURONALES PARA PROBLEMAS DE CLASIFICACIÓN (CLUSTERIZACIÓN)
La solución del problema de clasificación es una de aplicaciones criticas Redes neuronales. El problema de clasificación es el problema de asignar una muestra a uno de varios conjuntos disjuntos por pares. Un ejemplo de tales tareas puede ser, por ejemplo, la tarea de determinar la solvencia de un cliente bancario, tareas médicas en las que es necesario determinar, por ejemplo, el resultado de una enfermedad, resolver problemas de gestión de una cartera de valores ( vender, comprar o "mantener" acciones según la situación del mercado), la tarea de identificar empresas viables y propensas a la quiebra.
PROPÓSITO DE LA CLASIFICACIÓN
A la hora de resolver problemas de clasificación, es necesario atribuir la disponibilidad muestras estáticas(características de la situación del mercado, datos de exámenes médicos, información sobre el cliente) para ciertas clases. Hay varias formas de representar los datos. La más común es la forma en que la muestra se representa mediante un vector. Los componentes de este vector representan varias características de la muestra que influyen en la decisión de a qué clase pertenece la muestra. Por ejemplo, para fines médicos, los componentes de este vector pueden ser datos de la historia clínica del paciente. Por lo tanto, en base a alguna información sobre el ejemplo, es necesario determinar a qué clase se puede asignar. El clasificador relaciona así el objeto con una de las clases de acuerdo con una cierta partición del espacio N-dimensional, que se llama espacio de entrada, y la dimensión de este espacio es el número de componentes del vector.
En primer lugar, debe determinar el nivel de complejidad del sistema. En problemas reales, a menudo surge una situación en la que el número de muestras es limitado, lo que dificulta determinar la complejidad del problema. Hay tres niveles principales de dificultad. El primero (el más simple) - cuando las clases se pueden separar por líneas rectas (o hiperplanos, si el espacio de entrada tiene una dimensión mayor que dos) - el llamado separabilidad lineal. En el segundo caso, las clases no se pueden separar por líneas (planos), pero se pueden separar usando una división más compleja: separabilidad no lineal. En el tercer caso, las clases se cruzan, y solo podemos hablar de separabilidad probabilística.

Arroz. 13.6. Clases separables linealmente y no linealmente
Idealmente, después del preprocesamiento deberíamos obtener un problema linealmente separable, ya que después de esto la construcción del clasificador se simplifica mucho. Desafortunadamente, al resolver problemas reales, tenemos un número limitado de muestras, sobre la base de las cuales se construye el clasificador. Al mismo tiempo, no podemos preprocesar los datos de tal manera que se logre la separabilidad lineal de las muestras.
USO DE REDES NEURONALES COMO CLASIFICADOR
Las redes feedforward son un medio universal de aproximación de funciones, lo que permite su uso para resolver problemas de clasificación. Por regla general, las redes neuronales son las más manera efectiva clasificación, porque en realidad generan una gran cantidad de modelos de regresión (que se utilizan para resolver problemas de clasificación por métodos estadísticos).
Desafortunadamente, en la aplicación de redes neuronales en problemas prácticos, surgen varios problemas. Primero, no se sabe de antemano qué complejidad (tamaño) puede requerir la red para una implementación suficientemente precisa del mapeo. Esta complejidad puede ser prohibitivamente alta y requiere arquitecturas de red complejas. Entonces, Minsky en su trabajo "Perceptrones" demostró que las redes neuronales de una sola capa más simples son capaces de resolver solo problemas linealmente separables. Esta limitación se puede superar cuando se utilizan redes neuronales multicapa. EN vista general podemos decir que en una red con una capa oculta, el vector correspondiente a la muestra de entrada es transformado por la capa oculta en un nuevo espacio, que puede tener una dimensión diferente, y luego los hiperplanos correspondientes a las neuronas de la capa de salida se dividen en clases. Así, la red reconoce no solo las características de los datos originales, sino también las "características de las características" formadas por la capa oculta.
PREPARACIÓN DE DATOS INICIALES
Para construir un clasificador, es necesario determinar qué parámetros influyen en la decisión sobre a qué clase pertenece la muestra. Al hacerlo, pueden surgir dos problemas. Primero, si el número de parámetros es pequeño, entonces puede surgir una situación en la que el mismo conjunto de datos iniciales corresponda a ejemplos ubicados en diferentes clases. Entonces es imposible entrenar la red neuronal y el sistema no funcionará correctamente (es imposible encontrar un mínimo que corresponda a tal conjunto de datos iniciales). Los datos de origen deben ser coherentes. Para resolver este problema, es necesario aumentar la dimensión del espacio de características (el número de componentes del vector de entrada correspondiente a la muestra). Pero con un aumento en la dimensión del espacio de funciones, puede surgir una situación en la que la cantidad de ejemplos sea insuficiente para entrenar la red y, en lugar de generalizar, simplemente recordará los ejemplos del conjunto de entrenamiento y no podrá funcionar correctamente. Por lo tanto, al definir características, es necesario encontrar un compromiso con su número.
A continuación, debe determinar cómo representar los datos de entrada para la red neuronal, es decir, determinar el método de normalización. La normalización es necesaria porque las redes neuronales funcionan con datos representados por números en el rango de 0 a 1, y los datos originales pueden tener un rango arbitrario o incluso ser datos no numéricos. Hay varias maneras de hacer esto, que van desde simples transformación lineal en el rango requerido y terminando con el análisis multivariado de parámetros y la normalización no lineal dependiendo de la influencia de los parámetros entre sí.
CODIFICACIÓN DE SALIDA
El problema de clasificación en presencia de dos clases se puede resolver en una red con una neurona en la capa de salida, que puede tomar uno de los dos valores 0 o 1, según la clase a la que pertenezca la muestra. Cuando hay varias clases, hay un problema con la representación de estos datos para la salida de la red. Más de una manera sencilla representación de la salida en este caso es un vector cuyas componentes corresponden a varios numeros clases Donde i-ésimo componente el vector corresponde a la i-ésima clase. Todos los demás componentes se establecen en 0. Entonces, por ejemplo, la segunda clase corresponderá a 1 en la segunda salida de red y 0 en el resto. Al interpretar el resultado, generalmente se asume que el número de clase está determinado por el número de salida de la red en el que apareció el valor máximo. Por ejemplo, si en una red con tres salidas, tenemos un vector de valores de salida (0.2; 0.6; 0.4), y vemos que el segundo componente del vector tiene el valor máximo, entonces la clase a la que pertenece este ejemplo es 2 Con este método de codificación, a veces también se introduce el concepto de confianza de la red de que el ejemplo pertenece a esta clase. La forma más sencilla de determinar la confianza es determinar la diferencia entre el valor máximo de una salida y el valor de otra salida más cercana al máximo. Por ejemplo, para el ejemplo considerado anteriormente, la confianza de la red de que el ejemplo pertenece a la segunda clase se determinará como la diferencia entre el segundo y el tercer componente del vector y es igual a 0,6-0,4=0,2. En consecuencia, cuanto mayor sea la confianza, mayor será la probabilidad de que la red dé la respuesta correcta. Este método de codificación es el más simple, pero no siempre el mejor, para representar datos.
También se conocen otros métodos. Por ejemplo, el vector de salida es el número de clúster escrito en binario. Entonces, en presencia de 8 clases, necesitamos un vector de 3 elementos y, digamos, la 3ra clase corresponderá al vector 011. Pero al mismo tiempo, si obtenemos un valor incorrecto en una de las salidas, puede obtener una clasificación incorrecta (número de clúster incorrecto), por lo que tiene sentido aumentar la distancia entre dos clústeres utilizando la codificación de salida de Hamming, lo que aumentará la confiabilidad de la clasificación.
Otro enfoque es dividir la tarea con k clases en k*(k-l)/2 subtareas con dos clases (codificación 2 por 2) cada una. En este caso, la subtarea significa que la red determina la presencia de uno de los componentes del vector. Esos. el vector de entrada se divide en grupos de dos componentes cada uno de tal manera que incluyen todas las combinaciones posibles de los componentes del vector de salida. El número de estos grupos se puede definir como el número de muestras desordenadas de dos de los componentes originales.
352" borde="0">
Donde 1 en la salida indica la presencia de uno de los componentes. Luego, podemos ir al número de clase según el resultado del cálculo de la red de la siguiente manera: determinamos qué combinaciones recibieron un valor de salida único (más precisamente, cerca de uno) (es decir, qué subtareas se activaron para nosotros), y consideramos que el número de clase será aquel que ingresó la mayor cantidad de subtareas activadas (ver tabla).
Documento sin titulo
Esta codificación en muchos problemas da mejores resultados que forma clásica codificación.
CLASIFICACIÓN PROBABILÍSTICA
En el reconocimiento de patrones estadísticos, el clasificador óptimo refiere la muestra a la fórmula "src="http://hi-edu.ru/e-books/xbook725/files/1.gif" border="0" align="absmiddle" alt="(! idioma:
fórmula de atributo" src="http://hi-edu.ru/e-books/xbook725/files/4.gif" border="0" align="absmiddle" alt="(!LANG:se refiere al grupo con la probabilidad posterior más alta. Esta regla es óptima en el sentido de que minimiza el número promedio de errores de clasificación..gif" border="0" align="absmiddle" alt="(!LANG:
entonces la relación bayesiana entre las probabilidades anterior y posterior sigue siendo válida, por lo que estas funciones se pueden utilizar como funciones de decisión simplificadas. Tiene sentido hacerlo si estas funciones se construyen y calculan de manera más simple.
Aunque la regla parece muy simple, resulta difícil aplicarla en la práctica, ya que muchas veces se desconocen las probabilidades posteriores (o incluso los valores de las funciones de decisión simplificadas). Su valor puede ser estimado. En virtud del teorema de Bayes, las probabilidades posteriores se pueden expresar en términos de probabilidades previas y funciones de densidad utilizando la fórmula " src="http://hi-edu.ru/e-books/xbook725/files/8.gif" " absmiddle" alt="(!LANG:.
CLASIFICADORES DE IMÁGENES
La densidad de probabilidad a priori se puede estimar diferentes caminos. EN métodos paramétricos se supone que la densidad de probabilidad (PDF) es una función de algún tipo con parámetros desconocidos. Por ejemplo, puede intentar aproximar un PDF utilizando una función gaussiana. Para clasificar, primero se deben obtener valores estimados para el vector medio y la matriz de covarianza para cada una de las clases de datos y luego utilizarlos en la regla de decisión. El resultado es una regla de decisión polinomial que contiene solo cuadrados y productos de variables por pares. Todo el proceso descrito se llama análisis cuadrático discriminante(QDA). Suponiendo que las matrices de covarianza para todas las clases son las mismas, QDA se reduce a análisis discriminante lineal(LDA).
En otros métodos de tipo - no paramétrico- no se requieren suposiciones previas sobre la densidad de probabilidad. En el método de k vecinos más cercanos (NN), se calcula la distancia entre la muestra recién llegada y los vectores del conjunto de entrenamiento, después de lo cual la muestra se asigna a la clase a la que pertenecen la mayoría de sus k vecinos más cercanos. Como resultado, los límites que separan las clases son lineales por partes. Varias modificaciones de este método utilizan diferentes medidas de distancia y técnicas especiales para encontrar vecinos. A veces, en lugar del propio conjunto de muestras, se toma un conjunto de centroides, correspondientes a grupos en el método de cuantificación vectorial adaptativa (LVQ).
En otros métodos, el clasificador divide los datos en grupos según un esquema de árbol. En cada paso, el subgrupo se divide en dos y el resultado es una estructura de árbol binario jerárquico. Los límites de separación se obtienen, por regla general, lineales por partes y corresponden a clases que consisten en una o más hojas del árbol. Este método es bueno porque genera un método de clasificación basado en reglas de decisión lógica. Las ideas de clasificadores en forma de árbol se utilizan en métodos para construir clasificadores neuronales de crecimiento propio.
RED NEURONAL CON ACOPLAMIENTO DIRECTO COMO CLASIFICADOR
Dado que las redes feed-forward son una herramienta universal para aproximar funciones, pueden usarse para estimar probabilidades posteriores en un problema de clasificación dado. Debido a la flexibilidad en la construcción del mapeo, es posible lograr tal precisión en la aproximación de probabilidades posteriores que prácticamente coincidirán con los valores calculados según la regla de Bayes (los llamados procedimientos de clasificación óptima).
PROBLEMA DE ANÁLISIS DE SERIE DE TIEMPO
Una serie temporal es una secuencia ordenada de fórmula de números reales" src="http://hi-edu.ru/e-books/xbook725/files/10.gif" border="0" align="absmiddle" alt=" (! idioma:en un espacio n-dimensional de valores desplazados en el tiempo, o espacio de retardo.
El propósito del análisis de series de tiempo es extraer información útil de una serie dada. Para ello, es necesario construir un modelo matemático del fenómeno. Dicho modelo debe explicar la esencia del proceso que genera los datos, en particular, describir la naturaleza de los datos (aleatorios, de tendencias, periódicos, estacionarios, etc.). Después de eso, se pueden aplicar varios métodos de filtrado de datos (suavizado, eliminación de valores atípicos, etc.) con el objetivo final de predecir valores futuros.
Así, este enfoque se basa en la suposición de que la serie temporal tiene alguna estructura matemática (que, por ejemplo, puede ser una consecuencia de la esencia física del fenómeno). Esta estructura existe en los llamados espacio de fase, cuyas coordenadas son variables independientes que describen el estado del sistema dinámico. Por tanto, la primera tarea a la que habrá que enfrentarse en el modelado es determinar el espacio de fase de forma adecuada. Para hacer esto, debe elegir algunas características del sistema como variables de fase. Después de eso, ya es posible plantear la cuestión de la predicción o la extrapolación. Por regla general, en las series temporales obtenidas como resultado de las mediciones, las fluctuaciones aleatorias y el ruido están presentes en diferentes proporciones. Por lo tanto, la calidad de un modelo está determinada en gran medida por su capacidad para aproximarse a la estructura de datos prevista, separándola del ruido.
ANÁLISIS ESTADÍSTICO DE SERIES TEMPORALES
Una descripción detallada de los métodos de análisis estadístico de series de tiempo está más allá del alcance de este libro. Consideraremos brevemente los enfoques tradicionales, destacando las circunstancias que están directamente relacionadas con el tema de nuestra presentación. Desde el trabajo pionero de Yule, los modelos ARIMA lineales han ocupado un lugar central en el análisis estadístico de series de tiempo. Con el tiempo, esta área tomó forma en una teoría completa con un conjunto de métodos: la teoría de Box-Jenkins.
La presencia de un término autorregresivo en un modelo ARIMA expresa el hecho de que los valores actuales de una variable dependen de sus valores pasados. Estos modelos se denominan unidimensionales. A menudo, sin embargo, los valores de la variable objetivo en estudio están asociados con varias series temporales diferentes.

Arroz. 13.7. Implementación del modelo ARIMA (p,q) sobre la red neuronal más simple
Este sería el caso, por ejemplo, si la variable objetivo es el tipo de cambio y las otras variables involucradas son las tasas de interés (en cada una de las dos monedas).
Los métodos correspondientes se denominan multivariados. La estructura matemática de los modelos lineales es bastante simple y sus cálculos se pueden realizar sin mucha dificultad utilizando paquetes estándar de métodos numéricos. El siguiente paso en el análisis de series temporales fue el desarrollo de modelos que puedan tener en cuenta las no linealidades que suelen estar presentes en procesos y sistemas reales. Uno de los primeros modelos de este tipo fue propuesto por Tong y se llama modelo autorregresivo de umbral (TAR).
En él, al alcanzar ciertos valores de umbral (preestablecidos), hay un cambio de un modelo AR lineal a otro. Así, el sistema tiene varios modos de funcionamiento.
Luego se proponen modelos STAR o TAR "suaves". Tal modelo es una combinación lineal de varios modelos tomados con coeficientes que son funciones continuas del tiempo.
MODELOS BASADOS EN REDES NEURONALES ACOPLADAS HACIA ADELANTE
Es curioso notar que todos los modelos descritos en el párrafo anterior pueden implementarse utilizando redes neuronales. Cualquier tipo de dependencia
selección">Fig. 13.8
Acciones en el primero etapa - etapa PAGS Preprocesamiento de datos- obviamente, depende en gran medida de los detalles de la tarea. Es necesario elegir correctamente la cantidad y el tipo de indicadores que caracterizan el proceso, incluida la estructura de los retrasos. Después de eso, debe seleccionar la topología de red. Si se utilizan redes feed-forward, se debe determinar el número de elementos ocultos. A continuación, para encontrar los parámetros del modelo, debe elegir un criterio de error y un algoritmo de optimización (entrenamiento). Luego, utilizando las herramientas de diagnóstico, debe verificar las diversas propiedades del modelo. Finalmente, necesita interpretar la salida de la red y, quizás, alimentarla a la entrada de algún otro sistema de soporte de decisiones. A continuación, consideraremos los problemas que deben abordarse en las etapas de preprocesamiento, optimización y análisis (depuración) de la red.
RECOPILACIÓN DE DATOS
La decisión más importante que debe tomar un analista es la elección de un conjunto de variables para describir el proceso que se está modelando. Para imaginar las posibles relaciones entre diferentes variables, debe tener una buena comprensión de la esencia del problema. En este sentido, será muy útil hablar con un especialista con experiencia en esta área temática. Con respecto a las variables que elija, debe comprender si son significativas en sí mismas o si simplemente reflejan otras variables realmente significativas. Las pruebas de significación incluyen análisis de correlación cruzada. Se puede utilizar, por ejemplo, para identificar una relación temporal como el retraso (lag) entre dos series. La medida en que un fenómeno puede ser descrito por un modelo lineal se prueba utilizando la regresión de mínimos cuadrados (OLS).
La discrepancia obtenida después del subtítulo de optimización">
LAS REDES NEURONALES COMO MEDIO DE EXTRACCIÓN DE DATOS
A veces hay una tarea de análisis de datos que difícilmente se puede representar en forma numérica matemática. Este es el caso cuando necesita extraer datos cuyos principios de selección no están claramente definidos: identificar socios confiables, identificar un producto prometedor, etc. Consideremos una situación típica para problemas de este tipo: la predicción de quiebras. Supongamos que tenemos información sobre las actividades de varias docenas de bancos (sus estados financieros públicos) durante un cierto período de tiempo. Al final de este período, sabemos cuáles de estos bancos quebraron, a cuáles se les revocó la licencia y cuáles continúan operando de manera constante (al final del período). Y ahora tenemos que decidir en cuál de los bancos vale la pena colocar fondos. Naturalmente, es poco probable que queramos colocar fondos en un banco que puede quebrar pronto. Esto significa que necesitamos resolver de alguna manera el problema de analizar los riesgos de invertir en varias estructuras comerciales.
A primera vista, no es difícil resolver este problema; después de todo, tenemos datos sobre el trabajo de los bancos y los resultados de sus actividades. Pero, de hecho, esta tarea no es tan simple. Hay un problema relacionado con el hecho de que los datos que tenemos describen el período pasado y nos interesa lo que sucederá en el futuro. Por lo tanto, en base a los datos a priori que tenemos, necesitamos obtener un pronóstico para el próximo período. Se pueden utilizar varios métodos para resolver este problema.
Así, la más obvia es la aplicación de métodos de estadística matemática. Pero aquí hay un problema con la cantidad de datos, porque los métodos estadísticos funcionan bien con una gran cantidad de datos a priori, y es posible que tengamos una cantidad limitada de ellos. Sin embargo, los métodos estadísticos no pueden garantizar un resultado exitoso.
Otra forma de resolver este problema puede ser el uso de redes neuronales que se pueden entrenar con el conjunto de datos existente. En este caso, los datos de los informes financieros de varios bancos se utilizan como información inicial y el resultado de sus actividades se utiliza como campo de destino. Pero cuando usamos los métodos descritos anteriormente, imponemos el resultado sin tratar de encontrar patrones en los datos originales. En principio, todos los bancos en quiebra son similares entre sí, aunque solo sea porque quebraron. Esto significa que debe haber algo más general en sus actividades que los condujo a este resultado, y podemos tratar de encontrar estos patrones para usarlos en el futuro. Y aquí nos enfrentamos a la cuestión de cómo encontrar estos patrones. Para hacer esto, si usamos métodos estadísticos, necesitamos determinar qué criterios de "similitud" usamos, lo que puede requerir que tengamos algún conocimiento adicional sobre la naturaleza del problema.
Sin embargo, existe un método que le permite automatizar todas estas acciones para encontrar patrones: el método de análisis que utiliza los mapas autoorganizados de Kohonen. Consideremos cómo se resuelven estos problemas y cómo los mapas de Kohonen encuentran patrones en los datos de origen. En aras de la generalidad, usaremos el término objeto (por ejemplo, un banco puede ser un objeto, como en el ejemplo discutido anteriormente, pero la técnica descrita es adecuada para resolver otros problemas sin cambios, por ejemplo, analizar la solvencia de un cliente , buscando una estrategia óptima de comportamiento en el mercado, etc.). Cada objeto se caracteriza por un conjunto de diferentes parámetros que describen su estado. Por ejemplo, para nuestro ejemplo, los parámetros serán datos de informes financieros. Estos parámetros a menudo tienen forma numérica o se pueden convertir a ella. Por lo tanto, con base en el análisis de los parámetros de los objetos, necesitamos seleccionar objetos similares y presentar el resultado en una forma que sea conveniente para la percepción.
Todas estas tareas se resuelven con los mapas autoorganizados de Kohonen. Echemos un vistazo más de cerca a cómo funcionan. Para simplificar la consideración, supondremos que los objetos tienen 3 características (de hecho, puede haber cualquier número de ellas).
Ahora imagine que todos estos tres parámetros de los objetos son sus coordenadas en el espacio tridimensional (en el mismo espacio que nos rodea en La vida cotidiana). Luego, cada objeto se puede representar como un punto en este espacio, lo que haremos (para que no tengamos problemas con las diferentes escalas a lo largo de los ejes, numeramos todas estas características en el intervalo por cualquier de manera adecuada), como resultado de lo cual todos los puntos caerán en un cubo de tamaño unitario en la Fig. 13.9. Vamos a mostrar estos puntos. Mirando esta figura, podemos ver cómo se ubican los objetos en el espacio, y es fácil notar las áreas donde se agrupan los objetos, es decir. tienen parámetros similares, lo que significa que lo más probable es que estos objetos pertenezcan al mismo grupo. Tenemos que encontrar una manera de convertir este sistema en un sistema fácil de percibir, preferiblemente bidimensional (porque una imagen tridimensional ya no se puede mostrar correctamente en un plano) para que los objetos vecinos en el espacio deseado estén cerca en la imagen resultante. Para ello, utilizamos el mapa de Kohonen autoorganizado. En una primera aproximación, se puede representar como una red hecha de caucho (Fig. 13.10.
Nosotros, previamente "arrugados", arrojamos esta red al espacio de características, donde ya tenemos objetos, y luego procedemos de la siguiente manera: tomamos un objeto (un punto en este espacio) y encontramos el nodo de red más cercano a él. Después de eso, este nodo se tira hacia el objeto (porque la cuadrícula es de "goma", luego, junto con este nodo, los nodos vecinos se tiran hacia arriba de la misma manera, pero con menos fuerza).
Luego se selecciona otro objeto (punto) y se repite el procedimiento. Como resultado, obtendremos un mapa cuya ubicación de los nodos coincide con la ubicación de los principales grupos de objetos en el espacio original Fig.13.11. Además, el mapa resultante tiene la siguiente propiedad notable: sus nodos están ubicados de tal manera que los objetos que son similares entre sí corresponden a los nodos vecinos del mapa. Ahora determinamos qué objetos metimos en qué nodos del mapa. Esto también está determinado por el nodo más cercano: el objeto golpea el nodo más cercano a él. Como resultado de todas estas operaciones, los objetos con parámetros similares terminarán en un nodo o en nodos vecinos. Por lo tanto, podemos suponer que pudimos resolver el problema de encontrar objetos similares y agruparlos.
Pero las posibilidades de las cartas de Kohonen no acaban ahí. También le permiten presentar la información recibida de forma simple y visual mediante la aplicación de colores. Para ello, coloreamos el mapa resultante (más precisamente, sus nodos) con colores correspondientes a las características de los objetos que nos interesan. Volviendo al ejemplo con la clasificación de los bancos, puede colorear de un solo color aquellos nodos en los que entró al menos uno de los bancos cuya licencia fue revocada. Luego, después de colorear, obtendremos una zona que se puede llamar zona de riesgo, y el hecho de que el banco al que nos interesa entrar en esta zona indica su falta de fiabilidad.
Pero eso no es todo. También podemos obtener información sobre dependencias entre parámetros. Al colorear el mapa correspondiente a los distintos artículos de los informes, puede obtener el llamado atlas, que almacena información sobre el estado del mercado. Al analizar, comparar la disposición de los colores en los colorantes generados por varios parámetros, se puede obtener información completa sobre el retrato financiero de los bancos: bancos perdedores, bancos prósperos, etc.
Con todo esto, la tecnología descrita es un método universal de análisis. Con su ayuda, puede analizar varias estrategias de actividad, analizar los resultados de la investigación de mercado, verificar la solvencia de los clientes, etc.
Teniendo un mapa frente a nosotros y conociendo información sobre algunos de los objetos bajo estudio, podemos juzgar con bastante confianza objetos con los que estamos poco familiarizados. ¿Necesita saber cómo es un nuevo socio? Mostrémoslo en el mapa y miremos a los vecinos. Como resultado, es posible extraer información de la base de datos basada en características difusas.
LIMPIEZA Y CONVERSIÓN DE LA BASE DE DATOS
Preliminarmente, antes de la entrada de la red, la transformación de datos utilizando métodos estadísticos estándar puede mejorar significativamente tanto los parámetros de entrenamiento (duración, complejidad) como el rendimiento del sistema. Por ejemplo, si la serie de entrada tiene una forma exponencial distinta, luego de su logaritmo, resultará una serie más simple, y si tiene dependencias complejas de alto orden, ahora será mucho más fácil detectarlas. Muy a menudo, los datos que no se distribuyen normalmente se someten preliminarmente a una transformación no lineal: la serie inicial de valores de una variable se transforma mediante alguna función, y la serie de salida se toma como una nueva variable de entrada. Los métodos de conversión típicos son exponenciación, extracción de raíces, recíprocos, exponenciales o logaritmos.
Para mejorar estructura de información datos, ciertas combinaciones de variables pueden ser útiles - obras, privado, etc. Por ejemplo, cuando intenta predecir los cambios en el precio de las acciones a partir de los datos de posición del mercado de opciones, la relación entre las opciones de venta y las opciones de compra es más que informativa que estos dos indicadores por separado. Además, con la ayuda de tales combinaciones intermedias, a menudo es posible obtener más modelo sencillo, lo cual es especialmente importante cuando el número de grados de libertad es limitado.
Finalmente, algunas funciones de transformación implementadas en el nodo de salida tienen problemas de escala. El sigmoide se define en el intervalo, por lo que la variable de salida debe escalarse para que tome valores en este intervalo. Se conocen varios métodos de escalado: cambio por un cambio constante y proporcional de valores con un nuevo mínimo y máximo, centrado restando el valor promedio, llevando la desviación estándar a uno, estandarización (los dos últimos pasos juntos). Tiene sentido asegurarse de que los valores de todos los valores de entrada y salida en la red siempre se encuentren, por ejemplo, en el intervalo (o [-1,1]), entonces será posible usar cualquier funciones de transformación sin riesgo.
CONSTRUYENDO EL MODELO
Los valores de la serie objetivo (esta es la serie que se encuentra, por ejemplo, el rendimiento de las acciones para el día siguiente) dependen de N factores, entre los que pueden existir combinaciones de variables, valores pasados del objetivo indicadores cualitativos variables y codificados.
La evaluación de la calidad del modelo generalmente se basa en una prueba de bondad de ajuste como el error cuadrático medio (MSE) o la raíz cuadrada del mismo (RMSE). Estos criterios muestran qué tan cerca estaban los valores predichos de los conjuntos de entrenamiento, confirmación o prueba.
En el análisis de series temporales lineales, se puede obtener una estimación imparcial de la generalizabilidad examinando los resultados del trabajo en el conjunto de entrenamiento (MSE), el número de parámetros libres (W) y el tamaño del conjunto de entrenamiento (N). Las estimaciones de este tipo se denominan criterios de información(1C) e incluyen un componente de bondad de ajuste y un componente de penalización que tiene en cuenta la complejidad del modelo. Se han propuesto los siguientes criterios de información: Normalizado (NAIC), Normalizado Bayesiano (NBIC) y Error de Pronóstico Final (FPE):
subtítulo">
SOFTWARE
Hasta la fecha, muchos paquetes de programas que implementan redes neuronales. Estos son algunos de los más famosos: Simuladores de redes neuronales en el mercado software: Nestor, Correlación en cascada, Neudisk, Mimenice, Nu Web, Brain, Dana, Neuralworks Professional II Plus, Brain Maker, HNet, Explorer, Explorenet 3000, Neuro Solutions, Prapagator, Matlab Toolbox. También cabe mencionar los simuladores distribuidos gratuitamente a través de servidores universitarios (por ejemplo, SNNS (Stuttgart) o Nevada QuickPropagation). Una cualidad importante del paquete es su compatibilidad con otros programas involucrados en el procesamiento de datos. Además, son importantes una interfaz fácil de usar y un rendimiento que puede alcanzar muchos megaflops (millones de operaciones de punto flotante por segundo). Las placas aceleradoras reducen el tiempo de formación cuando se trabaja en sistemas convencionales Computadoras personales. Sin embargo, obtener resultados confiables con redes neuronales generalmente requiere una computadora poderosa.
Los paradigmas establecidos de la ciencia financiera, como el modelo de caminata aleatoria y la hipótesis del mercado eficiente, asumen que los mercados financieros responden de manera racional y fluida a la información. En este caso, es casi imposible encontrar algo mejor que las relaciones lineales y el comportamiento estacionario con una tendencia reversible. Desafortunadamente, en el comportamiento real de los mercados financieros, vemos no solo la reversibilidad de las tendencias, sino también constantes descalces cambiarios, volatilidad que claramente no se corresponde con la información entrante y saltos periódicos en los niveles de precios y la volatilidad. Se han desarrollado varios modelos nuevos para describir el comportamiento de los mercados financieros y han tenido cierto éxito.
ANÁLISIS FINANCIERO EN EL MERCADO DE VALORES
El análisis financiero en el mercado de valores utilizando tecnologías de redes neuronales en este documento se lleva a cabo en relación con el comercio de petróleo y productos derivados del petróleo.
El crecimiento macroeconómico y el bienestar del país dependen en gran medida del nivel de desarrollo de las industrias básicas, entre las cuales las industrias de producción y refinación de petróleo juegan un papel sumamente importante. La situación en la industria petrolera determina en gran medida el estado de toda la economía rusa. En relación con la situación actual de los precios en el mercado mundial del petróleo, para Rusia, el lado más rentable de la industria petrolera es la exportación. La exportación de petróleo es una de las fuentes más importantes y rápidas de ingreso de divisas. Uno de los mejores representantes de la industria petrolera es la compañía petrolera "LUKOIL". LUKOIL Oil Company es la compañía petrolera integrada verticalmente líder de Rusia que se especializa en la producción y refinación de petróleo, producción y comercialización de productos derivados del petróleo. La empresa opera no solo en Rusia, sino también en el extranjero, participando activamente en proyectos prometedores.
Las actividades financieras y productivas de la empresa se describen en la tabla 13.1.
Mesa. 13.1
Principales indicadores financieros y operativos de 1998
Documento sin titulo
| Producción de petróleo (incluyendo gas condensado) | 64192 1284 |
|
| Producción de gas comercial | millones de metros cúbicos m/año millones de metros cúbicos pies/día | 3748 369 |
| Refino de petróleo (refinerías propias, incluidas las extranjeras) | miles de toneladas/año miles de barriles/día | 17947 359 |
| Exportación de petróleo | mil toneladas/año | 24711 |
| Exportación de productos petrolíferos | mil toneladas/año | 3426 |
| Ingresos netos de las ventas | millones de rublos millones de dólares* | 81660 8393 |
| beneficio de las ventas | millones de rublos millones de dólares* | 5032 517 |
| Beneficio antes de impuestos (según el informe) | millones de rublos millones de dólares* | 2032 209 |
| Beneficio antes de impuestos (sin diferencia de cambio) | millones de rublos millones de dólares* | 5134 528 |
| Utilidades retenidas (según informe) | millones de rublos millones de dólares* | 118 12 |
| Utilidades retenidas (excluyendo diferencias de cambio) | millones de rublos millones de dólares* | 3220 331 |
| Activos (fin de año) | millones de rublos millones de dólares* | 136482 6638 |
En relación con la continua caída de los precios mundiales de los productos del petróleo en 1998, sus exportaciones ascendieron a 3,4 millones de toneladas frente a 6,3 millones en 1997. Para mantener las posiciones de la Compañía en el mercado mundial de productos derivados del petróleo, se planea aumentar el volumen de exportaciones en 1999 a 5-6 millones, sujeto a una mejora en las condiciones del mercado. La tarea prioritaria es crear condiciones estimulantes para el crecimiento de las exportaciones y extraer el máximo beneficio posible.
Un componente importante del proceso de venta de petróleo y productos derivados del petróleo para la exportación, incluidas todas las formas de contratos, el procedimiento para fijar precios, la responsabilidad de las partes, y más, es el intercambio. Acumula todos los procesos que ocurren en la etapa de compra y venta de un producto determinado y ayuda a asegurar contra los riesgos asociados.
Bolsas donde se negocian contratos de futuros de petróleo y derivados: New York Mercantile Exchange (NYMEX) y London International Petroleum Exchange (IPE). Una bolsa de valores es un mercado mayorista legalmente organizado como una organización de comerciantes. El desarrollo de mecanismos para la negociación de contratos de futuros y la introducción de estos últimos en todos los activos que anteriormente se negociaban en bolsas de materias primas, futuros y divisas, ha llevado a difuminar las diferencias entre estos tipos de bolsas y al surgimiento de cualquiera de los futuros. intercambios, donde solo se negocian contratos de futuros, o intercambios universales, en los que se negocian tanto contratos de futuros como activos tradicionales negociados en bolsa, como acciones, divisas e incluso productos básicos individuales.
Las funciones de la bolsa son las siguientes:
organización de reuniones de intercambio para la realización de subastas públicas abiertas;
desarrollo de contratos de intercambio;
arbitraje cambiario, o resolución de disputas que surjan de transacciones cambiarias concluidas en el curso de transacciones bursátiles;
la función de valor del intercambio. Esta función tiene dos aspectos. La primera es que la tarea de la bolsa es identificar los precios de mercado "verdaderos", pero al mismo tiempo regularlos para evitar la manipulación ilegal de los precios en la bolsa. El segundo es la función predictiva de precios del intercambio;
función de cobertura, o seguro cambiario de los participantes en la negociación bursátil contra fluctuaciones de precios que les sean desfavorables. La función de cobertura se basa en el uso del mecanismo de negociación de contratos de futuros. La esencia de esta función es que el comerciante, el coberturista (es decir, el que asegura), debe convertirse tanto en el vendedor de los bienes como en su comprador. En este caso, se neutraliza cualquier cambio en el precio de su mercancía, ya que la ganancia del vendedor es al mismo tiempo la pérdida del comprador y viceversa. Esta situación se logra por el hecho de que el coberturista, tomando, por ejemplo, la posición del comprador en el mercado ordinario, debe tomar la posición contraria, en este caso el vendedor, en el mercado de contratos de futuros de cambio. Por lo general, los productores de bienes se protegen contra los recortes de precios de sus productos y los compradores, contra los aumentos de precios de los productos comprados:
actividad cambiaria especulativa;
la función de garantizar la ejecución de las transacciones. Logrado a través de sistemas de compensación y liquidación basados en el intercambio;
función de información del intercambio.
Las principales fuentes de información sobre el estado y las perspectivas de desarrollo del mercado mundial del petróleo y sus derivados son las publicaciones de las agencias de cotización Piatt's (una división estructural de la mayor corporación editorial estadounidense McGraw-Hill) y Argus Petroleum (una empresa independiente, Great Bretaña).
Las cotizaciones dan una idea del rango de precios de un grado particular de petróleo en un día determinado. En consecuencia, están compuestos por el precio mínimo (el precio mínimo de transacción o el precio medio ponderado mínimo de oferta para comprar un determinado grado de petróleo) y el precio máximo (el precio máximo de transacción o el precio medio ponderado máximo de oferta para vender).
La precisión de las cotizaciones depende de la cantidad de información recopilada. Los primeros datos sobre las cotizaciones se dan en tiempo real (se pueden obtener si tiene acceso al equipo correspondiente) a las 21:00-22:00 hora de Moscú. Estos datos podrán ser corregidos en caso de recepción antes del final del día de nueva información sobre transacciones, especificando cotizaciones preliminares. La versión final de las cotizaciones se encuentra en las publicaciones oficiales impresas de estas agencias.
Las cotizaciones se dan tanto para transacciones con entrega inmediata - precios "spot" (entrega dentro de dos semanas, y para algunos grados de petróleo - dentro de tres semanas), como para transacciones con entrega diferida (para grados clave de petróleo) - precios "forward" (entrega en un mes, dos meses y tres meses).
La información sobre las cotizaciones "spot" y "forward" es un elemento clave en el comercio de petróleo en el mercado libre. Las cotizaciones al contado se utilizan para evaluar la corrección del precio elegido de una operación a plazo previamente concluida; para la emisión de facturas por entregas, las cuales se liquidan en base a fórmulas basadas en cotizaciones al contado en el momento del embarque de las mercancías; y también como punto de partida desde el cual las contrapartes comienzan a discutir los términos de precio de las transacciones en el siguiente día de cotización.
Las cotizaciones "forward", que reflejan precios fijos de transacciones con entrega diferida, representan esencialmente una evaluación predictiva por parte de los participantes del mercado de la situación para un mes, dos y tres meses venideros. En combinación con las cotizaciones "spot", las cotizaciones "forward" muestran la tendencia actual más probable en los precios de este grado de petróleo para un período de uno, dos y tres meses.
Se dan cotizaciones para aceite de este grado de calidad estándar. Si la calidad de un lote de aceite en particular difiere del estándar, al finalizar la transacción, el precio del lote se establece sobre la base de cotizaciones, teniendo en cuenta un descuento o una prima por calidad.
El monto del descuento o prima por calidad depende de la medida en que el precio neto de un lote particular de productos difiere del precio neto del petróleo de este grado de calidad estándar.
Resumiendo el contenido de todo lo dicho, notamos que para garantizar una exportación eficiente de petróleo, el proveedor debe tener datos sobre cotizaciones al contado y a plazo, precios de productos derivados del petróleo y posiciones de futuros, información sobre precios netos, fletes y tarifas de seguros. , dinámica de spreads y stocks petroleros. Mínimo requisitos de información reduzca al conocimiento de las cotizaciones "spot" y "forward" para el petróleo exportado y grados competitivos de petróleo, la dinámica de los diferenciales, fletes y tarifas de seguros. Los principales tipos de contratos de futuros celebrados en la bolsa de valores incluyen:
contratos futuros- un contrato para la compra y venta de bienes en el futuro al precio en el momento de la transacción.
Una opción es un contrato que otorga el derecho, pero no la obligación, de comprar o vender un contrato de futuros de petróleo o productos derivados del petróleo en el futuro a un precio deseado. Las opciones se negocian en las mismas bolsas donde se negocian los contratos de futuros.
transacción a plazo- una transacción, cuyo término no coincide con el momento de su conclusión en la bolsa de valores y está estipulado en el contrato.
Una operación "spot" se caracteriza por el hecho de que el término de su conclusión coincide con la fecha de ejecución, y en tal operación la moneda debe entregarse inmediatamente (por regla general, a más tardar dos días hábiles después de la conclusión de la operación). ).
Al concluir un contrato, un papel especial es jugado por precisión del pronóstico de la situación en el mercado para este tipo de producto, así como una previsión de precio para el mismo. Por lo tanto, consideramos importante considerar el papel de las estimaciones predictivas para lograr el efecto del comercio de petróleo y productos derivados.
Al realizar estas transacciones, hay un punto clave: esta es la precisión de los pronósticos. Por supuesto, en términos de teoría, parecería que no nos importa dónde estarán los precios en el futuro. Habiendo abierto una posición, cerramos el precio de venta del petróleo para nosotros, para nosotros ya no puede ser más alto o más bajo. Por lo tanto, un pronóstico preciso nos da la opción de tomar las medidas necesarias cuando cambia el precio. Un pronóstico incorrecto significa pérdidas. Hay muchas formas de predecir el mercado, pero solo unas pocas merecen una atención especial. Durante muchos años, la previsión del mercado financiero se ha basado en la teoría de las expectativas racionales, el análisis de series temporales y el análisis técnico.
De acuerdo con la teoría de las expectativas racionales, los precios suben o bajan porque los inversores reaccionan de forma racional e inmediata a la nueva información: cualquier diferencia entre los inversores, por ejemplo, en términos de objetivos de inversión o información disponible para ellos, se ignora como estadísticamente insignificante. Tal enfoque se basa en la suposición de una apertura completa de la información del mercado, es decir, en el hecho de que ninguno de sus participantes tiene información que otros participantes no tendrían. En este caso, no puede haber ventajas competitivas, ya que, al tener información que no está disponible para otros, es imposible aumentar las posibilidades de obtener ganancias.
El propósito del análisis de series de tiempo es identificar una cierta cantidad de factores que afectan los cambios de precios utilizando métodos estadísticos. Este enfoque le permite identificar las tendencias del mercado, sin embargo, si hay repetición o ciclos homogéneos en la serie de datos, su aplicación puede estar asociada con serias dificultades.
Análisis técnico es un conjunto de métodos de análisis y toma de decisiones basados únicamente en el estudio de los parámetros internos del mercado de valores: precios, volúmenes de transacciones y el valor de interés abierto (el número de contratos abiertos de compra y venta). Toda la variedad de métodos de pronóstico del análisis técnico se puede dividir en dos grandes grupos: métodos gráficos y métodos analíticos.
El análisis técnico gráfico es el análisis de varios mercados modelos gráficos, formado por ciertos patrones de movimiento de precios en los gráficos, para sugerir la probabilidad de continuación o cambio de la tendencia existente. Considere los principales tipos de gráficos:
Lineal. En un gráfico de líneas, solo se marca el precio de cierre de cada período posterior. Recomendado para períodos cortos (hasta varios minutos).

Gráfico de segmentos (barras): un gráfico de barras muestra el precio máximo (el punto superior de la barra), el precio mínimo (el punto inferior de la barra), el precio de apertura (guión a la izquierda de la barra vertical) y el precio de cierre. precio (guión a la derecha de la barra vertical). Recomendado para periodos de 5 minutos o más.

Candelabros japoneses (construidos por analogía con barras).

Tic-tac-toe: no hay un eje de tiempo y se construye una nueva columna de precios después de la aparición de otra dirección de la dinámica. Se dibuja una cruz si los precios han disminuido en un cierto número de puntos (criterio de reversión), si los precios han aumentado en un cierto número de puntos, entonces se dibuja un cero.

Escalas aritméticas y logarítmicas. Para algunos tipos de análisis, especialmente cuando se trata de analizar tendencias a largo plazo, es conveniente utilizar una escala logarítmica. En la escala aritmética, las distancias entre divisiones no cambian. En una escala logarítmica, la misma distancia corresponde al mismo cambio porcentual.
Gráficos de volumen.

Los postulados de este tipo de análisis técnico son los siguientes conceptos básicos del análisis técnico: líneas de tendencia, niveles de resistencia y soporte del mercado, niveles de corrección de tendencia actual. Por ejemplo:

Líneas de resistencia:
Ocurren cuando los clientes ya no pueden o no quieren comprar un producto dado a un precio más alto. La presión de venta supera la presión de los compradores, como resultado, el crecimiento se detiene y es reemplazado por una caída;
conectar máximos importantes (tops) del mercado.

Líneas de apoyo:
conectar puntos bajos importantes (fondos) del mercado;
Ocurren cuando los vendedores ya no pueden o no quieren vender un producto determinado a un precio más bajo. A este nivel de precios, el impulso de compra es lo suficientemente fuerte como para resistir la presión de venta. La caída se detiene y los precios comienzan a subir de nuevo.

Al bajar, la línea de soporte se convierte en resistencia. Al subir, la línea de resistencia se convierte en soporte.

Si los precios fluctúan entre dos líneas rectas paralelas (líneas de canal), podemos hablar de la presencia de un canal ascendente (hacia abajo u horizontal).

Hay dos tipos de modelos gráficos:
1. Modelos de inversión de tendencia: modelos formados en los gráficos que, bajo ciertas condiciones, pueden anticipar un cambio en la tendencia existente en el mercado. Estos incluyen patrones tales como "cabeza y hombros", "doble techo", "doble fondo", "triple techo", "triple suelo".
Consideremos algunos de ellos.
"Cabeza - Hombros" - confirma el cambio de tendencia.

Figura 13.22. 1-primer vértice; pico de 2 segundos; cuello de 3 líneas
CabezaHombros - cabeza - hombros.

Figura 13.23. 1-parte superior del hombro izquierdo; 2-parte superior de la cabeza, 3-parte superior del hombro derecho; Cuello de 4 líneas.
2. Modelos de continuación de tendencia: modelos formados en los gráficos que, bajo ciertas condiciones, nos permiten afirmar que existe la posibilidad de continuar con la tendencia actual. Quizás la tendencia se desarrolló demasiado rápido y entró temporalmente en un estado de sobrecompra o sobreventa. Luego, luego de una corrección intermedia, continuará su desarrollo en la dirección de la tendencia anterior. En este grupo, se distinguen modelos como "triángulos", "diamantes", "banderas", "banderines" y otros. Por ejemplo:


Por regla general, estas figuras terminan su formación a una distancia de la parte superior P (eje) igual a:
definir ">
Triángulo

Los triángulos en el mercado deben tener miedo. R es el precio base. T es la base de tiempo. El desglose de la figura se produce a distancia: ">
recopilación y almacenamiento de datos: posibles participantes en el pronóstico (ya sea como criterio, como valor predicho o ambos);
definición para la tendencia considerada o conjunto de criterios (además, los datos almacenados directamente en la base de datos no siempre se pueden usar, a menudo es necesario realizar algunas transformaciones de datos, por ejemplo, es racional usar cambios relativos en los valores como criterio );
identificar la relación entre el valor predicho y un conjunto de criterios en forma de una determinada función;
cálculo del valor de interés de acuerdo con una determinada función, los valores de los criterios para el momento pronosticado y el tipo de pronóstico: a corto o largo plazo).
En la parte práctica del trabajo, a partir de los datos históricos de una tendencia para un período de tiempo determinado (mes, año, varios años), presentados también en una escala de tiempo determinada (minuto, 5 minutos, media hora, diario, etc. cotizaciones), necesitamos obtener un pronóstico de desarrollo de cotizaciones para varios incrementos de tiempo por delante. La información sobre las cotizaciones de los activos se presenta mediante todos o parte de los parámetros estándar que describen las cotizaciones para un intervalo de tiempo: apertura, precios de cierre, máximo, mínimo, volumen de negociación en el momento del cierre, interés abierto.
El uso de redes neuronales para obtener un pronóstico rápido y de alta calidad se puede considerar en la Fig. 13.27 “Esquema tecnológico de previsión en el mercado de valores utilizando redes neuronales”.
Para un pronóstico completo de las tendencias de los tres mercados más desarrollados de nuestro país, que incluyen muchos instrumentos financieros, se necesita una cantidad suficiente de datos iniciales para el pronóstico. Como puede verse en el diagrama, en este momento se ha recibido la siguiente información:
información y datos comerciales de las agencias REUTERS, DOW JONES TELERATE, BLOOMBERG;
datos comerciales de las plataformas MICEX y RTS;
otros datos mediante entrada manual.
Todos los datos necesarios se ingresan en la base de datos (DB MS servidor SQL). Luego viene la selección y preparación de datos para participar en el pronóstico. En esta etapa preliminar, la tarea es seleccionar entre más de 200 tipos de información y datos comerciales, los criterios más significativos para pronosticar el valor de un determinado instrumento financiero o grupo de instrumentos financieros de interés. La elección primaria de criterios la hace el analista y depende de la experiencia e intuición de este último. Para ayudar al analista, se proporcionan herramientas de análisis técnico, presentadas en forma de gráficos, mediante el análisis de las cuales puede detectar relaciones ocultas. Se asigna una serie de tiempo de pronóstico.
Luego, los datos procesados se introducen en el paquete de red neuronal STATIS-TICA Neural Networks, donde se reconocen períodos de 5 días utilizando el perceptrón entrenado. A cada uno de los períodos, la red asigna uno de los cuatro indicadores que caracterizan los cambios de tendencia (como gráficos en el análisis técnico): período estable, ascendente, descendente, indefinido. Con base en los datos procesados, la red construye un pronóstico, pero para refinar los resultados obtenidos, complicamos el proceso de pronóstico. El procesamiento posterior tiene lugar en el sistema STATIST1CA. No es necesario convertir los datos porque son del mismo tipo.
En el proceso de procesamiento de la serie temporal en el paquete STATISTICA en el módulo TIME Series / Forecasting mediante suavizado exponencial (exponential smoothing forecasting), se selecciona una tendencia, la cual se divide en partes iguales (períodos de 5 días) para su posterior pronóstico a corto plazo . La tendencia se configura utilizando uno de los cuatro métodos presentados (lineal, exponencial, horizontal, polinomial). Elegimos el método exponencial para nuestro experimento. Procesamos la tendencia y recibimos datos sobre su suavizado. Estos datos se envían nuevamente al procesamiento de la red neuronal utilizando un perceptrón multicapa. El entrenamiento se realiza utilizando el método de suavizado exponencial, como resultado de lo cual la red confirma la exactitud del pronóstico obtenido previamente. Puede ver los resultados utilizando la función de archivo.
Los valores pronosticados resultantes son analizados por el comerciante, como resultado de lo cual se toma la decisión correcta de realizar transacciones con valores.
Uno de los enfoques para resolver el problema del análisis y pronóstico del mercado de valores se basa en la naturaleza cíclica del desarrollo de los procesos económicos. Una manifestación de la ciclicidad es el desarrollo ondulatorio de los períodos económicos. Al pronosticar series temporales en la economía, es imposible evaluar correctamente la situación y hacer un pronóstico lo suficientemente preciso sin tener en cuenta el hecho de que las fluctuaciones cíclicas se superponen a la línea de tendencia. En la ciencia económica moderna se conocen más de 1380 tipos de ciclicidad. La economía opera por excelencia con los siguientes cuatro:
Los ciclos de cocina son ciclos de inventario. Kitchin (1926) se centró en el estudio de ondas cortas con una duración de 2 a 4 años a partir del análisis de cuentas financieras y precios de venta en el movimiento de inventarios.
Ciclos juglares. Este ciclo tiene otros nombres: ciclo económico, ciclo industrial, etc. Los ciclos se descubrieron al estudiar la naturaleza de las fluctuaciones industriales en Francia, Gran Bretaña y los Estados Unidos, con base en el análisis fundamental de las fluctuaciones en las tasas de interés y los precios. Resultó que estas fluctuaciones coincidieron con un ciclo de inversión, que a su vez inició cambios en el PNB, la inflación y el empleo.
Ciclos de Kuznets. J. Riggalman, V. Newman en la década de 1930 y algunos otros analistas construyeron los primeros índices estadísticos de la construcción anual total de viviendas y encontraron largos intervalos sucesivos de rápido crecimiento y profundas recesiones o estancamiento. Entonces apareció por primera vez el término "ciclos de construcción".
Ciclos de Kondratieff. Los ciclos grandes pueden verse como una violación y restauración del equilibrio económico durante un largo período. Su razón principal radica en el mecanismo de acumulación, acumulación y dispersión de capital suficiente para crear las principales fuerzas productivas. Sin embargo, el efecto de esta causa primaria amplifica el efecto de los factores secundarios. De acuerdo con lo anterior, el desarrollo de un gran ciclo lleva la siguiente iluminación. El inicio del ascenso coincide con el momento en que la acumulación y acumulación de capital alcanza tal tensión que se hace posible invertir rentablemente el capital para los fines de las fuerzas productivas y el reequipamiento radical de la tecnología. Además, de acuerdo con las "verdades" básicas de Kondratiev, durante el período de una onda ascendente de un ciclo grande, las ondas medias y cortas se caracterizan por una dispersión corta y la intensidad de las subidas, y durante los períodos de una onda descendente de un ciclo grande, se observa el cuadro opuesto.
En el mercado de valores, estas fluctuaciones se manifiestan en sucesivas subidas y bajadas en los niveles de actividad comercial durante un período de tiempo: un pico de ciclo, una recesión, un valle y una fase de recuperación.
En este trabajo partimos del hecho de que las fluctuaciones de precios en el mercado de valores son el resultado de una superposición de las distintas ondas indicadas anteriormente y una serie de factores estocásticos aleatorios. Se intenta identificar la presencia de ciclos y determinar la fase en la que se encuentra el proceso. En base a esto, se hace un pronóstico. mayor desarrollo proceso utilizando herramientas ARIMA bajo supuestos adecuados sobre el parámetro del proceso.
Las transiciones del sistema son una superposición de ondas de diferentes longitudes. Como sabes, las ondas tienen varias fases que se reemplazan entre sí. Puede ser una fase de recuperación, recesión o estancamiento. Si a estas fases se les asignan valores simbólicos A, B, C, entonces pueden representarse como una secuencia de primitivas (similares a los gráficos en el análisis técnico) y, reconociendo estas secuencias (que también representan períodos de ascenso, caída, estancamiento, es decir, a, b, c, solo en una escala más pequeña), podemos, según las reglas de reconocimiento de gramáticas con cierta probabilidad, la fórmula" src="http://hi-edu.ru/e-books/xbook725/ archivos/28.gif" border= "0" align="absmiddle" alt="(!LANG:. Entonces también podemos considerar secuencias de la forma AAABBCD…. .Resulta que hemos reconocido tanto la propia onda como su fase.
Ahora no solo podemos hacer un pronóstico a corto plazo más preciso, sino que también podemos rastrear la dinámica general del mercado de valores en el futuro (habiendo determinado la fase de una onda larga, podemos juzgar la naturaleza de la próxima, ya que las fases proceden en una cierta secuencia). En nuestro experimento, intentamos entrenar al perceptrón para que reconozca las fases de onda (A, B, C, D).
Para el experimento, se tomaron datos de los resultados de la negociación con el RTS de las acciones de la empresa LUKOIL (LKON) para el período del 01 de junio de 1998. al 31 de diciembre de 1999. La base de datos inicial incluía las siguientes variables: precio promedio ponderado de compra, precio promedio ponderado de venta, precio máximo diario, precio mínimo diario, número de transacciones. La base de datos con los valores de las variables enumeradas se importó al entorno de Excel desde Internet y luego se transfirió al paquete SNW. Este procedimiento se analiza con más detalle en arroz. 13.28 son los pesos que toman las observaciones individuales de la serie.
El ancho del intervalo de suavizado se tomó igual a 4 observaciones. Luego se agregó la expresión de tendencia numérica (Figura 13.30) a la nueva variable de suavizado.
Por lo tanto, hemos formado una base de datos con variables que se alimentarán a la entrada de la red neuronal. Además, desde SNW es totalmente compatible con SNN, no hubo necesidad de importar datos específicamente a SNN. A la entrada se suponía que debía recibir valores como a, b, c, d, pero para ello el perceptrón tenía que reconocer la fase en la que nos encontramos y, en base a ello, hacer una previsión más precisa a corto plazo. En otras palabras, debe considerar secuencias de primitivas e identificarlas con fases del ciclo. Además, el perceptrón no emite fases de ciclo del tipo A,B,C,D.
Para implementar la tarea de entrenar al perceptrón, se asigna una ventana móvil con un ancho de 5 días. Una ventana de tiempo consiste en una secuencia de primitivas a, b, c o d. Por lo tanto, se puede obtener un pronóstico más preciso mediante la aproximación por tramos de la tendencia numérica por el precio de compra promedio ponderado.
Para entrenar al perceptrón para reconocer secuencias de cinco días e identificarlas como A, B, C o D, tuvimos que determinar su fase nosotros mismos para una serie de opciones y agregar nuestros resultados a una nueva variable en la base de datos original (estado ). Así, la base de datos final contiene los valores de las siguientes variables: precio medio ponderado de compra, precio medio ponderado de venta, precio máximo diario, precio mínimo diario, número de transacciones, tendencia destacada relativa al precio medio ponderado de compra, y, finalmente, una variable que determina el estado del proceso económico. Todas las variables, excepto la última, fueron enviadas a la entrada. Se suponía que se recibiría solo en la salida, de modo que el perceptrón no reaccionaría al valor de esta variable durante el entrenamiento, sino que ajustaría los pesos de tal manera que solo se podrían obtener cuatro valores en la salida: A , B, C, D, y luego, de acuerdo con el estado reconocido, y también tuvo en cuenta que después de la fase de subida sigue una fase de constancia, y luego de nuevo una fase de declive, y sobre esta base fue capaz de hacer una reducción previsión de plazos. Por lo tanto, todos los datos se recopilan para el pronóstico. Ahora solo queda una pregunta: qué parámetros elegir para la red y qué método entrenar. En este sentido, se llevaron a cabo una serie de experimentos y como resultado se extrajeron las siguientes conclusiones.
Inicialmente, se suponía que debía entrenar un perceptrón multicapa utilizando el método de retropropagación de errores. Se aplicaron 7 variables a la entrada (se enumeran arriba), a la salida, solo una, ESTADO. Además de las capas de entrada y salida, se construyó una capa intermedia, que consta de 6 y luego 8 neuronas. El error de aprendizaje fue de aproximadamente 0,2 a 0,4, pero el perceptrón reaccionó débilmente a los estados de transición. Por lo tanto, decidimos aumentar primero el número de neuronas en la capa intermedia a 14 y luego cambiar el método de entrenamiento del perceptrón ("gradientes conjugados"). El error comenzó a fluctuar entre 0,12 y 0,14, y todo el conjunto de valores de las variables se consideró como entrenamiento.
Como resultado de los experimentos, una red neuronal con los siguientes parámetros resultó ser óptima: se proporcionan 7 variables como entrada: Smoothly, Average, Open_Buy, VoLTrad. Val_Q, Min_PR, Max_PR, salida - ESTADO. El entrenamiento se llevó a cabo con un paso de 6, utilizando el método de gradiente conjugado, en total - 3 capas (en las primeras 7 neuronas, en la segunda - 14, en la tercera - 3) (Fig. 13.29), como resultado, el perceptrón respondió claramente a los estados de tendencia (ascendente - 1 capa de salida, descendente ndash; 2 neuronas de la capa de salida y horizontal - 3 neuronas) (Fig. 13.31).
Como resultado de la investigación se seleccionaron datos como posibles objetos del pronóstico, se determinaron los valores pronosticados y conjuntos de criterios, y se identificaron las dependencias entre ellos.
Durante el experimento, se encontró que la detección de tendencias aumenta la tasa de aprendizaje del perceptrón multicapa y, con cierta regulación de la red, reconoce tendencias ascendentes, descendentes y horizontales.
Los resultados positivos obtenidos permiten profundizar en el estudio de las dependencias cíclicas de los mercados y utilizar otros métodos de tecnologías neuronales (mapas de Kohonen) a la hora de realizar transacciones financieras.
Enviar su buen trabajo en la base de conocimiento es simple. Utilice el siguiente formulario
Los estudiantes, estudiantes de posgrado, jóvenes científicos que utilizan la base de conocimientos en sus estudios y trabajos le estarán muy agradecidos.
- Introducción
- Conclusión
- Introducción
- Un efecto beneficioso en el desarrollo de tecnologías de redes neuronales fue la creación de métodos para el procesamiento paralelo de información.
- Es necesario expresar gratitud al notable cirujano, filósofo y cibernético N.M. Amosov, quien, junto con sus alumnos, sistematizó el enfoque para crear herramientas de inteligencia artificial (IA). Este enfoque es el siguiente.
- Las estrategias de IA se basan en el concepto de paradigma: una vista (representación conceptual) de la esencia de un problema o tarea y el principio de su solución. Considere dos paradigmas de inteligencia artificial.
- 1. El paradigma experto involucra los siguientes objetos, así como las etapas de desarrollo y operación del sistema de IA:
- * formateo del conocimiento: transformación por parte de un experto del conocimiento problemático en una forma prescrita por el modelo elegido de representación del conocimiento;
- * formación de una base de conocimientos<БЗ) - вложение формализованных знаний в программную систему;
- * deducción - la solución del problema de la inferencia lógica basada en la base de conocimientos.
- Este paradigma subyace en el uso de sistemas expertos, sistemas de inferencia, incluido el lenguaje de programación lógica PROLOG. Se cree que los sistemas basados en este paradigma están más estudiados.
- 2. El paradigma del estudiante, incluyendo las siguientes disposiciones y secuencia de acciones:
- * procesamiento de observaciones, estudio de la experiencia de ejemplos particulares - la formación de una base de datos<БД>sistemas de IA;
- * aprendizaje inductivo: la transformación de la base de datos en una base de conocimiento basada en la generalización del conocimiento acumulado en la base de datos. y fundamentación del procedimiento de extracción de conocimientos de la base de conocimientos. Esto significa que, a partir de los datos, se llega a una conclusión sobre la generalidad de la relación entre los objetos que observamos. Aquí se presta atención principal al estudio de los mecanismos de aproximación, probabilísticos y lógicos para obtener conclusiones generales a partir de enunciados particulares. Entonces podemos justificar, por ejemplo, la suficiencia del procedimiento de interpolación generalizada (extrapolación), o el procedimiento de búsqueda asociativa, con cuya ayuda satisfaremos las consultas a la base de conocimiento;
- * deducción: de acuerdo con un procedimiento razonable o esperado, seleccionamos información de la base de conocimientos previa solicitud (por ejemplo, la estrategia de control óptima para un vector que caracteriza la situación actual).
- La investigación en el marco de este paradigma y su desarrollo hasta ahora se ha llevado a cabo deficientemente, aunque subyacen a la construcción de sistemas de control de autoaprendizaje (a continuación daremos un maravilloso ejemplo de un sistema de control de autoaprendizaje: las reglas de tiro en artillería).
- ¿En qué se diferencia una base de conocimientos, un elemento común e indispensable de un sistema de IA, de una base de datos? ¡Posibilidad de inferencia lógica!
- Ahora pasemos a la inteligencia "natural". La naturaleza no ha creado nada mejor que el cerebro humano. Esto significa que el cerebro es tanto un portador de la base de conocimiento como un medio de inferencia lógica basado en ella, independientemente del paradigma según el cual organicemos nuestro pensamiento, es decir, de qué manera llenamos la base de conocimiento. -- ¡aprendiendo!
- SI. Pospelov, en una obra notable y única, ilumina las esferas más altas de la inteligencia artificial: la lógica del pensamiento. El propósito de este libro es diseccionar, al menos parcialmente, la red neuronal como un medio de pensamiento, llamando así la atención sobre el eslabón inicial más bajo en toda la cadena de métodos de inteligencia artificial.
- Rechazando el misticismo, reconocemos que el cerebro es una red neuronal, una red neuronal: neuronas interconectadas, con muchas entradas y una sola salida cada una. La neurona implementa una función de transferencia bastante simple que le permite convertir las excitaciones en las entradas, teniendo en cuenta los pesos de las entradas, en el valor de excitación en la salida de la neurona. Un fragmento funcionalmente completo del cerebro tiene una capa de entrada de neuronas: receptores, excitados desde el exterior, y una capa de salida, cuyas neuronas se excitan según la configuración y la magnitud de la excitación de las neuronas de la capa de entrada. Se supone que la red neuronal. imitar el trabajo del cerebro no procesa los datos en sí, sino su confiabilidad o, en el sentido generalmente aceptado, el peso, la evaluación de estos datos. Para la mayoría de los datos continuos o discretos, su tarea se reduce a indicar la probabilidad de los rangos a los que pertenecen sus valores. Para una gran clase de datos discretos, elementos de conjuntos, es recomendable fijar rígidamente las neuronas de la capa de entrada.
1. Experiencia en el uso de redes neuronales en problemas económicos
Con la ayuda de redes neuronales, resolvemos el problema de desarrollar algoritmos para encontrar una descripción analítica de los patrones de funcionamiento de los objetos económicos (empresa, industria, región). Estos algoritmos se aplican para pronosticar algunos indicadores de "salida" de objetos. Se resuelve el problema de la implementación de algoritmos en redes neuronales. El uso de métodos de reconocimiento de patrones o los métodos de redes neuronales correspondientes permite resolver algunos problemas urgentes de modelado económico y estadístico, aumentando la adecuación de los modelos matemáticos y acercándolos a la realidad económica. El uso del reconocimiento de patrones en combinación con el análisis de regresión ha dado lugar a nuevos tipos de modelos: clasificación y lineal por partes. Encontrar dependencias ocultas en las bases de datos es la base de las tareas de modelado y procesamiento del conocimiento, incluso para un objeto con patrones difíciles de formalizar.
La elección del modelo más preferido de un determinado conjunto de ellos puede entenderse como un problema de clasificación o como un problema de selección basado en un conjunto de reglas La práctica ha demostrado que los métodos basados en el uso de pesos de factores a priori y el la búsqueda de un modelo que cumpla con la suma máxima ponderada de factores conduce a resultados sesgados. Pesos: esto es lo que debe determinarse, esta es la tarea. Además, los conjuntos de pesos son locales: cada uno de ellos es adecuado solo para una tarea específica dada y un objeto dado (grupo de objetos).
Consideremos el problema de elegir el modelo deseado con más detalle. Supongamos que existe un determinado conjunto de objetos M, cuya actividad está dirigida a lograr una determinada meta. El funcionamiento de cada objeto se caracteriza por los valores de n características, es decir, existe un mapeo f: M -> Rn. Por tanto, nuestro punto de partida es el vector de estado del objeto económico: x = . Indicadores de la calidad de funcionamiento de un objeto económico: f0(x), f1(x),…,fm(x). Estos indicadores deben estar dentro de ciertos límites, y nos esforzamos para que algunos de ellos sean mínimos o máximos.
Tal enunciado general puede ser contradictorio, y es necesario aplicar el aparato para resolver las contradicciones y llevar el enunciado del problema a una forma correcta consistente con el significado económico.
Ordenamos objetos en términos de alguna función de criterio, pero el criterio suele estar mal definido, vago y posiblemente inconsistente.
Consideremos el problema de modelar regularidades empíricas utilizando un número limitado de datos experimentales y observados. El modelo matemático puede ser una ecuación de regresión o una regla de diagnóstico o una regla de predicción. Con una muestra pequeña, los métodos de reconocimiento son más efectivos. En este caso, la influencia de la gestión de factores se tiene en cuenta mediante la variación de los valores de los factores cuando se sustituyen en la ecuación de regularidad o en la regla de decisión para el diagnóstico y la previsión. Además, aplicamos la selección de características esenciales y la generación de características útiles (parámetros secundarios). Este aparato matemático es necesario para pronosticar y diagnosticar los estados de los objetos económicos.
Consideremos una red neuronal desde el punto de vista de la teoría de estructuras de comités, como un colectivo de neuronas (individuos).Una red neuronal como mecanismo para optimizar el trabajo de las neuronas en las decisiones colectivas es una forma de coordinar las opiniones individuales, en la que la opinión colectiva es la respuesta correcta a la entrada, es decir, la dependencia empírica necesaria.
Esto implica la justificación del uso de construcciones de comités en problemas de selección y diagnóstico. La idea es que en vez de buscar una sola regla de decisión para un grupo de reglas de decisión, este grupo desarrolle una decisión colectiva en virtud de un procedimiento que procese las decisiones individuales de los miembros del grupo. Los modelos de elección y diagnóstico, por regla general, conducen a sistemas inconsistentes de desigualdades, para los cuales, en lugar de soluciones, es necesario buscar generalizaciones del concepto de solución. Tal generalización es una decisión colectiva.
Entonces, por ejemplo, un comité de un sistema de desigualdades es un conjunto de elementos tal que la mayoría de los elementos de este conjunto satisfacen cada desigualdad. Las construcciones de comité son una cierta clase de generalizaciones del concepto de solución para problemas que pueden ser tanto compatibles como incompatibles. Esta es una clase de aproximaciones discretas para problemas inconsistentes, también se pueden correlacionar con soluciones difusas. El método de los comités actualmente determina una de las direcciones de análisis y solución de problemas de elección efectiva de opciones, optimización, diagnóstico y clasificación. Por ejemplo, demos la definición de una de las principales construcciones de comités, a saber: para 0< p < 1: p - комитетом системы включений называется такой набор элементов, что каждому включению удовлетворяет более чем р - я часть этого набора.
Las construcciones de comités pueden considerarse tanto como una cierta clase de generalizaciones del concepto de una solución al caso de sistemas inconsistentes de ecuaciones, desigualdades e inclusiones, como un medio de paralelización en la resolución de problemas de elección, diagnóstico y pronóstico. Como una generalización del concepto de resolución de un problema, las construcciones de comité son conjuntos de elementos que tienen algunas (pero, por regla general, no todas) propiedades de la solución; este es un tipo de soluciones difusas.
Como medio de paralelización, las estructuras de comités actúan directamente en redes neuronales multicapa. Hemos demostrado que para entrenar una red neuronal para resolver con precisión el problema de clasificación, es posible aplicar el método de construcción de un comité de algún sistema de desigualdades afines.
En base a lo anterior, se puede concluir que el método de los comités está asociado a una de las áreas importantes de investigación y solución numérica tanto de los problemas de diagnóstico y selección de opciones, como de las tareas de establecimiento de redes neuronales para la obtención de los mismos. respuesta requerida para ingresar información sobre un problema particular del host.soluciones.
Durante la operación del método de comités, se revelaron propiedades tan importantes para los problemas aplicados como la heurística, la interpretabilidad, la flexibilidad -la posibilidad de entrenamiento adicional y reconfiguración, la posibilidad de utilizar la clase de funciones más natural- afines por partes, y para planteándose el problema de clasificación, diagnóstico y previsión, sólo se requiere corrección, entonces es, para que el mismo objeto no sea asignado a diferentes clases.
El otro lado de la cuestión de las estructuras de los comités está relacionado con la noción de coaliciones en el desarrollo de decisiones colectivas, mientras que las situaciones difieren marcadamente en el caso de las preferencias colectivas (hay muchas trampas) y en el caso de las reglas de clasificación colectiva, en en cuyo caso los trámites pueden ser rigurosamente justificados y tienen más oportunidades. Por lo tanto, es importante poder reducir los problemas de toma de decisiones y pronósticos a problemas de clasificación.
2. Método tabular: la base de la inteligencia artificial.
En general, los principios de la actividad cerebral son conocidos y utilizados activamente. Usamos tablas invisibles en nuestra memoria, rellenadas con fuerza y libertad en un pupitre, al volante, con y sin maletín ministerial, girando la cabeza en una calle ruidosa, detrás de un libro, en un banco y en un caballete. Estudiamos, estudiamos toda la vida: tanto un colegial que pasa las noches en vela leyendo una cartilla, como un profesor sabio por experiencia. Porque con las mismas tablas asociamos no solo la toma de decisiones, sino también moverse, caminar, jugar a la pelota.
Si oponemos los cálculos matemáticos al pensamiento asociativo, ¿cuál es su peso en la vida humana? ¿Cómo fue el desarrollo del hombre, cuando no sabía contar? Utilizando el pensamiento asociativo, siendo capaz de interpolar y extrapolar, la experiencia acumulada de una persona. (Por cierto, recordemos la tesis de D. Mendeleev: La ciencia empieza cuando empiezan a contar.) Puedes preguntarle al lector: ¿Cuántas veces contaste hoy? Manejaste un auto, jugaste tenis, corriste al autobús, planeando tus acciones. ¿Te imaginas cuánto tendrías que calcular (¿y dónde conseguir el algoritmo?) para levantar el pie en la acera, sin pasar por la acera? No, no calculamos nada cada minuto, y esto es quizás lo principal en nuestra vida intelectual, incluso en la ciencia y los negocios. Los mecanismos de sensación, intuición, automatismo, que nosotros, incapaces de explicar, nos dirigimos al pensamiento subcortical, son de hecho mecanismos normales del pensamiento asociativo con la ayuda de tablas de base de conocimientos.
Y lo más importante, ¡lo hacemos rápido! Cómo no pensar, tratando de comprender y reproducir el desarrollo de la memoria figurativa, producto del crecimiento en el proceso de Desarrollo. Creemos que esto está bastante materializado y, por lo tanto, realizable artificialmente, sujeto a modelado y reproducción.
Formulemos ahora un principio actual suficiente para construir una red neuronal como un elemento de la IA:
1. Debe reconocerse que la base de la imitación de la neuroestructura del cerebro es el método de interpolación tabular.
2. Las tablas se llenan de acuerdo con algoritmos de cálculo conocidos, experimentalmente o por expertos.
3. La red neuronal proporciona un procesamiento de tablas de alta velocidad debido a la posibilidad de una paralelización similar a una avalancha.
4. Además, la red neuronal permite ingresar a la tabla con datos inexactos e incompletos, brindando una respuesta aproximada basada en el principio de similitud máxima o promedio.
5. La tarea de la imitación de la red neuronal del cerebro es transformar no la información inicial en sí, sino las evaluaciones de esta información, para reemplazar la información con valores de excitación del receptor hábilmente distribuidos entre tipos, tipos, parámetros, rangos de su cambio o valores individuales.
6. Las neuronas de la capa de salida de cada subestructura, por su excitación, indican las soluciones correspondientes. Al mismo tiempo, estas señales de excitación como información mediada inicial se pueden utilizar en el siguiente eslabón de la cadena lógica sin interferencia externa en el modo operativo.
3. Seguimiento del sistema bancario
Un ejemplo de la brillante aplicación de los mapas autoorganizados de Kohonen (SOM - Self-Organizing Map) se da en el estudio del sistema bancario ruso en 1999-2000.
El seguimiento se basa en una evaluación de calificación basada en la ejecución automática de un procedimiento: se muestra en la pantalla de la computadora de acuerdo con el vector multidimensional de los parámetros del banco. Se llama la atención sobre el hecho de que las tecnologías de redes neuronales permiten construir funciones visuales de muchas variables, como si se transformara un espacio multidimensional en una, dos o tres dimensiones. Para cada estudio individual de varios factores, es necesario construir su propio SOM. El pronóstico solo es posible sobre la base del análisis de la serie temporal de las estimaciones de SOM. También se necesitan nuevos SOM para extender la cadena de inferencias, con la conexión de datos del exterior, por ejemplo, de carácter político.
Este enfoque es sin duda efectivo y eficiente. Pero parece que, en comparación con el potencial de las neuroestructuras cerebrales, restringe el alcance y la valentía del pensamiento, no permite tirar de largas cadenas de premisa-consecuencia, combinar el análisis con un pronóstico, tener en cuenta rápidamente la situación actual e introducir nuevos factores y la experiencia de los expertos en consideración. Debemos estar de acuerdo en que el cerebro está sujeto a todo esto, y nuevamente nos dirigimos a sus estructuras, proponiendo un proyecto de software de sistema de monitoreo.
La estructura de la red neuronal y los métodos de aprendizaje. Las funciones lógicas que subyacen al seguimiento se basan principalmente en la conjunción de los valores lógicos de variables que reflejan los rangos de cambios en los parámetros o indicadores de los bancos.
Se presentan los siguientes indicadores:
* capital;
* activos equilibrados;
* activos líquidos;
* pasivos a la vista;
* depósitos de la población;
* índice de liquidez;
* recursos presupuestarios.
Puede ampliar el cuadro de mando:
* el volumen de inversiones en la era de una economía en auge;
* volumen de beneficio;
* ranking pasado y valor de migración;
* contribuciones al fondo de apoyo a la ciencia y la educación;
* deducciones fiscales;
* aportes al fondo de pensiones;
* Contribuciones a un fondo caritativo y cultural;
* participación en programas de la UNESCO, etc.
Una forma tan simple de una función lógica cuando se mueve al dominio de las variables reales indica la suficiencia de una red neuronal de una sola capa que contiene una capa de entrada de receptores y una capa de salida en la que se forman los resultados del monitoreo.
Al construir la capa de entrada, es necesario tener en cuenta no solo los indicadores actuales, sino también la dinámica de los cambios de calificación en períodos de tiempo pasados. La capa de salida debe reflejar no solo la calificación, sino también las recomendaciones de los expertos, así como otras decisiones y conclusiones.
El tipo más simple de entrenamiento es conveniente: construir una base de conocimiento, que corresponde al concepto de crear una red neuronal para la tarea: introducción directa de conexiones por parte del operador-investigador manualmente, desde los receptores hasta las neuronas de la capa de salida de acuerdo con la causa. Relaciones y efectos. Así, la red se crea ya entrenada.
Luego, la función de transferencia también será la más simple y se basará en la suma de los valores de excitación en la entrada de la neurona, multiplicados por el peso de la conexión:
Es más conveniente establecer el peso de los enlaces ra en comparación con el ajuste aproximado de todos los pesos iguales a uno, debido al posible deseo del operador o experto de tener en cuenta la influencia de varios indicadores en diversos grados.
El umbral h elimina conclusiones obviamente inaceptables, lo que simplifica el procesamiento posterior (por ejemplo, encontrar el promedio). El factor de reducción k se debe a las siguientes consideraciones.
El valor máximo de V puede llegar a n Para que el valor nominal esté en un rango aceptable, por ejemplo, en , los valores de excitación deben convertirse configurando k = Yn.
Los supuestos anteriores permiten introducir rápidamente cambios y aclaraciones por parte del operador - experto - usuario, desarrollar la red introduciendo nuevos factores y teniendo en cuenta la experiencia. Para hacer esto, basta con que el operador, haciendo clic con el mouse, seleccione el receptor y luego la neurona de la capa de salida, ¡y se establece la conexión! Solo queda asignar aproximadamente el peso de la conexión ingresada del rango.
Cabe hacer aquí una Nota Muy Importante (OVZ), referente a todo el material del libro y destinada a un lector muy atento.
Anteriormente, al considerar el entrenamiento, clasificamos claramente las situaciones de referencia iniciales, tomando la confiabilidad de cada componente igual a uno. Al realizar el seguimiento y el diseño de caminos dinámicos de excitación, también asumimos que los pesos de las conexiones son iguales a uno (o algún valor constante máximo). ¡Pero después de todo, el maestro puede obtener inmediatamente un grado adicional de libertad, teniendo en cuenta los factores en la medida y con los pesos que establece! Haremos la suposición de que diferentes factores afectan el resultado en diferentes grados, y forzaremos tal influencia en la etapa de entrenamiento.
Por ejemplo, se sabe que en vísperas de la guerra, la población compra jabón, fósforos y sal en grandes cantidades. Entonces, al observar este factor, es posible predecir el inminente inicio de la guerra.
Al crear una red neuronal para analizar eventos históricos o sociales, se deben identificar uno o más receptores cuya excitación corresponda a diferentes niveles de compras de jabón, sal y fósforos al mismo tiempo. La excitación de estos receptores debe transmitirse, influir (junto con otros factores) en el grado de excitación de la neurona de la capa de salida correspondiente al enunciado ¡Viene la guerra!
Sin embargo, la compra intensiva de jabón, fósforos y sal es una condición necesaria, pero no suficiente, para el estallido de la guerra. Puede ser testimonio, por ejemplo, de la rápida reactivación del turismo en la región de la Cordillera Principal del Cáucaso. Las palabras no son el significado de la lógica difusa, que permite tener en cuenta no la inmutabilidad de un evento, no una variable booleana sí - no, sino algún estado intermedio, indefinido, equilibrado del tipo "afecta, pero no así, directamente, que es necesario...". Por lo tanto, se supone que las conexiones (todas o algunas) que emanan de este receptor (datos) son iguales a algún valor esperado, menor que uno y corregido más tarde, lo que refleja el efecto de la excitación del receptor en la salida.
Por lo tanto, la compra simultánea de jabón, sal y fósforos se tiene en cuenta dos veces: el nivel de compra se mostrará en el grado de excitación de los receptores correspondientes y la naturaleza del efecto de la compra en la conclusión ¡Se acerca la guerra! - con la ayuda de pesos de conexiones sinápticas.
Acuerde que al construir redes de un solo nivel, este enfoque se sugiere y se implementa de manera extremadamente simple.
Estructura de pantalla de los receptores. Su parte principal es una ventana de desplazamiento, en la que puede ver y configurar el estado de la capa del receptor, que, por supuesto, no cabe en una pantalla estática.
La ventana de desplazamiento muestra los indicadores y sus valores estimados en el rango para los respectivos receptores. Estos son valores probabilísticos basados en la confiabilidad, la intuición y el juicio de expertos. Las estimaciones asumen la cobertura de múltiples receptores. Por ejemplo, una evaluación de que la equidad es 24, 34 o 42,000 u.m. es decir, sino más bien 24, puede conducir a una estimación aproximada de los valores de excitación establecidos de 0,6, 0,2 y 0,2 receptores correspondientes a los rangos (20 - 25], (30 - 35], (40 - 45). La pantalla muestra valores establecidos estáticamente, como calificaciones de mediciones anteriores, indicadores selectivos encontrados previamente e indicadores de condiciones políticas, sociales y económicas (su abundancia y desarrollo aún pueden requerir desplazamiento).
También debería mostrar el control de desplazamiento y el menú principal de acciones:
* transición a la pantalla de la capa de salida;
* procesamiento estadístico de resultados (implica la transición a la pantalla de salida);
* introducción de una nueva conexión;
* introducción de un nuevo receptor;
* introducción de una nueva neurona de capa de salida (involucra cambiar pantallas);
* introducción de un nuevo indicador, etc.
Estructura de pantalla de la capa de salida. La pantalla de la capa de salida (Fig. 8.3) muestra un sistema de rectángulos concéntricos (anidados) u otras formas planas que reflejan la distribución descendente de la clasificación. En el centro de la pantalla, unos puntos brillantes indican los bancos más exitosos o supuestas imágenes ideales. Cada elemento de la pantalla está rígidamente asociado con la neurona de la capa de salida. Como resultado de la monitorización, la neurona correspondiente al estándar puede excitarse al máximo, sin embargo, lo más probable es que se muestre un punto de la pantalla que no coincide con ningún estándar, que es intermedio o promedio.
Arroz. - 8.3. Pantalla de capa de salida
Por supuesto, se debe proporcionar un menú para la operación de la calificación promedio, la demostración de la categoría de éxito, la emisión de señales de advertencia, los textos de las conclusiones, las estrategias de desarrollo recomendadas, el almacenamiento de datos para un desarrollo posterior, etc.
Entrenamiento de redes neuronales. Para entrenar la red neuronal en base a valoraciones de expertos, es necesario establecer los rangos de parámetros aceptables, que nos permitan considerar al banco como idealmente exitoso, teniendo la máxima calificación. Al fijar varios puntos, cuyas coordenadas (conjuntos de valores de parámetros) satisfacen los valores de calificación permitidos para bancos conocidos o supuestos (teniendo en cuenta las posibles opciones), podemos obtener varios representantes ideales. Las neuronas correspondientes a ellos, es decir. los elementos de la pantalla de la capa de salida se seleccionan arbitrariamente, extendiéndose por el área de la pantalla. Es deseable que los estándares con una calificación alta se ubiquen más cerca del centro.
Luego proceden al mismo llenado del rectángulo que lo encierra, con base en la siguiente categoría de calificación, y así sucesivamente. a los bancos externos.
Para llevar a cabo dicho trabajo, los expertos forman preliminarmente una mesa (Tabla 1).
Las neuronas que representan los bancos en la pantalla corresponden a los valores de su excitación: calificaciones.
Metodología de seguimiento. El sistema entrenado, que llega a disposición del usuario después de una experiencia altamente calificada de economistas y políticos, está listo para su uso en el marco de la tecnología CASE CASE - Ingeniería de software asistida por computadora.
Tabla 1 - Evaluaciones de expertos para el entrenamiento de redes neuronales
En este caso, el usuario ejerce su derecho a capacitación adicional, aclaraciones (por ejemplo, pesos de conexiones, para fortalecer o debilitar la influencia de ciertos indicadores basados en su propia experiencia), la introducción de indicadores adicionales para el experimento bajo su propio riesgo. , etc
Supongamos que el usuario está investigando la situación en torno a Invest Round Trip Bank. Naturalmente, no tiene ninguna información satisfactoria sobre la conveniencia de sus propias inversiones y, por lo tanto, procede a la recopilación escrupulosa de datos, como resultado de lo cual recibe características aproximadas, probables y contradictorias para el modelado.
Usando la pantalla del receptor, el usuario establece sus valores de excitación en función de datos bastante confiables, pero a veces teniendo en cuenta las opciones o - o (parcialmente excitando diferentes receptores), a veces por capricho, a veces simplemente omitiendo indicadores. Todavía no se conocen indicadores como la calificación pasada y la migración, pero se espera que el resultado se utilice en el futuro.
Después de ingresar datos en la pantalla de la capa de salida, un punto brillante cerca de la región exterior atestigua elocuentemente la protección del derecho civil de elección no violenta de la decisión sobre la conveniencia de invertir el capital justamente acumulado.
Las coordenadas de este punto en la pantalla están determinadas por la conocida fórmula para encontrar el promedio de las coordenadas de las neuronas resaltadas de aquellos bancos que están cerca del banco controlado, y por las magnitudes de su excitación. Pero de acuerdo con las mismas fórmulas, en base a las calificaciones de los bancos destacados, ¡se encuentra la calificación del banco en estudio!
El usuario puede decidir complementar la base de conocimientos y, en consecuencia, la red neuronal con información sobre el nuevo banco, lo cual es recomendable si el consejo de expertos critica el resultado y, por lo tanto, señala un error de la red neuronal. Solo usa la opción. Agregue, como resultado de lo cual se inicia un diálogo entre la computadora y el usuario:
- ¿Quieres cambiar la calificación? - Sí.
- Nuevo valor de calificación --...
- ¡Salvar!
Luego, la neurona de la capa de salida con las coordenadas encontradas se asigna al nuevo banco. Sus conexiones se forman con aquellos receptores que se excitaron al ingresar información sobre el banco. Se supone que el peso de cada conexión es igual al valor de excitación de la neurona receptora correspondiente ingresada por el usuario. Ahora la base de conocimientos se ha complementado de la misma manera que la lista de instalaciones de baterías de artillería avistadas después de alcanzar otro objetivo.
Sin embargo, un cambio forzado significativo en la calificación puede requerir mover el punto resaltado al área de bancos con el nivel de calificación correspondiente, es decir. es necesario asignar otra neurona de la capa de salida a este banco, en otra zona de la pantalla. Esto también se establece como resultado del diálogo de la computadora con el usuario.
Corrección y desarrollo. Anteriormente, ya hemos mencionado la necesidad y la posibilidad de perfeccionamiento y desarrollo constantes de la red neuronal. Puede cambiar la idea del avance de un banco de referencia (real o ideal) y complementar la base de conocimiento, es decir. esta red neuronal. Puede ajustar los pesos de enlace como una medida de la influencia de indicadores individuales en el resultado de salida.
Puede ingresar nuevos indicadores con sus pesos, considerar nuevas soluciones y establecer el grado de influencia sobre ellos por los mismos o nuevos indicadores. Es posible adaptar la red neuronal para resolver problemas relacionados, teniendo en cuenta la influencia de los indicadores individuales en la migración de los bancos (transición de un nivel de calificación a otro), etc.
Finalmente, al comprar este producto de software con una interfaz amigable y un excelente servicio, con un conjunto desarrollado de funciones de conversión de redes neuronales, puede rehacerlo para una tarea completamente diferente, por ejemplo, para un emocionante juego de ruleta ferroviaria, que pretendemos detenerse a continuación.
En conclusión, notamos que en la economía y los negocios, así como en la gestión de objetos complejos, prevalecen los sistemas de toma de decisiones, donde cada situación se forma sobre la base de un número constante de factores. Cada factor está representado por una variante o valor de un conjunto exhaustivo, es decir cada situación está representada por una conjunción, en la que necesariamente participan afirmaciones sobre todos los factores por los que se forma la red neuronal. Entonces todas las conjunciones (situaciones) tienen el mismo número de enunciados. Si en este caso dos situaciones diferentes conducen a soluciones diferentes, la red neuronal correspondiente es perfecta. El atractivo de tales redes neuronales radica en su reducibilidad a redes de una sola capa. Si multiplicamos soluciones (ver Sec. 5.2), entonces obtenemos una red neuronal perfecta (sin retroalimentación).
La tarea de esta sección puede reducirse a la construcción de una red neuronal perfecta, Sec. 6.2, así como, por ejemplo, la tarea de evaluar el riesgo país, etc.
Conclusión
La distribución de los valores de excitación de las neuronas en la capa de salida, y más a menudo la neurona con el valor máximo de excitación, permite establecer una correspondencia entre la combinación y los valores de excitación en la capa de entrada (imagen en la retina ) y la respuesta resultante (qué es). Por lo tanto, esta dependencia determina la posibilidad de una inferencia lógica de la forma "si - entonces". Control, la formación de esta dependencia se lleva a cabo por los pesos de las conexiones sinápticas de las neuronas, que afectan la dirección de propagación de la excitación de las neuronas en la red, conduciendo en la etapa de entrenamiento a las neuronas "necesarias" de la capa de salida, es decir, sirven para vincular y recordar las relaciones "premisa-consecuencia". La conexión de las subestructuras de la red neuronal permite obtener " largas” cadenas lógicas basadas en tales relaciones.
De ello se deduce que la red opera en dos modos: en modo de entrenamiento y en modo de reconocimiento (modo de trabajo).
En el modo de aprendizaje, se realiza la formación de cadenas lógicas.
En el modo de reconocimiento, la red neuronal, en base a la imagen presentada, determina con alta certeza a qué tipo pertenece, qué acciones se deben tomar, etc.
Se cree que hay hasta 100 mil millones de neuronas en el cerebro humano. Pero ahora no nos interesa cómo se ordena una neurona, en la que hay hasta 240 reacciones químicas. Nos interesa cómo funciona la neurona a nivel lógico, cómo realiza funciones lógicas. La implementación de solo estas funciones debe convertirse en la base y el medio de la inteligencia artificial. Al incorporar estas funciones lógicas, estamos dispuestos a violar las leyes básicas de la física, como la ley de conservación de la energía. Después de todo, no contamos con el modelado físico, sino con una computadora accesible y universal.
Así pues, nos estamos centrando en el uso "(directo" de las redes neuronales en tareas de inteligencia artificial. Sin embargo, su aplicación se extiende también a la resolución de otras tareas. Para ello, se construyen modelos de redes neuronales con una estructura orientada a esta tarea), se utiliza un sistema especial de conexiones de elementos de tipo neural, un cierto tipo de función de transferencia (a menudo se usan las llamadas conexiones sigmoyl, basadas en la participación del exponente en la formación de la función de transferencia), especialmente seleccionado y dinámicamente pesos refinados. En este caso, se utilizan las propiedades de convergencia de los valores de excitación de las neuronas, la autooptimización. Cuando se suministra un vector de entrada de excitaciones después de un cierto número de ciclos de la red neuronal, los valores de excitación de las neuronas de la capa de salida (en algunos modelos, todas las neuronas de la capa de entrada son neuronas de la capa de salida y no no son otros) convergen a ciertos valores. Pueden indicar, por ejemplo, qué estándar es más parecido a "ruidoso". imagen de entrada no válida, o lo que sea. cómo encontrar una solución a un problema. Por ejemplo, la conocida red de Hopfield. aunque con limitaciones, puede resolver el problema del viajante de comercio, un problema de complejidad exponencial. La red de Hamming implementa con éxito la memoria asociativa. Redes de Kohonen (mapas de Kohonen), añadido el 27/06/2011
La tarea de análisis de la actividad empresarial, factores que influyen en la toma de decisiones. Tecnologías de la información modernas y redes neuronales: principios de su trabajo. Estudio del uso de redes neuronales en los problemas de previsión de situaciones financieras y toma de decisiones.
tesis, agregada el 06/11/2011
Descripción del proceso tecnológico de llenado de papel. Diseño de máquinas de papel. Justificación del uso de redes neuronales en el control de la formación de una red de papel. Modelo matemático de una neurona. Modelado de dos estructuras de redes neuronales.
documento final, agregado el 15/10/2012
Formas de aplicar tecnologías de redes neuronales en sistemas de detección de intrusos. Sistemas expertos para la detección de ataques a la red. Redes artificiales, algoritmos genéticos. Ventajas y desventajas de los sistemas de detección de intrusos basados en redes neuronales.
prueba, agregada el 30/11/2015
El concepto de inteligencia artificial como las propiedades de los sistemas automáticos para asumir funciones individuales de la inteligencia humana. Sistemas expertos en el campo de la medicina. Diferentes enfoques para construir sistemas de inteligencia artificial. Creación de redes neuronales.
presentación, agregada el 28/05/2015
Estudio de la tarea y las perspectivas del uso de redes neuronales en funciones radiales para predecir los principales indicadores económicos: producto interno bruto, ingreso nacional de Ucrania e índice de precios al consumidor. Evaluación de resultados.
documento final, agregado el 14/12/2014
El concepto y las propiedades de las redes neuronales artificiales, su similitud funcional con el cerebro humano, el principio de su trabajo, áreas de uso. Sistema experto y fiabilidad de las redes neuronales. Modelo de una neurona artificial con función de activación.
resumen, añadido el 16/03/2011
Esencia y funciones de las redes neuronales artificiales (RNA), su clasificación. Elementos estructurales de una neurona artificial. Diferencias entre ANN y máquinas de arquitectura von Neumann. Construcción y capacitación de redes de datos, áreas y prospectos para su aplicación.
presentación, añadido el 14/10/2013
El uso de neurocomputadoras en el mercado financiero ruso. Pronóstico de series de tiempo basado en métodos de procesamiento de redes neuronales. Determinación de tasas de bonos y acciones de empresas. Aplicación de las redes neuronales a los problemas de análisis de la actividad de intercambio.
documento final, agregado el 28/05/2009
La historia de la creación y las direcciones principales en el modelado de inteligencia artificial. Problemas de enseñanza de la percepción y el reconocimiento visual. Desarrollo de elementos de inteligencia de robots. Investigación en el campo de las redes neuronales. Principio de retroalimentación de Wiener.
CDU 004.38.032.26
O. V. Konyukhova, K. S. Lapochkina
O. V. KONUKHOVA, K. S. LAPOCHKINA
LA APLICACIÓN DE LAS REDES NEURONALES EN LA ECONOMÍA Y LA RELEVANCIA DE SU USO EN LA ELABORACIÓN DE UNA PREVISIÓN PRESUPUESTARIA A CORTO PLAZO
APLICACIÓN DE LAS REDES NEURONALES EN LA ECONOMÍA Y URGENCIA DE SU UTILIZACIÓN MEDIANTE LA ELABORACIÓN DE UNA PREVISIÓN A CORTO PLAZO DEL PRESUPUESTO
Este artículo describe la aplicación de las redes neuronales en la economía. Se considera el proceso de previsión del presupuesto de la Federación Rusa y la relevancia del uso de redes neuronales para la elaboración de presupuestos a corto plazo.
Palabras clave: economía, presupuesto de la Federación Rusa, previsión presupuestaria, redes neuronales, algoritmos genéticos.
En este artículo se describe la aplicación de las redes neuronales en la economía. Se considera el proceso de la previsión del presupuesto de la Federación Rusa y la urgencia de la aplicación de las redes neuronales para la composición del presupuesto a corto plazo.
Palabras clave: economía, presupuesto de la Federación Rusa, previsión presupuestaria, redes neuronales, algoritmos genéticos.
4) agrupación automática de objetos.
Uno de los intentos interesantes de crear un mecanismo para la gestión racional de una economía deprimida pertenece al cibernético inglés Stafford Beer. Propuso los ampliamente conocidos principios de control, que se basan en mecanismos neurofisiológicos. Él consideraba que los modelos de sistemas de producción eran relaciones muy complejas entre insumos (flujos de recursos), elementos internos e invisibles y productos (resultados). Los índices bastante generalizados sirvieron como entradas para los modelos, la mayoría de los cuales reflejaron rápidamente el volumen de producción de una producción en particular, la necesidad de recursos y la productividad. Las decisiones propuestas para el funcionamiento eficaz de dichos sistemas se tomaron después de encontrar y discutir todas las opciones posibles en una situación dada. La mejor decisión se tomó por mayoría de votos entre los gerentes y los expertos que participaron en la discusión. Para ello se preveía en el sistema una sala situacional dotada de los medios técnicos adecuados. El enfoque propuesto por S. Beer para crear un sistema de gestión resultó ser efectivo para administrar no solo grandes asociaciones industriales, como una empresa siderúrgica, sino también la economía chilena de los años 70.
Un cibernético ucraniano utilizó principios similares en el método de contabilidad grupal de argumentos (MGUA) para modelar la economía de la próspera Inglaterra. Junto con economistas (Parks et al.), quienes propusieron más de doscientas variables independientes que afectan el ingreso bruto, identificó varios (cinco o seis) factores principales que determinan el valor de la variable de salida con un alto grado de precisión. Sobre la base de estos modelos, se desarrollaron varias opciones para influir en la economía con el objetivo de aumentar el crecimiento económico en diversas tasas de ahorro, inflación y niveles de desempleo.
El método propuesto de contabilidad grupal de argumentos se basa en el principio de autoorganización de modelos de sistemas complejos, en particular económicos, y le permite determinar dependencias ocultas complejas en datos que no son detectados por métodos estadísticos estándar. Este método fue utilizado con éxito por A. Ivakhnenko para evaluar el estado de la economía y pronosticar su desarrollo en países como EE. UU., Gran Bretaña, Bulgaria y Alemania. utilizó un gran número de variables independientes (de cincuenta a doscientas), describiendo el estado de la economía y afectando el ingreso bruto en los países bajo estudio. A partir del análisis de estas variables mediante el método de contabilidad grupal de argumentos, se identificaron los principales factores significativos que determinan el valor de la variable de salida (ingresos brutos) con un alto grado de precisión.
La investigación en esta dirección ha tenido un efecto estimulante en el desarrollo de métodos de redes neuronales, que se han utilizado intensamente recientemente debido a su capacidad para extraer experiencia y conocimiento de una pequeña secuencia clasificada. Después del entrenamiento en tales secuencias, las redes neuronales son capaces de resolver tareas complejas no formalizables de la misma manera que lo hacen los expertos en base a su conocimiento e intuición. Estas ventajas se vuelven especialmente significativas en una economía en transición, que se caracteriza por tasas de desarrollo desiguales, diferentes tasas de inflación, corta duración, así como incompletitud e inconsistencia del conocimiento sobre los fenómenos económicos en curso.
Ampliamente conocido es el trabajo que aplicó con éxito los principios de autoorganización de modelos de sistemas económicos complejos para construir una red neuronal en la resolución de problemas de análisis y modelado del desarrollo de la economía de Mordovia y la región de Penza.
Un ejemplo típico de la aplicación exitosa de la computación neuronal en el sector financiero es la gestión del riesgo crediticio. Como saben, antes de otorgar un préstamo, los bancos realizan cálculos estadísticos complejos sobre la confiabilidad financiera del prestatario para evaluar la probabilidad de sus propias pérdidas debido al reembolso intempestivo de los fondos. Dichos cálculos generalmente se basan en una evaluación del historial crediticio, la dinámica del desarrollo de la empresa, la estabilidad de sus principales indicadores financieros y muchos otros factores. Un conocido banco estadounidense probó el método de computación neuronal y llegó a la conclusión de que la misma tarea, basada en cálculos de este tipo ya realizados, se resuelve de forma más rápida y precisa. Por ejemplo, en un caso de evaluación de 100 000 cuentas bancarias, un nuevo sistema construido sobre la base de la computación neuronal identificó a más del 90 % de los morosos potenciales.
Otra área muy importante de aplicación de la computación neuronal en el sector financiero es la predicción de la situación en el mercado de valores. El enfoque estándar para este problema se basa en un conjunto rígido de "reglas del juego", que eventualmente pierden su efectividad debido a los cambios en las condiciones comerciales en la bolsa de valores. Además, los sistemas construidos sobre la base de este enfoque son demasiado lentos para situaciones que requieren una toma de decisiones instantánea. Es por ello que las principales empresas japonesas que operan en el mercado de valores decidieron aplicar el método de computación neuronal. Se ingresó a un sistema típico basado en redes neuronales con información total de 33 años de actividad comercial de varias organizaciones, incluida la facturación, el precio de las acciones anteriores, los niveles de ingresos, etc. Autoaprendizaje en ejemplos reales, el sistema de redes neuronales mostró mayor precisión de predicción y mejor rendimiento: en comparación con el enfoque estadístico dio una mejora general en el rendimiento en un 19%.
Una de las técnicas de computación neuronal más avanzadas son los algoritmos genéticos que imitan la evolución de los organismos vivos. Por lo tanto, se pueden utilizar como un optimizador de parámetros de redes neuronales. Se desarrolló e instaló un sistema similar para predecir el rendimiento de los contratos de valores a largo plazo en una estación de trabajo Sun en Hill Samuel Investment Management. Al modelar varias estrategias comerciales, logró una precisión del 57 % en la predicción de la dirección del mercado. TSB General Insurance (Newport) utiliza una metodología similar para predecir el nivel de riesgo en los seguros de préstamos privados. Esta red neuronal es de autoaprendizaje sobre datos estadísticos sobre el estado del desempleo en el país.
A pesar de que el mercado financiero en Rusia aún no se ha estabilizado y, argumentando desde un punto de vista matemático, su modelo está cambiando, lo que está relacionado, por un lado, con la expectativa de una reducción gradual del mercado de valores y una aumento de la participación en el mercado de valores asociado al flujo de inversiones, tanto de capital nacional como extranjero, y por otro lado, con la inestabilidad del curso político, aún se puede notar el surgimiento de empresas que necesitan utilizar métodos estadísticos distintos a los tradicionales, así como la aparición en el mercado de productos de software y tecnología informática de paquetes neuronales para emular redes neuronales en ordenadores de la serie IBM e incluso neuroplacas especializadas basadas en neurochips personalizados.
En particular, uno de los primeros neuroordenadores potentes para uso financiero, CNAPS PC/128, basado en 4 neuroBIS de Alaptive Solutions, ya está funcionando con éxito en Rusia. Según la empresa Tora Center, la cantidad de organizaciones que utilizan redes neuronales para resolver sus problemas ya incluye al Banco Central, el Ministerio de Emergencias, la Inspección de Hacienda, más de 30 bancos y más de 60 empresas financieras. Algunas de estas organizaciones ya han publicado los resultados de sus actividades en el campo del uso de la neurocomputación.
De lo anterior se desprende que en la actualidad el uso de redes neuronales en la elaboración de un pronóstico presupuestario a corto plazo es un tema candente de investigación.
En conclusión, cabe señalar que el uso de redes neuronales en todas las áreas de la actividad humana, incluso en el campo de las aplicaciones financieras, está en aumento, en parte por necesidad y por las amplias oportunidades para algunos, por el prestigio para otros y por interesantes aplicaciones de terceros.
BIBLIOGRAFÍA
1. Ley Federal de la Federación Rusa del 1 de enero de 2001 (modificada el 1 de enero de 2001) “Sobre Previsión y Programas Estatales para el Desarrollo Social y Económico de la Federación Rusa” [Texto]
2. Beer S. El cerebro de la firma [Texto] / S. Beer. - M.: Radio y comunicación, 1993. - 524 p.
3. Galushkin, neurocomputadores en la actividad financiera [Texto] / . - Novosibirsk: Nauka, 2002. - 215 p.
4., Muller de modelos predictivos [Texto] /, - Kyiv: Técnica, 1985. - 225 p.
5. Kleshchinsky, métodos de pronóstico en el proceso presupuestario [Texto] / // Electronic Journal of Corporate Finance, 2011. - No. 3 (19) - P. 71 - 78.
6. Rutkovskaya M., Plinskiy L. Redes neuronales, algoritmos genéticos y sistemas difusos: Per. del polaco [Texto] / M. Rutkovskaya, L. Plinsky -: Hot line - Telecom, años 20.
7. , Soluciones de Kostyunin sobre redes neuronales de complejidad óptima [Texto] / , // Automatización y tecnologías modernas, 1998. - No. 4. - P. 38-43.
Institución Educativa Estatal Federal de Educación Profesional Superior "Universidad Estatal - Complejo Educativo, de Investigación y Producción", Orel
Candidato a Ciencias Técnicas, Profesor Asociado, Profesor Asociado del Departamento de Sistemas de Información
Correo electrónico: ****@***ru
Lapochkin kristina sergeevna
Institución Educativa Estatal Federal de Educación Profesional Superior "Universidad Estatal - Complejo Educativo, de Investigación y Producción", Orel
Estudiante del grupo 11-PI(m)
Las redes neuronales difusas (fuzzy-neural networks) llevan a cabo conclusiones basadas en el aparato de la lógica difusa, sin embargo, los parámetros de las funciones de pertenencia se ajustan utilizando algoritmos de aprendizaje de redes neuronales (NN). Por lo tanto, para seleccionar los parámetros de dichas redes, utilizamos el método de retropropagación, que originalmente se propuso para entrenar un perceptrón multicapa. Para ello, el módulo de control difuso se presenta en forma de red multicapa. Una red neuronal difusa generalmente consta de cuatro capas: una capa de fuzzificación para variables de entrada, una capa para agregar valores de activación de condiciones, una capa para agregar reglas difusas y una capa de salida. Las arquitecturas fuzzy NN de los tipos ANFIS y TSK son actualmente las más utilizadas. Se demuestra que tales redes son aproximadores universales. Los algoritmos de aprendizaje rápido y la interpretabilidad del conocimiento acumulado: estos factores han convertido a las redes neuronales difusas en una de las herramientas informáticas blandas más prometedoras y efectivas de la actualidad.
Redes neuronales en economía
El área de la IA que ha encontrado la aplicación más amplia son las redes neuronales. Su característica principal es la capacidad de autoaprendizaje sobre ejemplos específicos. Se prefieren las redes neuronales donde hay una gran cantidad de datos de entrada en los que se ocultan patrones. Es recomendable utilizar métodos de redes neuronales en problemas con información incompleta o "ruidosa", así como en aquellos en los que la solución se puede encontrar de forma intuitiva. Las redes neuronales se utilizan para predecir mercados, optimizar los flujos de efectivo y productos básicos, analizar y resumir encuestas sociológicas, predecir la dinámica de las calificaciones políticas, optimizar el proceso de producción, diagnósticos integrales de la calidad del producto y mucho, mucho más. Las redes neuronales se utilizan cada vez más en aplicaciones comerciales reales. En algunas áreas, como la detección de fraudes y la evaluación de riesgos, se han convertido en líderes indiscutibles entre los métodos utilizados. Su uso en sistemas de pronóstico y sistemas de investigación de mercados está en constante crecimiento. Dado que los sistemas económicos, financieros y sociales son muy complejos y son el resultado de las acciones y reacciones de varias personas, es muy difícil (si no imposible) crear un modelo matemático completo, teniendo en cuenta todas las acciones y reacciones posibles. Es casi imposible aproximar con precisión un modelo basado en parámetros tradicionales como la maximización de la utilidad o la maximización de las ganancias. En sistemas de esta complejidad, es natural y más eficiente utilizar modelos que imiten directamente el comportamiento de la sociedad y la economía. Y esto es exactamente lo que puede ofrecer la metodología de las redes neuronales.
Las siguientes son las áreas en las que se ha demostrado en la práctica la efectividad del uso de redes neuronales:
Para transacciones financieras:
- · Predicción del comportamiento del cliente.
- · Pronóstico y evaluación de riesgos de la próxima transacción.
- · Predecir posibles actividades fraudulentas.
- · Previsión de saldos en cuentas bancarias corresponsales.
- · Previsión de flujo de caja, volúmenes de capital de trabajo.
- · Previsión de parámetros económicos e índices bursátiles.
Para planificar el trabajo de la empresa:
- · Proyección de volúmenes de ventas.
- · Pronóstico de la utilización de la capacidad.
- · Previsión de la demanda de nuevos productos.
Para empresas: análisis y soporte de decisiones:
- · Identificación de tendencias, correlaciones, patrones y excepciones en grandes cantidades de datos.
- · Análisis del trabajo de las sucursales de la empresa.
- · Análisis comparativo de empresas competidoras.
Otras aplicaciones:
- · Valoración de inmuebles.
- · Control de calidad de los productos.
- · Los sistemas del seguimiento del estado de la maquinaria.
- · Diseño y optimización de redes de comunicación, redes de suministro eléctrico.
- · Previsión del consumo energético.
- · Reconocimiento de caracteres escritos a mano, incl. reconocimiento automático y autenticación de firma.
- · Reconocimiento y procesamiento de señales de video y audio.
Las redes neuronales también se pueden utilizar en otras tareas. Las principales condiciones predeterminadas para su uso son la disponibilidad de "datos históricos", con los cuales la red neuronal puede aprender, así como la imposibilidad o ineficiencia de utilizar otros métodos más formales. El Consejo de Expertos Independientes para el Análisis Estratégico de Asuntos de Política Exterior e Interior del Consejo de la Federación, el Instituto de Investigación de Inteligencia Artificial, presentó el proyecto "Tecnología de Nueva Generación Basada en Computación Subdeterminada y su Uso para Desarrollar un Modelo Experimental de la Macroeconomía Rusa" . Se hizo posible calcular el resultado de cualquier acción o propuesta con respecto al presupuesto del país durante muchos años por venir. El sistema le permite ver cómo cambiará el lado de los ingresos, el déficit presupuestario, el volumen de producción industrial en respuesta a, digamos, un aumento en los impuestos. También puede ver cuánto dinero salió del presupuesto el año pasado: una máquina electrónica, según los científicos, puede hacer frente fácilmente a esa tarea. Ni siquiera tendrá que explicar el concepto de "efectivo negro". También puedes resolver el problema inverso. Por ejemplo, ¿qué se debe hacer para que para 2020 el volumen de producción aumente o, digamos, al menos no disminuya? La máquina indicará los límites inferior y superior de los valores en ambos casos para el presupuesto de dinero dispensado para todos los parámetros que influyen en la producción de una forma u otra. Además, es posible conocer, no por un horóscopo y sin la ayuda de magos, una posible secuencia de momentos "críticos" y "exitosos" en el desarrollo de la economía del país con datos iniciales dados. Los desarrolladores del proyecto hasta ahora han creado solo un modelo de demostración que cubre alrededor de 300 parámetros y el período de 1990 a 1999. Pero para el funcionamiento normal, se requieren al menos 1000 parámetros. Y tal trabajo puede llevarse a cabo si se asignan fondos para ello. Es necesario llevar a cabo mucho trabajo aplicado, se necesita investigación fundamental sobre los dos componentes principales del proyecto: matemático y económico. Aquí se necesita un apoyo material estatal serio. La introducción del modelo informático actual de macroeconomía y el presupuesto estatal de la Federación Rusa automatizará la preparación de los parámetros iniciales del presupuesto estatal del próximo año, la aprobación de la versión final para aprobación en el parlamento, apoyo, evaluación y control. de la ejecución presupuestaria en todas sus etapas. El interés por las redes neuronales artificiales en Rusia ha crecido enormemente en los últimos años. La capacidad de aprender rápidamente y la confiabilidad de las conclusiones hace posible recomendar los sistemas expertos de redes neuronales como una de las herramientas esenciales en muchos aspectos de los negocios modernos. Las redes neuronales tienen una gran ventaja sobre la forma tradicional de generalizar el conocimiento de los expertos humanos, que requiere mucho trabajo y más tiempo. Las tecnologías de redes neuronales son aplicables en casi cualquier área, y en tareas como la previsión de cotizaciones de acciones y tipos de cambio, ya se han convertido en una herramienta familiar y ampliamente utilizada. La penetración generalizada de las tecnologías de redes neuronales en los negocios modernos es solo cuestión de tiempo. La introducción de nuevas tecnologías intensivas en ciencia es un proceso complejo, pero la práctica demuestra que las inversiones no solo rinden frutos y generan beneficios, sino que también brindan beneficios tangibles a quienes las utilizan. La aplicación de las redes neuronales en las finanzas se basa en un supuesto fundamental: la sustitución de la predicción por el reconocimiento. En general, la red neuronal no predice el futuro, sino que "reconoce" la situación encontrada anteriormente en el estado actual del mercado y reproduce la reacción del mercado posterior.
El mercado financiero es bastante inercial, tiene su propia "reacción lenta" específica, sabiendo cuál puede calcular con bastante precisión la situación futura. Y qué tan preciso: depende de las condiciones del mercado y las calificaciones del operador. Por lo tanto, es ingenuo creer que la red neuronal predecirá automáticamente las tasas de los principales indicadores: la moneda nacional o, por ejemplo, los metales preciosos en mercados inestables. Pero en cualquier situación de mercado, existen instrumentos que mantienen la estabilidad. Por ejemplo, cuando el dólar salta, se trata de futuros "distantes", cuya reacción se prolonga durante varios días y es predecible. Por cierto, durante los períodos de turbulencia del mercado, los jugadores suelen entrar en pánico, lo que aumenta las ventajas del propietario de una buena herramienta analítica. Cientos de empresas de fama mundial, así como pequeñas empresas emergentes, están trabajando actualmente en la creación de redes neuronales para diversos propósitos. El mercado mundial ofrece más de cien paquetes de redes neuronales, en su mayoría estadounidenses. El tamaño total del mercado de redes neuronales superaba los 10.000 millones de dólares en 2005. Y, prácticamente, todos los desarrolladores de paquetes analíticos tradicionales hoy buscan incluir redes neuronales en las nuevas versiones de sus programas. En los EE. UU., las redes neuronales se utilizan en los sistemas analíticos de todos los bancos importantes. Solo la venta del paquete de redes neuronales "Brain Maker Pro" es comparable a las ventas del paquete de análisis técnico más popular de MetaStock (más de 20 000 copias de Brain Maker Pro vendidas en EE. UU.).
Paquete bien probado "The AI Trilogy". ("Trilogía de Inteligencia Artificial") de la empresa estadounidense "Ward SystemsGroup". Este es un conjunto de tres programas, cada uno de los cuales se puede utilizar tanto de forma independiente como en combinación con los demás. Entonces, el programa "NeuroShell II" es un conjunto de 16 tipos de redes neuronales, "NeuroWindows" es una biblioteca de redes neuronales con textos fuente, "GeneHunter" es un programa de optimización genética. Juntos, forman un poderoso "constructor" que le permite construir sistemas analíticos de cualquier complejidad. "The AI Trilogy" en el mercado estadounidense tiene una gran demanda. El paquete está instalado en los 150 bancos más grandes de EE. UU. Ha ganado repetidamente concursos prestigiosos de publicaciones financieras populares y ayuda a administrar varios miles de millones de dólares de capital. Du Pont (el Instituto de Normas de EE. UU. y el FBI) considera que la "Trilogía de IA" es la mejor para resolver varios problemas. Un hecho poco conocido interesante y significativo es que los componentes clave de este paquete fueron escritos por programadores rusos. El paquete debe su aparición a un grupo de desarrolladores de una pequeña empresa de Moscú "Neuroproekt" bajo la dirección del profesor Persiansev.
Lleva más de tres años cumpliendo con los pedidos de Ward Systems Group y ha encontrado soluciones exitosas. Se puede decir que los programas rusos manejan las finanzas de Estados Unidos y las tareas del FBI. ¿Qué tan útil puede ser el paquete para los financistas? ¿Podrá funcionar en nuestro mercado impredecible, donde una decisión del Banco Central puede volcar el mercado instantáneamente? Anticipándose a estas preguntas, los propietarios del paquete ofrecen un servicio de consultoría especial. Se concluye un acuerdo especial con un banco cuyos analistas no creen en la previsibilidad de nuestro mercado. Dentro de un período determinado: dos semanas, un mes o más, por una tarifa nominal, el banco recibe diariamente pronósticos para mañana (o una semana antes) sobre las cotizaciones de instrumentos financieros específicos. Si el pronóstico demuestra consistentemente una precisión aceptable, entonces el banco se compromete a comprar el complejo analítico junto con la configuración. Y no hubo un solo caso en que el cliente se negara a comprar. Un caso indicativo e impresionante tuvo lugar entre las elecciones cuando uno de los principales bancos realizó una prueba similar del paquete. Las cotizaciones de los valores bailaban, los políticos bajaban y subían, pero todas las noches el banco recibía un pronóstico con un conjunto de precios de mañana (mini - maxi - media ponderada - cierre) para dieciséis valores GKO. En menos de dos semanas, el banco firmó un acuerdo para el suministro de un complejo analítico capaz de mantener el rendimiento incluso en situaciones tan turbulentas e impredecibles.
- · Características ricas. Las redes neuronales son una técnica de modelado excepcionalmente poderosa que puede reproducir dependencias extremadamente complejas. En particular, las redes neuronales son de naturaleza no lineal. Durante muchos años, el modelado lineal ha sido la técnica de modelado de referencia en la mayoría de los campos debido a sus procedimientos de optimización bien establecidos. En problemas donde la aproximación lineal no es satisfactoria (y hay bastantes), los modelos lineales funcionan mal. Además, las redes neuronales hacen frente a la "maldición de la dimensionalidad", que no permite modelar dependencias lineales en el caso de un gran número de variables.
- · Fácil de usar. Las redes neuronales aprenden de los ejemplos. Un usuario de red neuronal selecciona datos representativos y luego ejecuta un algoritmo de aprendizaje que aprende automáticamente la estructura de los datos. En este caso, por supuesto, se requiere que el usuario tenga algún tipo de conocimiento heurístico sobre cómo seleccionar y preparar datos, elegir la arquitectura de red deseada e interpretar los resultados, sin embargo, el nivel de conocimiento requerido para la aplicación exitosa de redes neuronales es mucho más modesto que, por ejemplo, utilizar métodos estadísticos tradicionales.
Las redes neuronales son intuitivamente atractivas porque se basan en un modelo biológico primitivo de los sistemas nerviosos. En el futuro, el desarrollo de tales modelos neurobiológicos puede conducir a la creación de computadoras verdaderamente pensantes. Mientras tanto, las redes neuronales ya "simples", que son construidas por el sistema ST Neural Networks, son un arma poderosa en el arsenal de un especialista en estadística aplicada.